Manage cross-cluster replication
editManage cross-cluster replication
editUse the following information to manage cross-cluster replication tasks, such as inspecting replication progress, pausing and resuming replication, recreating a follower index, and terminating replication.
To start using cross-cluster replication, access Kibana and go to Management > Stack Management. In the side navigation, select Cross-Cluster Replication.
Inspect replication statistics
editTo inspect the progress of replication for a follower index and view detailed shard statistics, access Cross-Cluster Replication and choose the Follower indices tab.
Select the name of the follower index you want to view replication details for. The slide-out panel shows settings and replication statistics for the follower index, including read and write operations that are managed by the follower shard.
To view more detailed statistics, click View in Index Management, and then select the name of the follower index in Index Management. Open the tabs for detailed statistics about the follower index.
API example
Use the get follower stats API to inspect replication progress at the shard level. This API provides insight into the read and writes managed by the follower shard. The API also reports read exceptions that can be retried and fatal exceptions that require user intervention.
Pause and resume replication
editTo pause and resume replication of the leader index, access Cross-Cluster Replication and choose the Follower indices tab.
Select the follower index you want to pause and choose Manage > Pause Replication. The follower index status changes to Paused.
To resume replication, select the follower index and choose Resume replication.
API example
You can pause replication with the pause follower API and then later resume replication with the resume follower API. Using these APIs in tandem enables you to adjust the read and write parameters on the follower shard task if your initial configuration is not suitable for your use case.
Recreate a follower index
editWhen a document is updated or deleted, the underlying operation is retained in
the Lucene index for a period of time defined by the
index.soft_deletes.retention_lease.period parameter. You configure
this setting on the leader index.
When a follower index starts, it acquires a retention lease from the leader index. This lease informs the leader that it should not allow a soft delete to be pruned until either the follower indicates that it has received the operation, or until the lease expires.
If a follower index falls sufficiently behind a leader and cannot
replicate operations, Elasticsearch reports an indices[].fatal_exception error. To
resolve the issue, recreate the follower index. When the new follow index
starts, the remote recovery process recopies the
Lucene segment files from the leader.
Recreating the follower index is a destructive action. All existing Lucene segment files are deleted on the cluster containing the follower index.
To recreate a follower index, access Cross-Cluster Replication and choose the Follower indices tab.
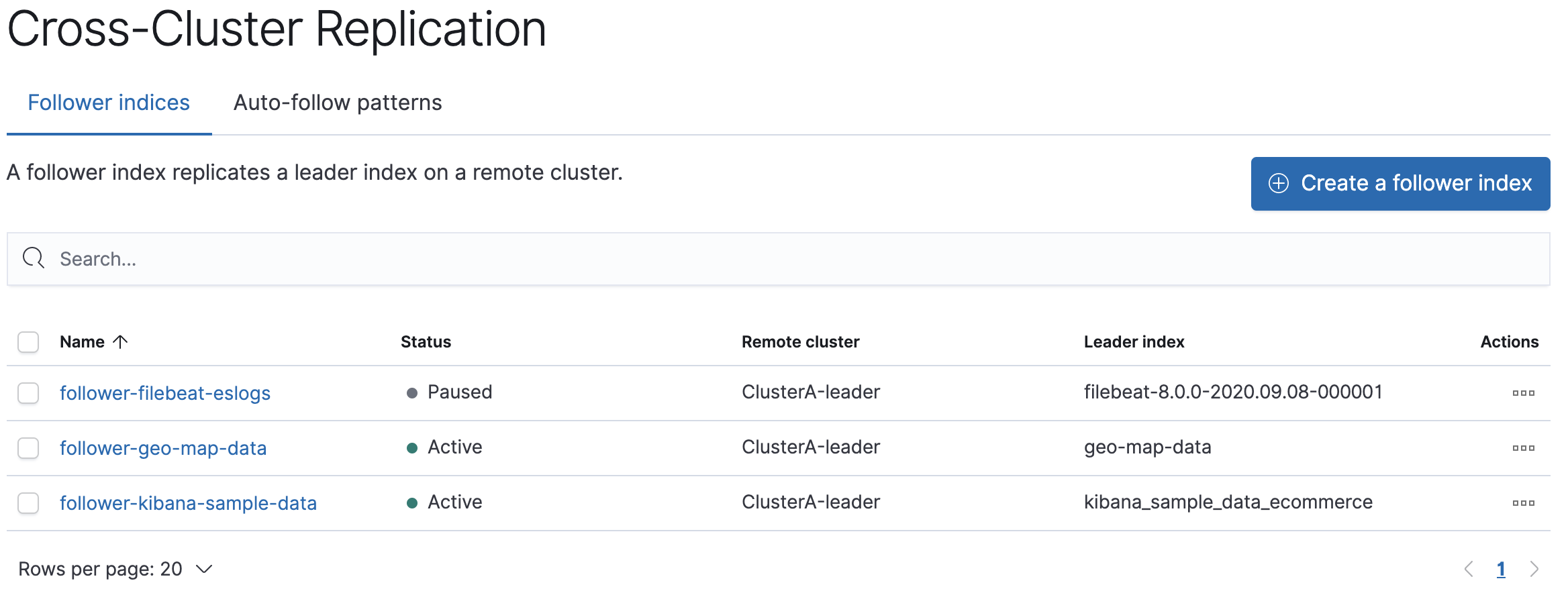
Select the follower index and pause replication. When the follower index status changes to Paused, reselect the follower index and choose to unfollow the leader index.
The follower index will be converted to a standard index and will no longer display on the Cross-Cluster Replication page.
In the side navigation, choose Index Management. Select the follower index from the previous steps and close the follower index.
You can then recreate the follower index to restart the replication process.
Use the API
Use the pause follow API to pause the replication process. Then, close the follower index and recreate it. For example:
POST /follower_index/_ccr/pause_follow
POST /follower_index/_close
PUT /follower_index/_ccr/follow?wait_for_active_shards=1
{
"remote_cluster" : "remote_cluster",
"leader_index" : "leader_index"
}
Terminate replication
editYou can unfollow a leader index to terminate replication and convert the follower index to a standard index.
Access Cross-Cluster Replication and choose the Follower indices tab.
Select the follower index and pause replication. When the follower index status changes to Paused, reselect the follower index and choose to unfollow the leader index.
The follower index will be converted to a standard index and will no longer display on the Cross-Cluster Replication page.
You can then choose Index Management, select the follower index from the previous steps, and close the follower index.
Use the API
You can terminate replication with the unfollow API. This API converts a follower index to a standard (non-follower) index.