Indexing Documents Guide
editIndexing Documents Guide
editYou are moments away from searching through your documents with great precision. Soon, your visitors will be finding the right things faster than ever before.
Pssst: You may also find the API Overview to be a helpful companion as you begin.
How can I add Documents to an Engine?
editWithin App Search, there are three different ways to index objects into your Engine:
- Paste a raw JSON array during on-boarding or after Engine creation.
-
Import a
.jsonfile during on-boarding or after Engine creation. - Send a POST request to the Documents API endpoint.
POST /api/as/v1/engines/{ENGINE_NAME}/documents
Example - Adding two National Parks to a new Engine.
curl -X POST 'https://host-2376rb.api.swiftype.com/api/as/v1/engines/national-parks-demo/documents' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer private-xxxxxxxxxxxxxxxxxxxx' \
-d '[
{
"description": "Covering most of Mount Desert Island and other coastal islands, Acadia features the tallest mountain on the Atlantic coast of the United States, granite peaks, ocean shoreline, woodlands, and lakes. There are freshwater, estuary, forest, and intertidal habitats.",
"nps_link": "https://www.nps.gov/acad/index.htm",
"states": [
"Maine"
],
"title": "Acadia",
"id": "park_acadia",
"visitors": 3303393,
"world_heritage_site": false,
"location": "44.35,-68.21",
"acres": 49057.36,
"square_km": 198.5,
"date_established": "1919-02-26T06:00:00Z"
},
{
"description": "Crater Lake lies in the caldera of an ancient volcano called Mount Mazama that collapsed 7,700 years ago. It is the deepest lake in the United States and is noted for its vivid blue color and water clarity. There are two more recent volcanic islands in the lake, and, with no inlets or outlets, all water comes through precipitation.",
"nps_link": "https://www.nps.gov/crla/index.htm",
"states": [
"Oregon"
],
"title": "Crater Lake",
"id": "park_crater-lake",
"visitors": 756344,
"world_heritage_site": false,
"location": "42.94,-122.1",
"acres": 183224.05,
"square_km": 741.5,
"date_established": "1902-05-22T05:00:00Z"
}
]'
You can send in 100 documents per request. Learn more about the Documents API Reference endpoint.
What is a Document?
editApplications are full of objects.
A document is a representation of an object. An object becomes a document when it is indexed by your Engine to adhere to a schema.
Your objects will still exist within your database or backend API, but you will have a replicative set of documents within your Engine.
With App Search, you can search upon these documents.
For example, if you have an online storefront that sells fruit, then a piece of fruit would be an object:
{
"fruit": "apple",
"quantity": 32,
"location": "37.7894758, -122.3940638",
"expiry": "2018-10-13"
}
The goal of App Search - and open-source utilities like Elasticsearch - is to help you transform your objects into indexed documents so that you may search upon them in an intelligent and expedient way.
For that, one needs a Schema.
View the Documents API Reference.
What is a Schema?
editDuring the indexing process, a schema is created based on the key/value pairings of the object.
By default, you do not need to define a schema.
Upon first ingestion, a default text based schema is created for you.
In our example fruit case, the default schema would be:
{
"fruit": "text",
"quantity": "text",
"location": "text",
"expiry": "text"
}
Each Field Type has different parameters for enabling search capabilities and input sanitization:
text |
A full-text, deeply analyzed string value. This is the default type for all new fields. Supports full-text search, highlighting, filtering, faceting, value boosting and sorting. |
number |
A finite double-precision floating point value: |
date |
An RFC3339 formatted date string value: |
geolocation |
A lat/long formatted string value: |
For a full type breakdown, see the API Overview.
If you know in advance which Field Types you will need, then you can apply them using either the dashboard or the Schema API endpoint before indexing your full set of data:
Update Schema via Dashboard - Reviewing and modifying the Engine’s schema.
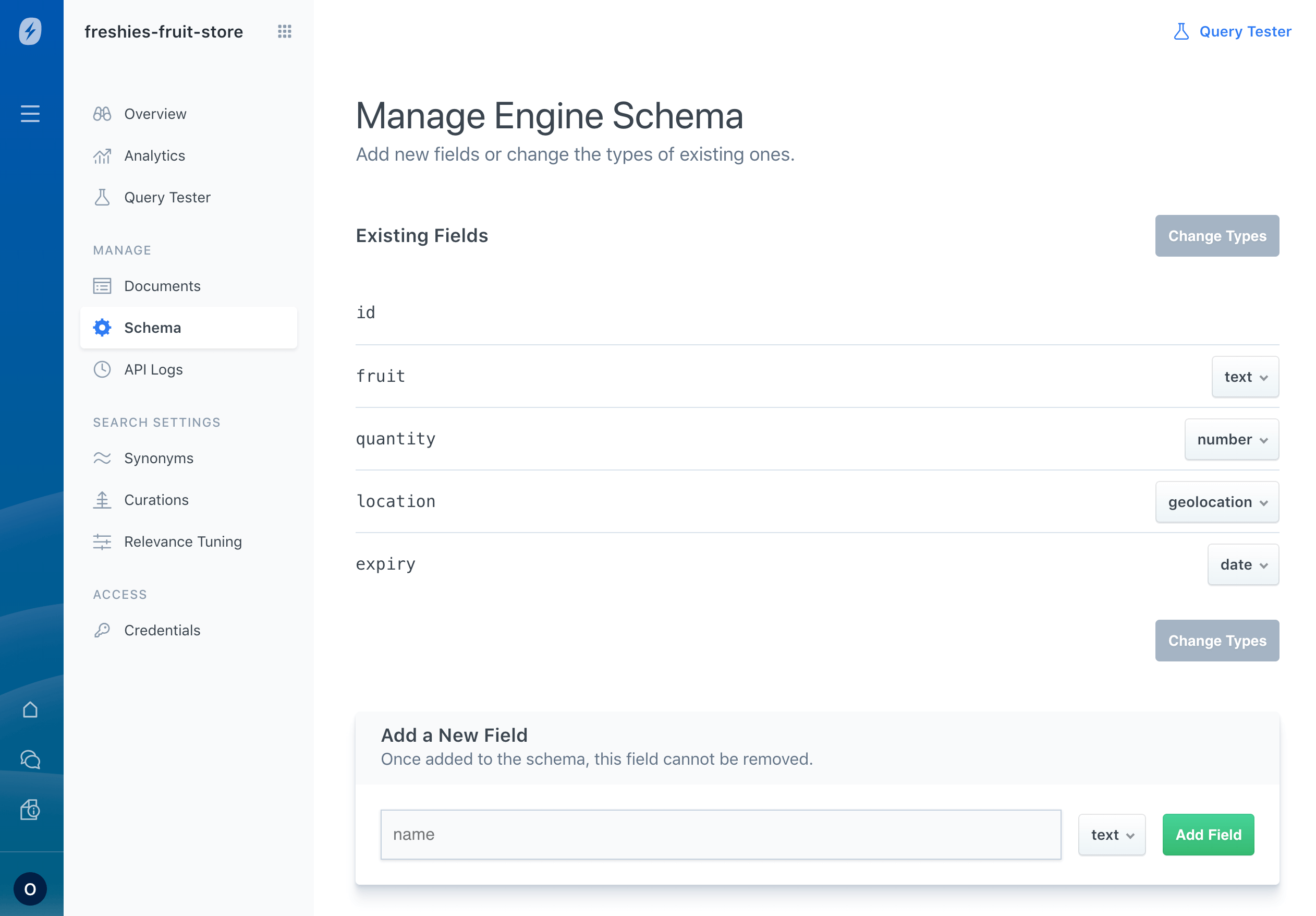
Our custom-tailored schema might now be:
{
"fruit": "text",
"quantity": "number",
"location": "geolocation",
"expiry": "date"
}
To summarize: An object is indexed into your App Search Engine, becoming a document. A document is organized by Field Type around a schema.
View the Schema API Reference.
What’s Next?
editYou should have a solid grip on document indexing basics: adding data to your Engine and then building a schema.
If you have not been acquainted with the Documents endpoint, then that may be a great next step.
Otherwise, the Search guide is where you should venture to further increase your conceptual understanding of the core searching concepts.
Alternatively, if you want to learn more about Schemas and Field Types, that would be a helpful read.