¿Qué es la clasificación de texto?
Definición de clasificación de texto
La clasificación de texto es un tipo de machine learning que clasifica documentos de texto u oraciones en clases o categorías predefinidas. Analiza el contenido y el significado del texto y, luego, utiliza etiquetas de texto para asignarle la más adecuada.
Las aplicaciones de clasificación de texto en el mundo real incluyen análisis de sentimiento (que determina sentimientos positivos o negativos en las reseñas), detección de spam (como detectar correos electrónicos no deseados) y categorización de temas (p. ej., organizar artículos de noticias en temas relevantes). La clasificación de texto tiene un papel importante en el procesamiento del lenguaje natural (PLN) permitiendo que las computadoras comprendan y organicen grandes cantidades de texto no estructurado. Esto simplifica tareas como el filtrado de contenidos, los sistemas de recomendación y el análisis de los comentarios de los clientes.
Tipos de clasificación de texto
Los tipos de clasificación de texto que puedes encontrar incluyen:
El análisis de sentimiento de texto determina el sentimiento o emoción expresada en un fragmento de texto, generalmente categorizándolo como positivo, negativo o neutral. Se utiliza para analizar reseñas de productos, publicaciones en redes sociales y comentarios de los clientes.
La detección de toxicidad, relacionada con el análisis de sentimiento de texto, identifica lenguaje ofensivo o dañino en línea. Ayuda a los moderadores de comunidades en línea a mantener un entorno digital respetuoso en discusiones, comentarios o publicaciones en redes sociales en línea.
El reconocimiento de intenciones es otro subconjunto del análisis de sentimiento de texto que se utiliza para comprender el propósito (o intención) detrás de la entrada de texto de un usuario. Los chatbots y los asistentes virtuales suelen utilizar el reconocimiento de intenciones para responder a las consultas de los usuarios.
La clasificación binaria clasifica el texto en una de dos clases o categorías. Un ejemplo común es la detección de correo no deseado, que clasifica el texto, como correos electrónicos o mensajes, en categorías de correo legítimo o no deseado para filtrar automáticamente el contenido no solicitado y potencialmente dañino.
La clasificación multiclase clasifica el texto en tres o más clases o categorías distintas. Esto facilita la organización y la recuperación de información de contenidos como artículos de noticias, publicaciones de blogs o trabajos de investigación.
La categorización de temas, relacionada con la clasificación multiclase, agrupa documentos o artículos en temas o tópicos predefinidos. Por ejemplo, los artículos de noticias se pueden clasificar en temas como política, deportes y entretenimiento.
La identificación de idioma determina el idioma en el que está escrito un fragmento de texto. Esto es útil en contextos multilingües y aplicaciones basadas en idiomas.
El reconocimiento de entidades nombradas se centra en identificar y clasificar entidades nombradas dentro de un texto, como nombres de personas, organizaciones, ubicaciones y fechas.
La clasificación de preguntas se ocupa de categorizar las preguntas según el tipo de respuesta esperada, lo que puede resultar útil para motores de búsqueda y sistemas de respuesta a preguntas.
Proceso de clasificación de texto
El proceso de clasificación de texto implica varios pasos, desde la recopilación de datos hasta el despliegue del modelo. Esta es una visión general breve de cómo funciona:
Paso 1: recopilación de datos
Recopilar un conjunto de documentos de texto con sus correspondientes categorías para el proceso de etiquetado de texto.
Paso 2: preprocesamiento de datos
Limpiar y preparar los datos del texto eliminando símbolos innecesarios, convirtiéndolos a minúsculas y manejando caracteres especiales como la puntuación.
Paso 3: tokenización
Dividir el texto en tokens, que son unidades pequeñas, como palabras. Los tokens ayudan a encontrar coincidencias y conexiones mediante la creación de partes que se pueden buscar individualmente. Este paso es especialmente útil para la búsqueda vectorial y la búsqueda semántica, que brindan resultados según la intención del usuario.
Paso 4: extracción de características
Convertir el texto en representaciones numéricas que los modelos de machine learning puedan comprender. Algunos métodos comunes incluyen contar las apariciones de palabras (también conocido como bolsa de palabras) o usar incrustaciones de palabras para captar el significado de estas.
Paso 5: entrenamiento del modelo
Ahora que los datos están limpios y preprocesados, se pueden utilizar para entrenar un modelo de machine learning. El modelo aprenderá patrones y asociaciones entre las características del texto y sus categorías. Esto le ayuda a comprender las convenciones de etiquetado de texto utilizando los ejemplos preetiquetados.
Paso 6: etiquetado de texto
Crear un set de datos nuevo e independiente para comenzar a etiquetar y clasificar texto nuevo. En el proceso de etiquetado de texto, el modelo separa el texto en categorías predeterminadas desde el paso de recopilación de datos.
Paso 7: evaluación del modelo
Se observa de cerca el rendimiento del modelo entrenado en el proceso de etiquetado de texto para ver qué tan bien puede clasificar el texto invisible.
Paso 8: ajuste de hiperparámetros
Según cómo vaya la evaluación del modelo, se recomienda ajustar la configuración del modelo para optimizar el rendimiento.
Paso 9: despliegue del modelo
Utilizar el modelo entrenado y ajustado para clasificar nuevos datos de texto en sus categorías apropiadas.
¿Por qué es importante la clasificación de texto?
La clasificación de texto es importante porque permite a las computadoras categorizar y comprender automáticamente grandes volúmenes de datos de texto. En nuestro mundo digital, nos encontramos con enormes cantidades de información textual todo el tiempo. Piensa en correos electrónicos, redes sociales, reseñas y más. La clasificación de texto permite a las máquinas organizar estos datos no estructurados en grupos significativos mediante etiquetado de texto. Dándole sentido a un contenido impenetrable, la clasificación de texto mejora la eficiencia, facilita la toma de decisiones y optimiza la experiencia del usuario.
Casos de uso de clasificación de texto
Los casos de uso de clasificación de texto abarcan una variedad de entornos profesionales. Estos son algunos casos de uso del mundo real que puedes encontrar:
- Automatizar y categorizar los tickets de soporte al cliente, priorizarlos y enviarlos a los equipos adecuados para su resolución.
- Analizar los comentarios de los clientes, las respuestas a encuestas y los debates en línea para detectar tendencias del mercado y preferencias de los consumidores.
- Hacer un seguimiento de menciones en redes sociales y reseñas en línea para monitorear la reputación y el sentimiento de la marca.
- Organizar y etiquetar contenido en sitios web y plataformas de comercio electrónico utilizando etiquetas o etiquetas de texto para facilitar el descubrimiento de contenido, lo que mejora las experiencias de usuario de los clientes.
- Identificar posibles clientes potenciales de ventas de las redes sociales y otras fuentes en línea en función de palabras clave y criterios específicos.
- Analizar las reseñas y los comentarios de la competencia para obtener información sobre sus fortalezas y debilidades.
- Segmentar a los clientes en función de sus interacciones y comentarios utilizando etiquetas de texto para adaptarles las estrategias y campañas de marketing.
- Detectar actividades y transacciones fraudulentas en los sistemas financieros según patrones y anomalías de etiquetado de texto (también conocido como detección de anomalías).
Técnicas y algoritmos para la clasificación de texto
Estas son algunas técnicas y algoritmos utilizados para la clasificación de texto:
- La bolsa de palabras es una técnica sencilla que cuenta la aparición de palabras sin considerar su orden.
- Las incrustaciones de palabras utilizan varias técnicas que convierten las palabras en representaciones numéricas trazadas en un espacio multidimensional, captando así las relaciones complejas entre las palabras.
- Los árboles de decisión son algoritmos de machine learning que crean una estructura similar a un árbol de hojas y nodos de decisión. Cada nodo prueba la presencia de una palabra, lo que ayuda al árbol a aprender patrones en los datos del texto.
- El bosque aleatorio es un método que combina múltiples árboles de decisión para mejorar la precisión en la clasificación de texto.
- Las representaciones de codificador bidireccional de transformadores (BERT) son un sofisticado modelo de clasificación basado en transformadores que puede comprender el contexto de las palabras.
- Naive Bayes calcula la probabilidad de que un documento determinado pertenezca a una clase particular en función de la aparición de palabras en el documento. Estima la probabilidad de que cada palabra aparezca en cada clase y combina estas probabilidades utilizando el teorema de Bayes (un teorema fundamental en la teoría de la probabilidad) para hacer predicciones.
- Las máquinas de vector soporte (SVM) son un algoritmo de machine learning que se utiliza para tareas de clasificación binaria y multiclase. El algoritmo SVM busca el hiperplano que mejor separa los puntos de datos de diferentes clases en un espacio de características de alta dimensión. Esto le ayuda a realizar predicciones precisas sobre datos de texto nuevos e invisibles.
- La frecuencia de términos-frecuencia de documentos inversa (TF-IDF) es un método que mide la importancia de las palabras en un documento en comparación con todo el set de datos.
Métricas de evaluación en la clasificación de texto
Las métricas de evaluación en la clasificación de texto se utilizan para medir el rendimiento del modelo de diferentes maneras. Algunas métricas de evaluación comunes incluyen:
Exactitud
La proporción de muestras de texto correctamente clasificadas respecto del total de muestras. Da una medida general de la corrección del modelo.
Precisión
La proporción de muestras positivas predichas correctamente de todas las muestras positivas predichas. Indica cuántos de los casos positivos predichas fueron realmente correctos.
Recuperación (o sensibilidad)
La proporción de muestras positivas predichas correctamente de todas las muestras positivas reales. Mide qué tan bien el modelo identifica casos positivos.
Puntuación F1
Una medida equilibrada que combina precisión y recuperación, lo que te brinda una evaluación general del rendimiento del modelo cuando encuentra clases desequilibradas.
Área bajo la curva característica operativa del receptor (AUC-ROC)
Una representación gráfica de la capacidad del modelo para distinguir entre diferentes clases. Esto es especialmente útil en la clasificación binaria.
Matriz de confusión
Una tabla que muestra el número de verdaderos positivos, verdaderos negativos, falsos positivos y falsos negativos. Te brinda un desglose detallado del rendimiento de tu modelo.
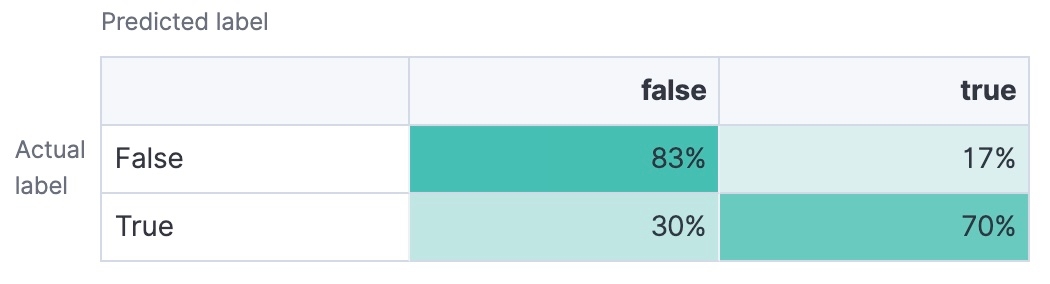
Al final, tu objetivo debe ser elegir un modelo de clasificación de texto con alta exactitud, precisión, recuperación y puntuación F1, según tus necesidades específicas. AUC-ROC y la matriz de confusión también pueden ofrecer información útil sobre la capacidad de tu modelo para manejar diferentes umbrales de clasificación y brindarte una mejor comprensión de su rendimiento.
Tendencias futuras en la clasificación de texto
Las tendencias futuras en la clasificación de texto van desde la IA abierta hasta herramientas específicas de la industria. A medida que la tecnología de machine learning se expanda, también lo harán las capacidades de clasificación de texto. Por ejemplo, a medida que las herramientas y la tecnología de vanguardia se vuelven más accesibles, también deben volverse más diversas. Pronto veremos surgir la clasificación de texto multilingüe para respaldar la creciente necesidad de soporte multilingüe en aplicaciones globales, analizando efectivamente múltiples idiomas en el mismo set de datos. La clasificación de textos de dominios específicos también despegará a medida que los modelos se entrenen para brindar clasificaciones más específicas y, por lo tanto, más precisas, adaptadas a industrias como la legal, la médica o la financiera.
Por supuesto, las tendencias de clasificación de texto influirán en las nuevas capacidades de IA. A medida que las aplicaciones de IA se vuelven más frecuentes, existe una creciente necesidad de modelos de clasificación de texto transparentes e interpretables. La IA explicable implica incorporar métodos de explicabilidad para comprender el razonamiento detrás de las predicciones del modelo.
Los modelos de aprendizaje profundo, como redes neuronales convolucionales (CNN) y redes neuronales recurrentes (RNN), y los modelos híbridos son arquitecturas de redes neuronales que se aplican a la clasificación de texto. Las CNN se utilizan principalmente para tareas de procesamiento de imágenes y las RNN están diseñadas para manejar datos secuenciales, pero ambas han demostrado la capacidad de comprender correctamente patrones de texto. Los modelos híbridos combinan múltiples arquitecturas (p. ej., CNN, RNN y modelos basados en transformadores como BERT) para aprovechar las fortalezas de diferentes enfoques a fin de realizar una mejor clasificación del texto.
Las investigaciones futuras también pueden explorar técnicas que permitan a los modelos de clasificación de textos aprender de menos ejemplos etiquetados (aprendizaje de pocas tomas) o incluso realizar clasificación de texto en clases que no se ven durante el entrenamiento (aprendizaje de tomas cero). Ambos tienen el potencial de reducir significativamente la dependencia de grandes sets de datos etiquetados, haciendo que la clasificación de texto sea más escalable y adaptable a nuevas tareas.
Clasificación de texto con Elastic
La clasificación de texto es una de las muchas funciones de procesamiento del lenguaje natural que encontrarás en las soluciones de Elastic Search. Con Elasticsearch, puedes clasificar tu texto no estructurado, extraer información de él y aplicarlo a tus necesidades comerciales de forma rápida y sencilla.
Ya sea que lo necesites para búsqueda, observabilidad o seguridad, Elastic te permite aprovechar la clasificación de texto para extraer y organizar información de manera más eficiente para tu negocio.