Deploy trained models
editDeploy trained models
editIf you want to perform natural language processing tasks in your cluster, you must deploy an appropriate trained model. There is tooling support in Eland and Kibana to help you prepare and manage models.
Select a trained model
editPer the Overview, there are multiple ways that you can use NLP features within the Elastic Stack. After you determine which type of NLP task you want to perform, you must choose an appropriate trained model.
The simplest method is to use a model that has already been fine-tuned for the type of analysis that you want to perform. For example, there are models and data sets available for specific NLP tasks on Hugging Face. These instructions assume you’re using one of those models and do not describe how to create new models. For the current list of supported model architectures, refer to Compatible third party models.
If you choose to perform language identification by using the lang_ident_model_1 that is
provided in the cluster, no further steps are required to import or deploy the
model. You can skip to using the model in
ingestion pipelines.
Import the trained model and vocabulary
editAfter you choose a model, you must import it and its tokenizer vocabulary to your cluster. When you import the model, it must be chunked and imported one chunk at a time for storage in parts due to its size.
Trained models must be in a TorchScript representation for use with Elastic Stack machine learning features.
Eland encapsulates both the conversion of Hugging Face transformer models to their TorchScript representations and the chunking process in a single Python method; it is therefore the recommended import method.
-
Install the Eland Python client with PyTorch extra dependencies.
python -m pip install 'eland[pytorch]'
-
Run the
eland_import_hub_modelscript. For example:eland_import_hub_model --cloud-id <cloud-id> \ -u <username> -p <password> \ --hub-model-id elastic/distilbert-base-cased-finetuned-conll03-english \ --task-type ner \
Specify the Elastic Cloud identifier. Alternatively, use
--url.Provide authentication details to access your cluster. Refer to Authentication methods to learn more.
Specify the identifier for the model in the Hugging Face model hub.
Specify the type of NLP task. Supported values are
fill_mask,ner,text_classification,text_embedding, andzero_shot_classification.
For more details, refer to https://github.com/elastic/eland#nlp-with-pytorch.
Authentication methods
editThe following authentication options are available when using the import script:
-
username/password authentication (specified with the
-uand-poptions):eland_import_hub_model --url https://<hostname>:<port> -u <username> -p <password> ...
-
username/password authentication (embedded in the URL):
eland_import_hub_model --url https://<user>:<password>@<hostname>:<port> ...
-
API key authentication:
eland_import_hub_model --url https://<hostname>:<port> --es-api-key <api-key> ...
Deploy the model in your cluster
editAfter you import the model and vocabulary, you can use Kibana to view and manage
their deployment across your cluster under Machine Learning > Model Management.
Alternatively, you can use the
start trained model deployment API or
specify the --start option when you run the eland_import_hub_model script.
Since eland uses APIs to deploy the models, you cannot see the models in Kibana until the saved objects are synchronized. You can follow the prompts in Kibana, wait for automatic synchronization, or use the sync machine learning saved objects API.
When you deploy the model, it is allocated to all available machine learning nodes. The
model is loaded into memory in a native process that encapsulates libtorch,
which is the underlying machine learning library of PyTorch.
You can set additional deployment options that affect the performance of the model. For example, specify the number of allocations and the threads per allocation to optimize the throughput and speed of inference requests in your production environment. For more information about these options, refer to the start trained model deployment API.
You can view the allocation status in Kibana or by using the get trained model stats API.
Try it out
editWhen the model is deployed on at least one node in the cluster, you can begin to perform inference. Inference is a machine learning feature that enables you to use your trained models to perform NLP tasks (such as text extraction, classification, or embeddings) on incoming data.
The simplest method to test your model against new data is to use the Test model action in Kibana:
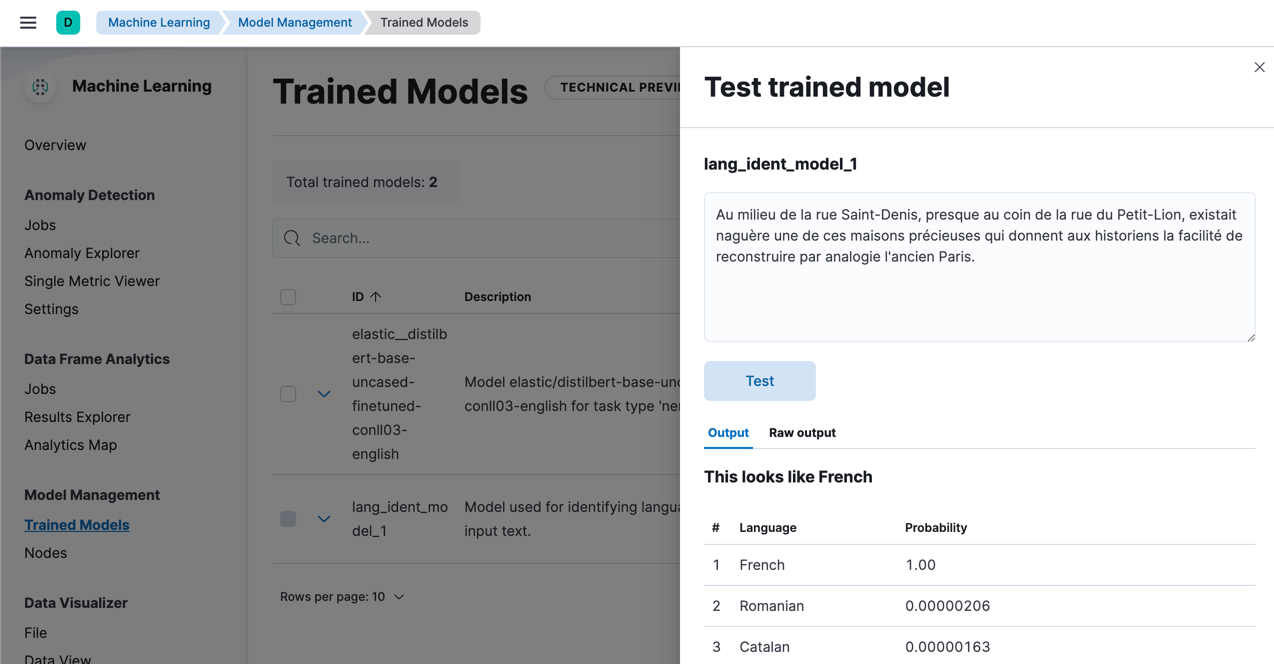
Alternatively, you can use the infer trained model API. For example, to try a named entity recognition task, provide some sample text:
POST /_ml/trained_models/elastic__distilbert-base-cased-finetuned-conll03-english/_infer
{
"docs":[{"text_field": "Sasha bought 300 shares of Acme Corp in 2022."}]
}
In this example, the response contains the annotated text output and the recognized entities:
{
"inference_results" : [
{
"predicted_value" : "[Sasha](PER&Sasha) bought 300 shares of [Acme Corp](ORG&Acme+Corp) in 2022.",
"entities" : [
{
"entity" : "Sasha",
"class_name" : "PER",
"class_probability" : 0.9953193407987492,
"start_pos" : 0,
"end_pos" : 5
},
{
"entity" : "Acme Corp",
"class_name" : "ORG",
"class_probability" : 0.9996392198381716,
"start_pos" : 27,
"end_pos" : 36
}
]
}
]
}
If you are satisfied with the results, you can add these NLP tasks in your ingestion pipelines.