Troubleshooting crawls
editTroubleshooting crawls
editThis page contains a detailed troubleshooting reference, including information about web crawler event logs.
This page documents issues users can troubleshoot, which generally fall into three categories.
-
See Crawl stability if:
- You’re not sure where to start (resolve stability issues first)
- No documents in the engine
- Many documents missing or outdated
- Crawl fails
- Crawl runs for the maximum duration (defaults to 24 hours)
-
See Content discovery if:
- Specific documents are missing or outdated
-
See Content extraction and indexing if:
- Specific documents are missing or outdated
- Incorrect content within documents
- Content missing from documents
We also provide solutions for specific errors:
The crawler cannot currently crawl pure JavaScript single-page applications (SPAs). We recommend looking at dynamic rendering to help your crawler properly index your JavaScript websites.
Another option is to serve a static HTML version of your Javascript website, using a solution such as Prerender.
Troubleshoot crawl stability
editCrawl stability issues may prevent the crawler from discovering, extracting, and indexing your content. It is critical to address these issues first.
Use the following techniques to troubleshoot crawl stability issues.
Validate one or more domains:
When adding a domain through the web crawler UI, the crawler validates the domain. You may have added a domain that experienced validation errors. Check those errors and re-crawl.
An invalid domain is a common cause for a crawl with no results. Fix the domain issues and re-crawl.
Analyze web crawler events logs for the most recent crawl:
First:
- Find the crawl request ID for the most recent crawl. In the Kibana UI, find this under Recent crawl requests.
- Filter the web crawler events logs by that ID. See View web crawler events logs to learn how to view these logs in Kibana.
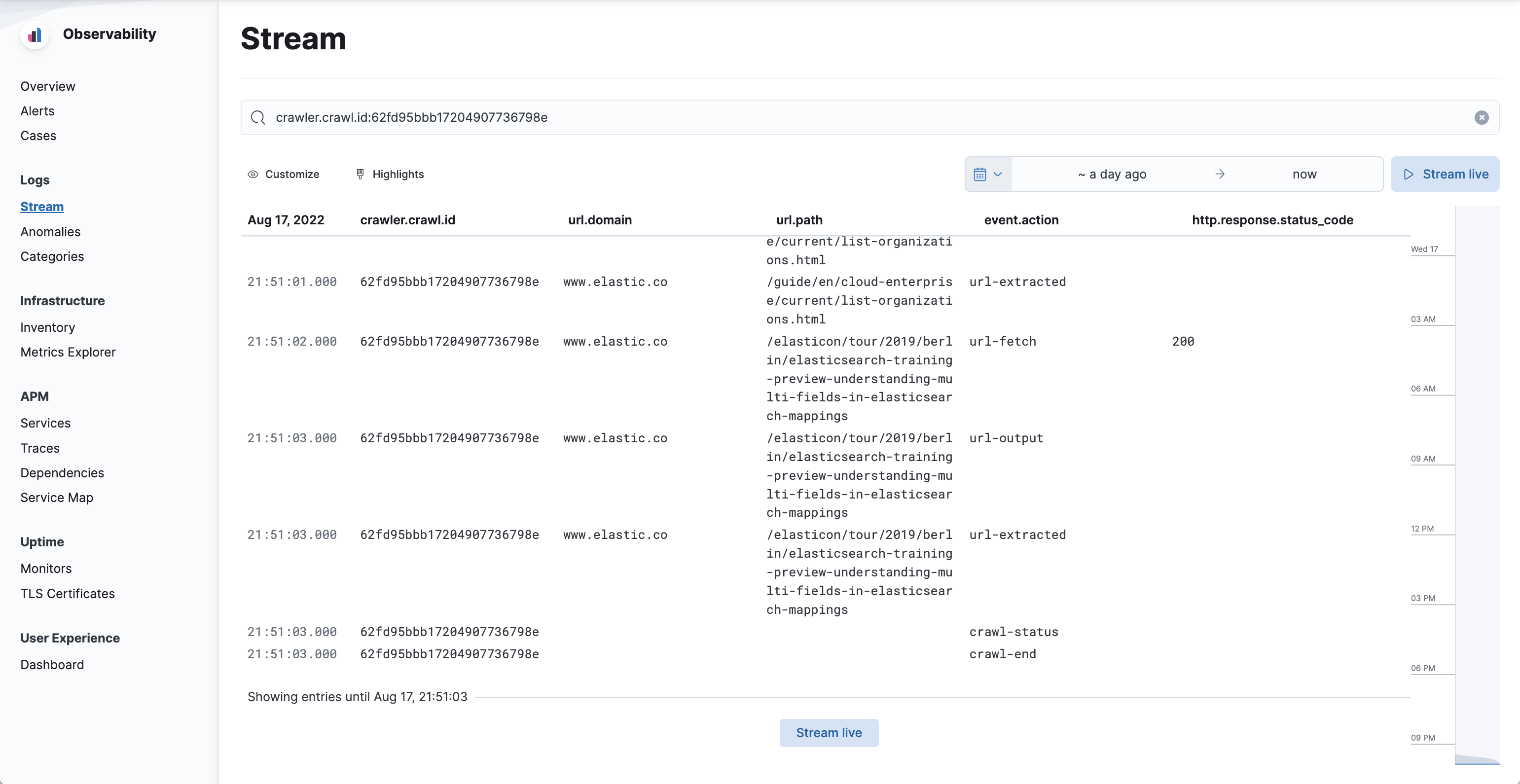
Then:
- Order the events by timestamp, oldest first. If using the Observability Logs stream, scroll to the end of the list.
-
Locate the
crawl-endevent and preceding events. These events communicate what happened before the crawl failed.
Analyze web crawler system logs:
These logs may contain additional information about your crawl.
Modify the web crawler configuration:
As a last resort, operators can modify the web crawler configuration, including resource limits.
See Elastic web crawler within the Enterprise Search configuration documentation.
Troubleshoot content discovery
editAfter your crawls are stable, you may find the crawler is not discovering your content as expected.
Use the following techniques to troubleshoot content discovery issues.
Confirm the most recent crawl completed successfully:
View the status of the most recent crawl to confirm it completed successfully.
If the crawl failed, look for signs of crawl stability issues. See Troubleshoot crawl stability.
View indexed documents to confirm missing pages:
Identify which pages are missing from your index, or focus on specific pages.
Analyze web crawler events logs for the most recent crawl:
See View web crawler events logs to learn how to view crawler events logs in Kibana.
First:
- Find the crawl request ID for the most recent crawl. In the Kibana UI, find this under Recent crawl requests.
- Filter the web crawler events logs by that ID.
- Find the URL of a specific document missing from the engine.
- Filter the web crawler events logs by that URL.
Then:
-
Locate
url-discoverevents to confirm the crawler has seen links to your page. Theoutcomeandmessagefields may explain why the web crawler did not crawl the page. -
If
url-discoverevents indicate discovery was successful, locateurl-fetchevents to analyze the fetching phase of the crawl.
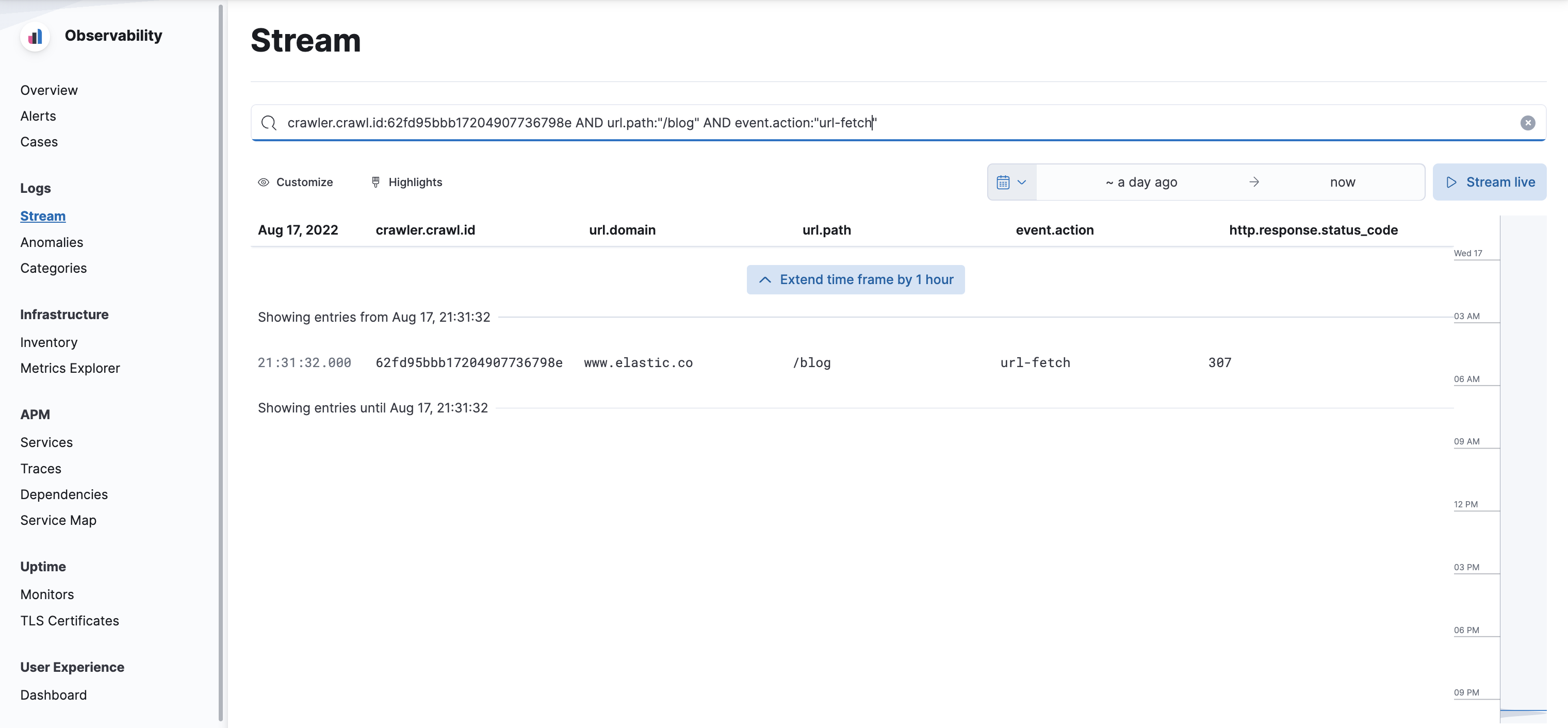
Analyze web crawler system logs:
If you are managing your own Enterprise Search deployment, you can also view the web crawler system logs.
View these logs on disk in the crawler.log file.
The events in these logs are less verbose then the web crawler events logs, but they can help solve web crawler issues. Each event has a crawl request ID, which allows you to analyze the logs for a specific crawl.
Address specific content discovery problems:
| Problem | Description | Solution |
|---|---|---|
External domain |
The web crawler does not follow links that go outside the domains configured for each crawl. |
Add any missing domains. Remember each unique combination of protocol and hostname needs to be added as a domain. For example, |
Disallowed path |
The web crawler does not follow links whose paths are disallowed by a domain’s crawl rules or robots.txt directives. |
Manage crawl rules and |
No incoming links |
The web crawler cannot find pages that have no incoming links, unless you provide the path as an entry point. |
Add links to the content from other content that the web crawler has already discovered, or explicitly add the URL entry point or within a sitemap. |
Nofollow links |
The web crawler does not follow nofollow links. |
Remove the nofollow link to allow content discovery. |
|
If a page contains a |
Remove the meta tag from your page. |
Page too large |
The web crawler does not parse HTTP responses larger than |
Reduce the size of your page. Or, increase the limit for your deployment. Increasing the limit may increase crawl durations and resource consumption, and could reduce crawl stability. Significantly increasing these limits may also have a negative impact on search result relevance. |
Too many redirects |
The web crawler does not follow redirect chains longer than |
Reduce the number of redirects for the page. Or, increase the limit for your deployment. Increasing the limit may increase crawl durations and resource consumption, and could reduce crawl stability. Significantly increasing these limits may also have a negative impact on search result relevance. |
Network latency |
The web crawler fails requests that exceed the following network timeouts:
|
Reduce network latency. Or, increase these timeouts for your deployment. Increasing the timeouts may increase crawl durations and resource consumption, and could reduce crawl stability. |
HTTP errors |
The web crawler cannot discover and index content if it cannot fetch HTML pages from a domain.
The web crawler will not index pages that respond with a |
Fix HTTP server errors. Ensure correct HTTP response codes. |
HTML errors |
The web crawler cannot parse extremely broken HTML pages. In that case, the web crawler cannot index the page, and cannot discover links coming from that page. |
Use the W3C markup validation service to identify and resolve HTML errors in your content. |
Security |
The web crawler cannot access content requiring authentication or authorization. |
Remove the security to allow access to the web crawler. |
Non-HTTP protocol |
The web crawler recognizes only the HTTP and HTTPS protocols. |
Publish your content at URLs using HTTP or HTTPS protocols. Alternatively, for protocols like FTP, use the Elastic Enterprise Search network drives connector package to deploy and run a network drives connector on your own infrastructure. |
Invalid SSL certificate |
The web crawler will not crawl HTTPS pages with invalid certificates. |
See Troubleshoot specific errors for how to set specific certificate authorities, and to disable SSL checks. |
Troubleshoot content extraction and indexing
editThe web crawler may be discovering your content but not extracting and indexing it as expected.
Use the following techniques to troubleshoot content discovery issues.
Confirm the most recent crawl completed successfully:
View the status of the most recent crawl to confirm it completed successfully.
If the crawl failed, look for signs of crawl stability issues. See Troubleshoot crawl stability.
View indexed documents to confirm missing pages:
Identify which pages are missing from your index, or focus on specific pages. Browse the documents in your index, under Content → Indices → Documents.
If documents are missing from the index, look for signs of content discovery issues. See Troubleshoot content discovery.
Analyze web crawler events logs for the most recent crawl:
First:
- Find the crawl request ID. In the Kibana UI, find this under Recent crawl requests.
- Filter the web crawler events logs by that ID.
- Find the URL of a specific document missing from the engine.
- Filter the web crawler events logs by that URL.
Then:
-
Locate
url-extractedevents to confirm the crawler was able to extract content from your page. Theoutcomeandmessagefields may explain why the web crawler could not extract and index the content. -
If
url-extractedevents indicate extraction was successful, locateurl-outputevents to confirm the web crawler attempted ingestion of the page’s content.
See event logs.
Analyze web crawler system logs:
These may contain additional information about specific pages.
Address specific content extraction and indexing problems:
| Problem | Description | Solution |
|---|---|---|
Duplicate content |
If your website contains pages with duplicate content, those pages are stored as a single document within your engine.
The document’s |
Use a canonical URL link tag within any document containing duplicate content. See also Duplicate document handling. |
Non-HTML content missing |
The web crawler can index non-HTML, downloadable files. |
Ensure that the feature is enabled, and the MIME type of the missing file(s) is included in your configured MIME types. See Binary content extraction. |
|
The web crawler will not index pages that include a |
Remove the meta tag from your page. See Robots meta tags. |
Page too large |
The web crawler does not parse HTTP responses larger than |
Reduce the size of your page. Or, increase the limit for your deployment. Increasing the limit may increase crawl durations and resource consumption, and could reduce crawl stability. Significantly increasing these limits may also have a negative impact on search result relevance. |
Truncated fields |
The web crawler truncates some fields before indexing the document, according to the following limits: |
Reduce the length of these fields within your content. Or, increase these limits for your deployment. Increasing the limits may increase crawl durations and resource consumption, and could reduce crawl stability. Significantly increasing these limits may also have a negative impact on search result relevance. |
Broken HTML |
The web crawler cannot parse extremely broken HTML pages. |
Use the W3C markup validation service to identify and resolve HTML errors in your content. |
View web crawler events logs
editSee View web crawler events logs to learn how to view the web crawler events logs in Kibana. For a complete reference of all events, see Web crawler events logs reference.
You might need to troubleshoot by viewing the web crawler events logs. The web crawler records detailed structured events logs for each crawl. The logs are indexed into Elasticsearch, and you can view the logs in Kibana.
View web crawler events by crawl ID and URL
editTo monitor a specific crawl or a specific domain, you must filter the web crawler events logs within Kibana. See View web crawler events logs to learn how to view these logs in Kibana.
- To view the events for a specific crawl, find the request ID in the Kibana UI, under Recent crawl requests.
-
Filter on the
crawler.crawl.idfield. -
Filter further to narrow your results to a specific URL. Use the following fields:
-
The full URL:
url.full -
Required components of the URL:
url.scheme,url.domain,url.port,url.path -
Optional components of the URL:
url.query,url.fragment,url.username,url.password
-
The full URL:
Troubleshoot specific errors
editIf you are troubleshooting a specific error, you may find the error message and possible solutions here:
-
Failed HTTP request: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
The domain’s SSL certificate is not included in the Java root certificate store. The domain owner may need to work with the SSL certificate provider to get their root certificate added to the Java root certificate store.
For a self-signed certificate, add your certificate to the web crawler configuration, or change the SSL verification mode.
Add your certificate using the web crawler configuration setting
connector.crawler.security.ssl.certificate_authorities.If you have file access to the server, specify the location of the file:
connector.crawler.security.ssl.certificate_authorities: - /path/to/QuoVadis-PKIoverheid-Organisatie-Server-CA-G3-PEM.pem
For Elastic Cloud or other environments without file access, provide the contents of the file inline:
connector.crawler.security.ssl.certificate_authorities: - | -----BEGIN CERTIFICATE----- MIIHWzCCBUOgAwIBAgIINBHa3VUceEkwDQYJKoZIhvcNAQELBQAwajELMAkGA1UE BhMCTkwxHjAcBgNVBAoMFVN0YWF0IGRlciBOZWRlcmxhbmRlbjE7MDkGA1UEAwwy U3RhYXQgZGVyIE5lZGVybGFuZGVuIE9yZ2FuaXNhdGllIFNlcnZpY2VzIENBIC0g RzMwHhcNMTYxMTAzMTQxMjExWhcNMjgxMTEyMDAwMDAwWjCBgjELMAkGA1UEBhMC ... TkwxIDAeBgNVBAoMF1F1b1ZhZGlzIFRydXN0bGluayBCLlYuMRcwFQYDVQRhDA5O VFJOTC0zMDIzNzQ1OTE4MDYGA1UEAwwvUXVvVmFkaXMgUEtJb3ZlcmhlaWQgT3Jn YW5pc2F0aWUgU2VydmVyIENBIC0gRzMwggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAw SFfzGre9T6yBL4I+6nxG -----END CERTIFICATE-----Alternatively, for development and test environments, change the SSL verification mode using
connector.crawler.security.ssl.verification_mode:# INSECURE - DO NOT USE IN PRODUCTION ENVIRONMENTS connector.crawler.security.ssl.verification_mode: none
Operators can configure several web crawler settings. See Elastic web crawler within the Enterprise Search configuration documentation.