Tutorial sobre observabilidad de Kubernetes: Monitoreo y análisis de logs
Kubernetes surgió como la tecnología de orquestación de contenedores estándar de hecho y como una tecnología integral en el movimiento nativo del cloud. Lo nativo del cloud aporta velocidad, elasticidad y agilidad al desarrollo de software, pero también aumenta la complejidad: con cientos de microservicios en miles (o millones) de contenedores, ejecutándose en pods efímeros y desechables. Monitorear un sistema transitorio tan complejo y distribuido es desafiante y, al mismo tiempo, muy importante. Afortunadamente, Elastic facilita la incorporación de la observabilidad en tu entorno de Kubernetes.
En esta serie de tutoriales sobre observabilidad de Kubernetes, exploraremos cómo puedes monitorear todos los aspectos de tus aplicaciones que se ejecutan en Kubernetes, incluidos los siguientes:
- Ingesta y análisis de logs
- Métricas de estado y rendimiento de recopilación
- Monitoreo de rendimiento de aplicaciones con Elastic APM
Al finalizar este tutorial, tendrás un ejemplo práctico de una aplicación que envía todos sus datos de observabilidad al Elastic Stack para monitoreo y análisis.
¿Por qué elegir Elastic Observability para Kubernetes?
La observabilidad se sostiene sobre tres datos fundamentales: logs, métricas y monitoreo de rendimiento de aplicaciones (o APM, para abreviar). No hay escasez de artículos que mapeen diferentes herramientas y proveedores para conformar el mejor monitoreo para Kubernetes: creando al estilo Frankenstein entre tres y seis herramientas, proveedores y tecnologías diferentes…
No tengas miedo. Elastic Observability combina tus logs, métricas y datos de APM para una visibilidad y análisis unificados usando una herramienta. Comienza a solucionar problemas en función de una anomalía de latencia para el usuario en los datos de APM (detectada a través de Machine Learning), reorganiza según las métricas de un pod de Kubernetes en particular, observa los logs que generó ese pod y correlaciónalos con métricas y logs que describen los eventos que suceden en el host y la red; todo al tiempo que te mantienes en la misma interfaz de usuario. Eso es la observabilidad bien usada.
Si bien simplifica todo para los usuarios, ocurren muchas cosas en segundo plano porque…
Los logs de Kubernetes son blancos móviles
Kubernetes realiza la orquestación desplegando contenedores en hosts disponibles. Esto distribuye de forma nativa los componentes de aplicaciones en hosts diferentes, lo que impide saber por adelantado el destino del componente.
Los contenedores que se ejecutan en pods de Kubernetes producen logs como stdout o stderr. Estos logs se escriben en una ubicación conocida para kubelet como archivos con la ID del pod como nombre. Para vincular los logs al componente o pod que los produce, los usuarios deben averiguar cuáles pods de componentes se ejecutan en el host actual y sus ID.
Agregando más complejidad, Kubernetes puede decidir escalar la aplicación horizontalmente y, como resultado, puede cambiar el conteo de pods que representa el componente de aplicaciones.
Afortunadamente, a Filebeat le encantan los blancos móviles
Todo lo que necesitamos para recopilar logs de pods es Filebeat ejecutándose como DaemonSet en nuestro cluster de Kubernetes. Se puede configurar Filebeat para comunicarse con la API de kubelet local, obtener la lista de pods que se ejecutan en el host actual y recopilar los logs que están produciendo los pods. En estos logs están las anotaciones de todos los metadatos de Kubernetes relevantes, como ID del pod, nombre del contenedor, etiquetas y anotaciones del contenedor, etc.
Filebeat usa estas anotaciones para descubrir el tipo de componentes que se ejecuta en el pod y poder decidir cuál módulo de logging aplicar a los logs que está procesando. ¡Mira qué fácil! Ingestar logs de Kubernetes con Filebeat es muy fácil. Estamos a punto de comenzar, solo una observación rápida (y larga) antes de hacerlo:
| Antes de comenzar: para el siguiente tutorial debes tener un entorno de Kubernetes configurado. Creamos un blog complementario en el cual se te guía por el proceso de configurar un entorno Minikube de un solo nodo con una aplicación de muestra para ejecutar el resto de las actividades. |
Recopilar logs de Kubernetes con Filebeat
Usaremos Elasticsearch Service en Elastic Cloud. Sin embargo, todo lo que se describe aquí puede funcionar con clusters de Elastic desplegados en tu propia infraestructura, ya sea que tú autogestiones o uses sistemas de orquestación como Elastic Cloud Enterprise (ECE) o Elastic Cloud en Kubernetes (ECK). El código para este tutorial está disponible en el siguiente repositorio de GitHub: http://github.com/michaelhyatt/k8s-o11y-workshop.
Desplegar Filebeat como DaemonSet
Solo se debería desplegar una instancia de Filebeat por host de Kubernetes. Una vez desplegada, Filebeat se comunica con el host a través de la API de kubelet para recuperar la información sobre los pods que se están ejecutando, todas las anotaciones de metadatos y la ubicación de los archivos de log.
La configuración de despliegue de DaemonSet está definida en el archivo $HOME/k8s-o11y-workshop/filebeat/filebeat.yml. Veamos en más detalle la parte que describe el despliegue y representa la configuración de Filebeat.
Esta parte aumenta la cantidad general de campos posibles de 1000 (predeterminado) a 5000. Los despliegues de Kubernetes pueden introducir una gran cantidad de etiquetas y anotaciones que resulten en campos de esquemas que pueden superar el valor predeterminado 1000.
setup.template.settings:
index.mapping.total_fields.limit: 5000
Las configuraciones para el mecanismo de autodescubrimiento indican a Filebeat que use el autodescubrimiento de Kubernetes y confíe en el autodescubrimiento impulsado por sugerencias que funciona con base en las anotaciones.
filebeat.autodiscover:
providers:
- type: kubernetes
host: ${NODE_NAME}
hints.enabled: true
En la siguiente sesión se define la cadena de procesadores que se aplicará a todos los logs capturados por esta instancia de Filebeat. Primero, enriquecerá el evento con los metadatos que provienen de Docker, Kubernetes, el host y los Proveedores Cloud. Después, hay una sección drop_event que filtra los mensajes según el contenido y algunos campos de metadatos que crearon los procesadores anteriores. Esto es útil cuando hay un tipo de evento con ruido que domina los logs. Observa la forma lógica en la que se usan and y or para construir la condición de coincidencia.
processors:
- add_cloud_metadata:
- add_host_metadata:
- add_docker_metadata:
- add_kubernetes_metadata:
- drop_event:
when:
or:
- contains:
message: "OpenAPI AggregationController: Processing item k8s_internal_local_delegation_chain"
- and:
- equals:
kubernetes.container.name: "metricbeat"
- contains:
message: "INFO"
- contains:
message: "Non-zero metrics in the last"
- and:
- equals:
kubernetes.container.name: "packetbeat"
- contains:
message: "INFO"
- contains:
message: "Non-zero metrics in the last"
- contains:
message: "get services heapster"
- contains:
kubernetes.container.name: "kube-addon-manager"
- contains:
kubernetes.container.name: "dashboard-metrics-scraper"
Los módulos de Filebeat y el autodescubrimiento usando anotaciones
Antes vimos cómo el autodescubrimiento hará que se aplique el módulo adecuado a stdout/stderr para parsearlos como un formato específico del módulo. Conoce más sobre el autodescubrimiento en los documentos de Filebeat.
Ahora, veamos cómo están configurados los diferentes componentes de nuestra aplicación de muestra para funcionar con el autodescubrimiento basado en sugerencias de Kubernetes.
Ejemplo de NGINX
Este es el fragmento de código de $HOME/k8s-o11y-workshop/nginx/nginx.yml que le indica a Filebeat que trate los logs de este pod como logs de NGINX, donde stdout representa el log de acceso y stderr representa el log de errores:
annotations:
co.elastic.logs/module: nginx
co.elastic.logs/fileset.stdout: access
co.elastic.logs/fileset.stderr: error
Manejar logs de aplicaciones multilínea
Otro ejemplo de autodescubrimiento basado en sugerencias es configurar Filebeat para que trate las entradas de log multilínea de petclinic como un solo evento de logs. Esto es útil cuando los componentes registran mensajes multilínea, como rastreos de la pila de Java que representan un solo evento, pero de forma predeterminada se tratarán como un solo evento por línea delimitado por el final de la línea.
Este es un fragmento de $HOME/k8s-o11y-workshop/petclinic/petclinic.yml que representa la configuración para tratar eventos multilínea que Filebeat comprende usando autodescubrimiento basado en sugerencias:
annotations:
co.elastic.logs/multiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
co.elastic.logs/multiline.negate: "true"
co.elastic.logs/multiline.match: "after"
Conoce más sobre cómo tratar eventos multilínea en los documentos de Filebeat.
Análisis de logs de Kubernetes en el Elastic Stack
Ahora que los logs están ingestados en Elasticsearch, es momento de hacer buen uso de ellos.
Uso de la app Logs en Kibana
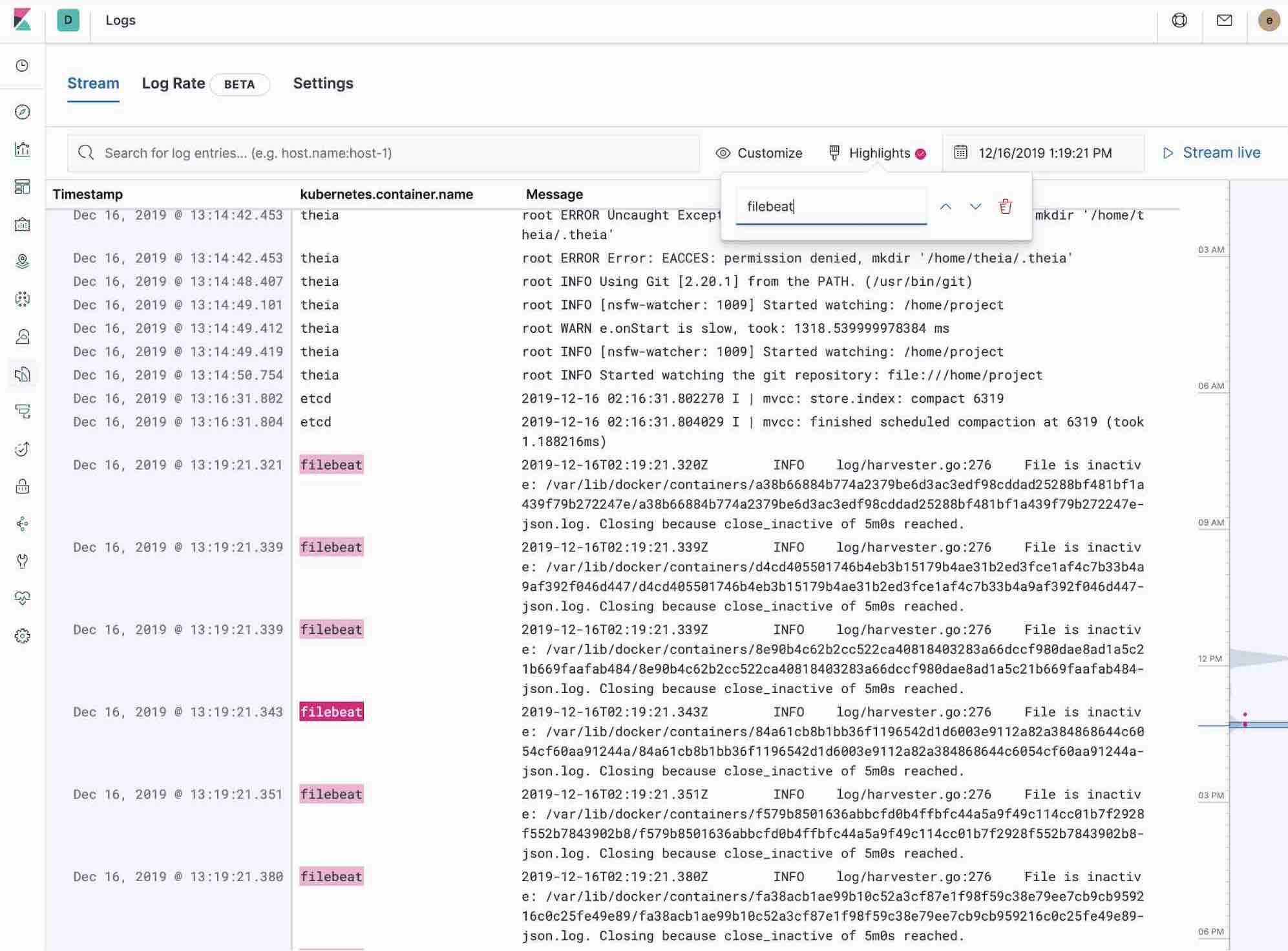
La app Logs en Kibana te permite buscar, filtrar y seguir el final de todos los logs recopilados en el Elastic Stack. En lugar de tener que usar ssh para acceder a distintos servidores y cd para acceder al directorio y seguir el final de archivos individuales, todos los logs están disponibles en una herramienta en la app Logs.
- Echa un vistazo al filtrado de logs usando la búsqueda de texto sin formato o palabra clave.
- Puedes avanzar y retroceder usando el selector de tiempo o la vista de línea de tiempo en el lateral.
- Si solo quieres ver los logs actualizarse al estilo tail -f, haz clic en el botón Streaming y usa el resaltador para destacar esa porción importante de información que deseas ver.
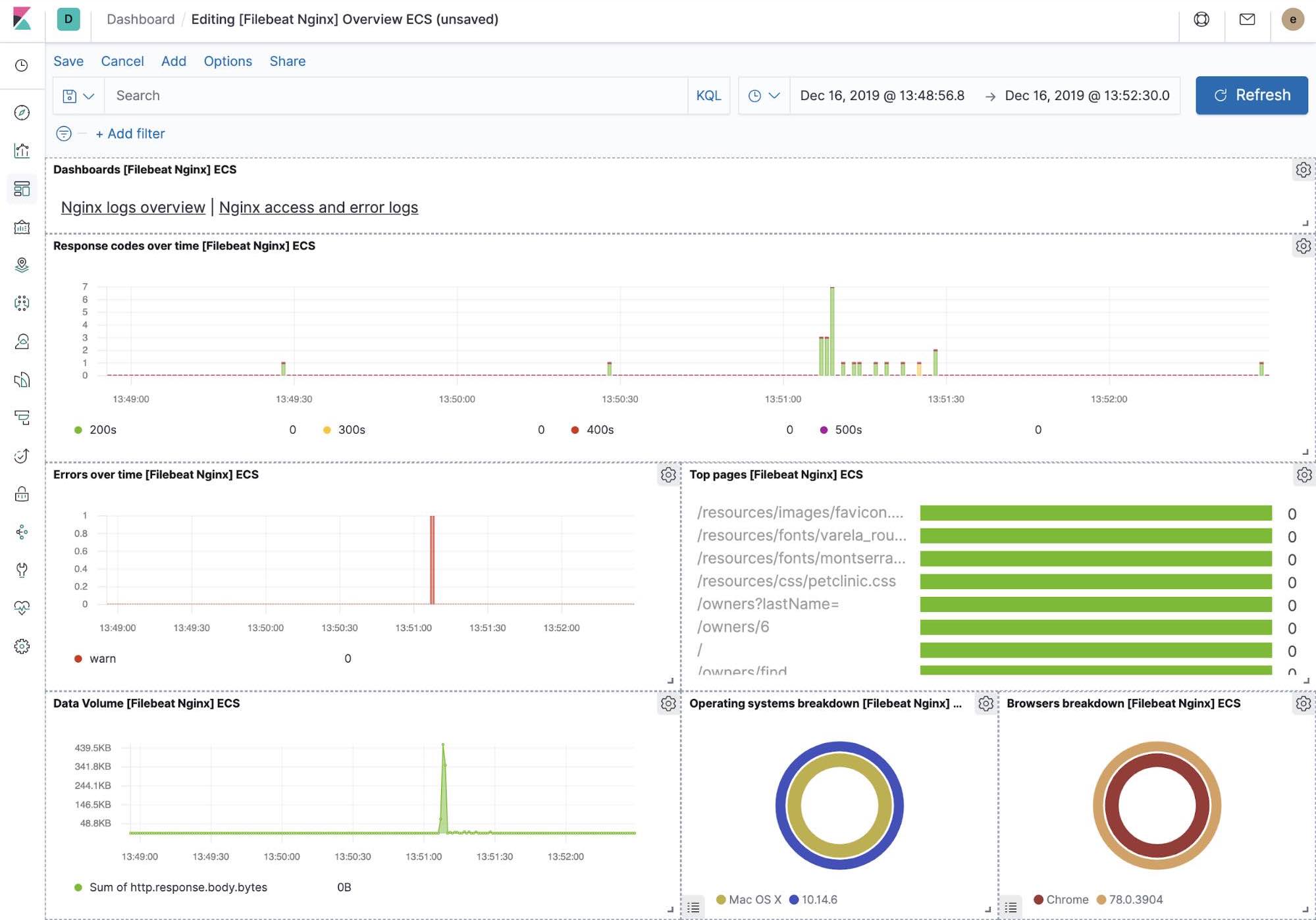
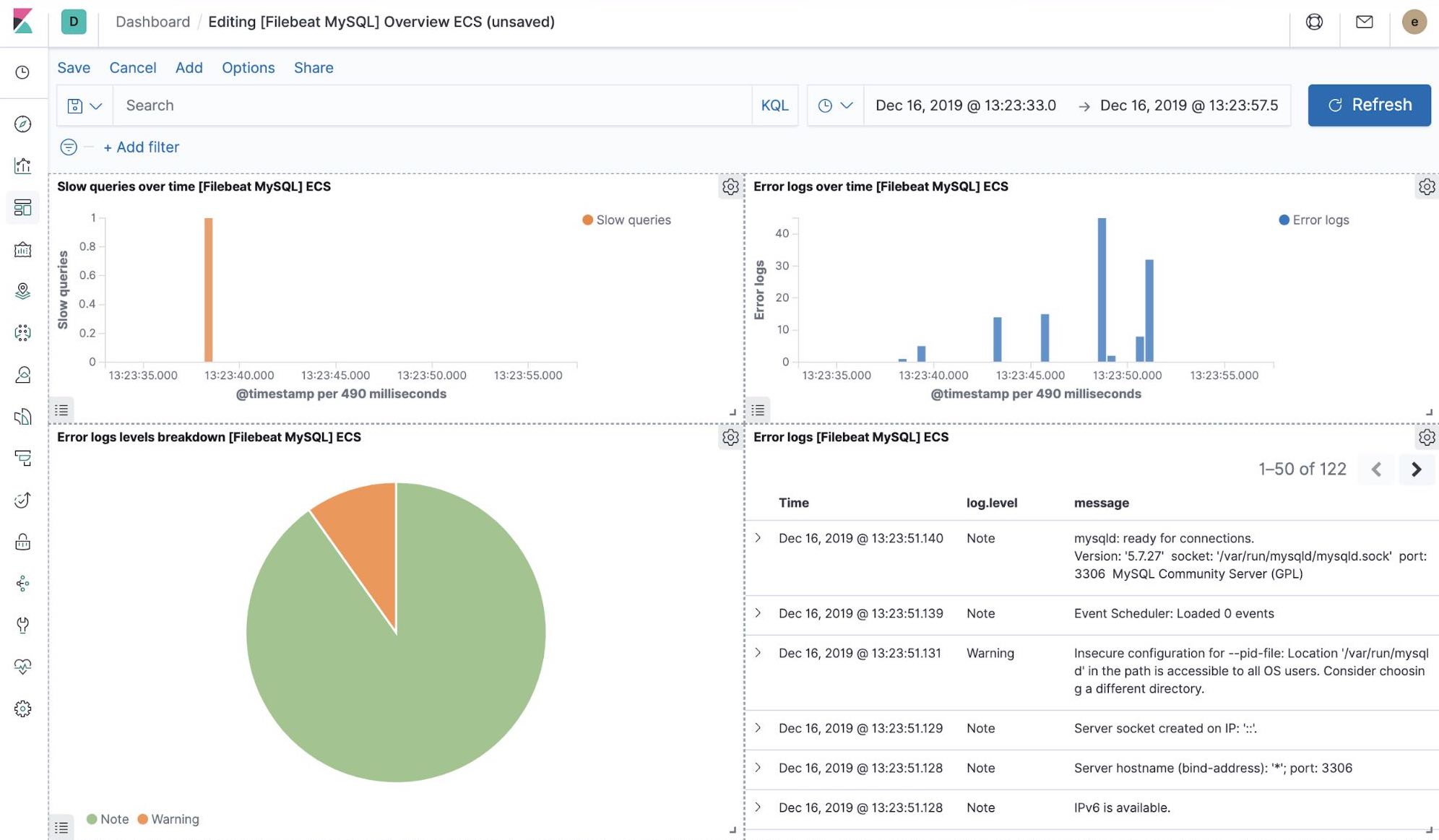
Visualizaciones de Kibana listas para usar
Cuando ejecutamos el trabajo filebeat-setup, entre otros, se creó de forma preliminar un conjunto de dashboards listos para usar en Kibana. Una vez que nuestra aplicación petclinic de muestra se haya desplegado, podemos navegar a los dashboards listos para usar de Filebeat para MySQL y NGINX, y ver que los módulos de Filebeat no solo capturan logs, sino que también pueden capturar métricas que registran los componentes. Habilitar estas visualizaciones requiere ejecutar los componentes MySQL y NGINX de la aplicación de ejemplo.
Machine Learning y detección de anomalías de logging
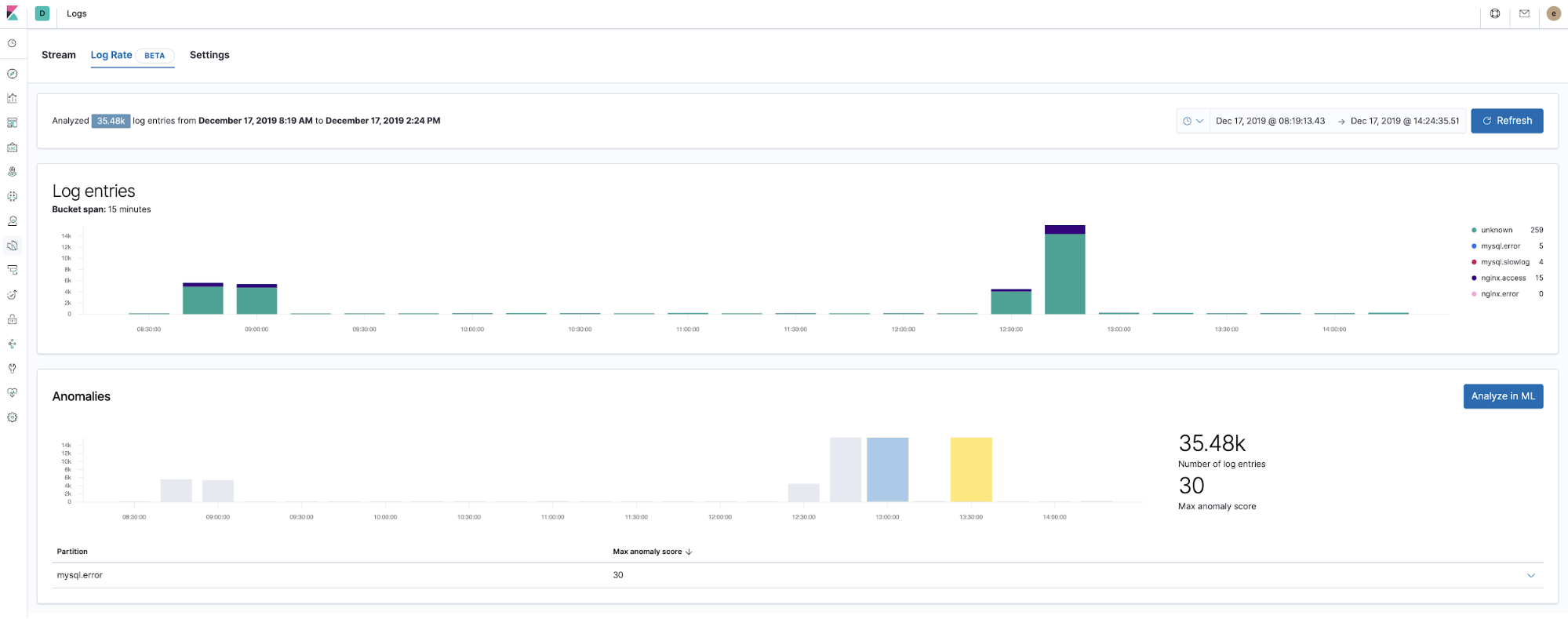
A partir de la versión 7.5, el Elastic Stack puede detectar anomalías en la tasa de logs de los componentes de las aplicaciones. Esto se puede usar para detectar eventos como los siguientes:
- Se acaba de incorporar una fuente de logs o aplicación nuevas.
- La actividad de logging aumentó de forma repentina debido a una promoción (o un ataque).
- El envío de logs se detuvo de repente, quizá debido al mal funcionamiento de un pipeline de ingesta o agente.
Presentamos la característica de anomalías de la tasa de logs en la app Logs, lo que permite a los operadores obtener una respuesta instantánea a las preguntas anteriores. Habilítala con un solo clic en la app Logs.
Detección de entradas desconocidas con clasificación de entradas de logs
Otra aplicación útil de Machine Learning relacionada con los logs es detectar entradas de tipo log nuevas que no se observaron antes. En el nivel más alto, Machine Learning fragmenta todas las partes numéricas y variables de las entradas de log, como marcas de tiempo, valores numéricos, etc., captura lo que queda y realiza la categorización de las partes fijas de las entradas registradas. Después, intenta agruparlas en cubetas y continúa identificando cubetas nuevas que aparecen como anomalías que representan las entradas de log que no se vieron antes.

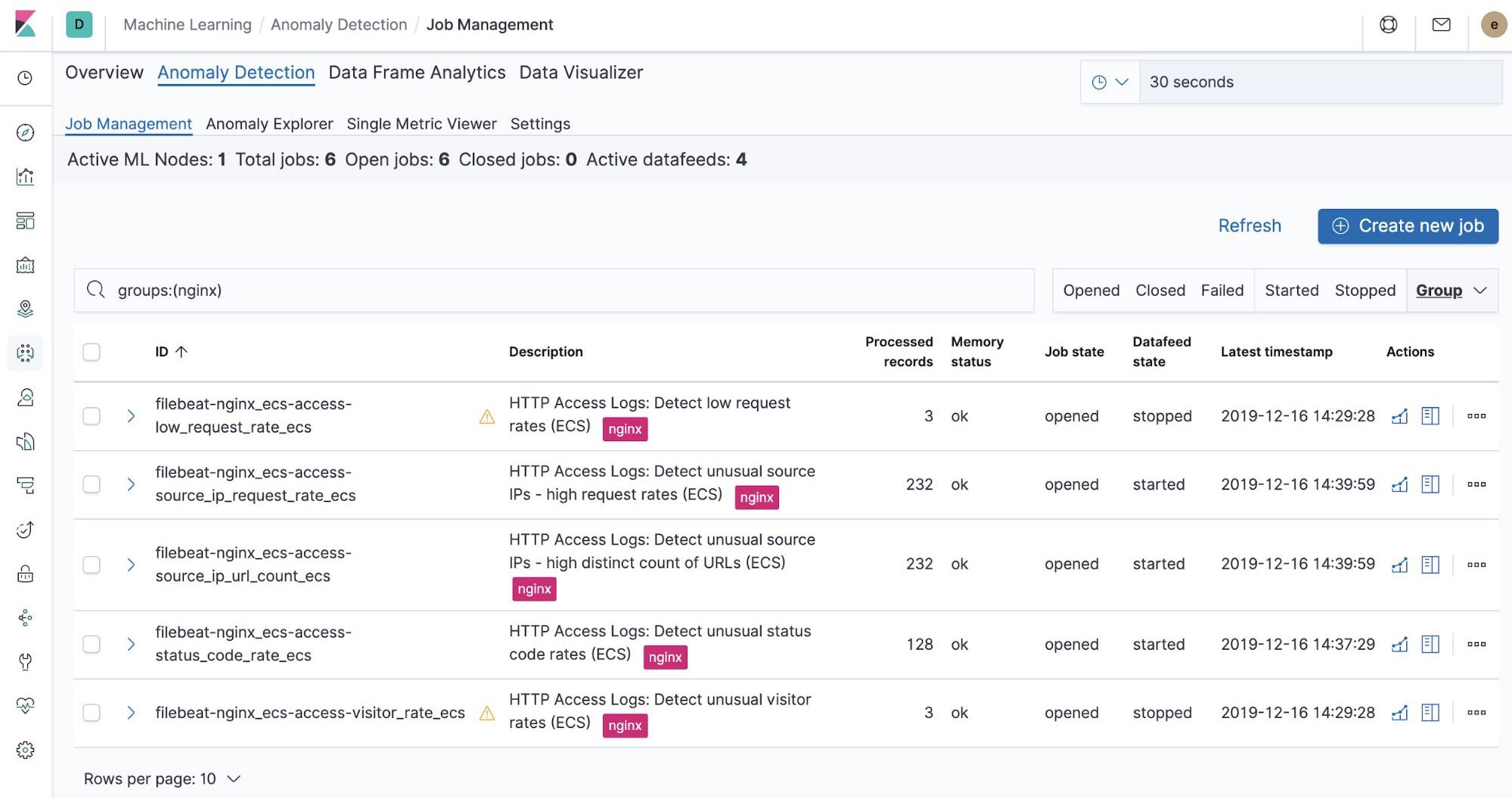
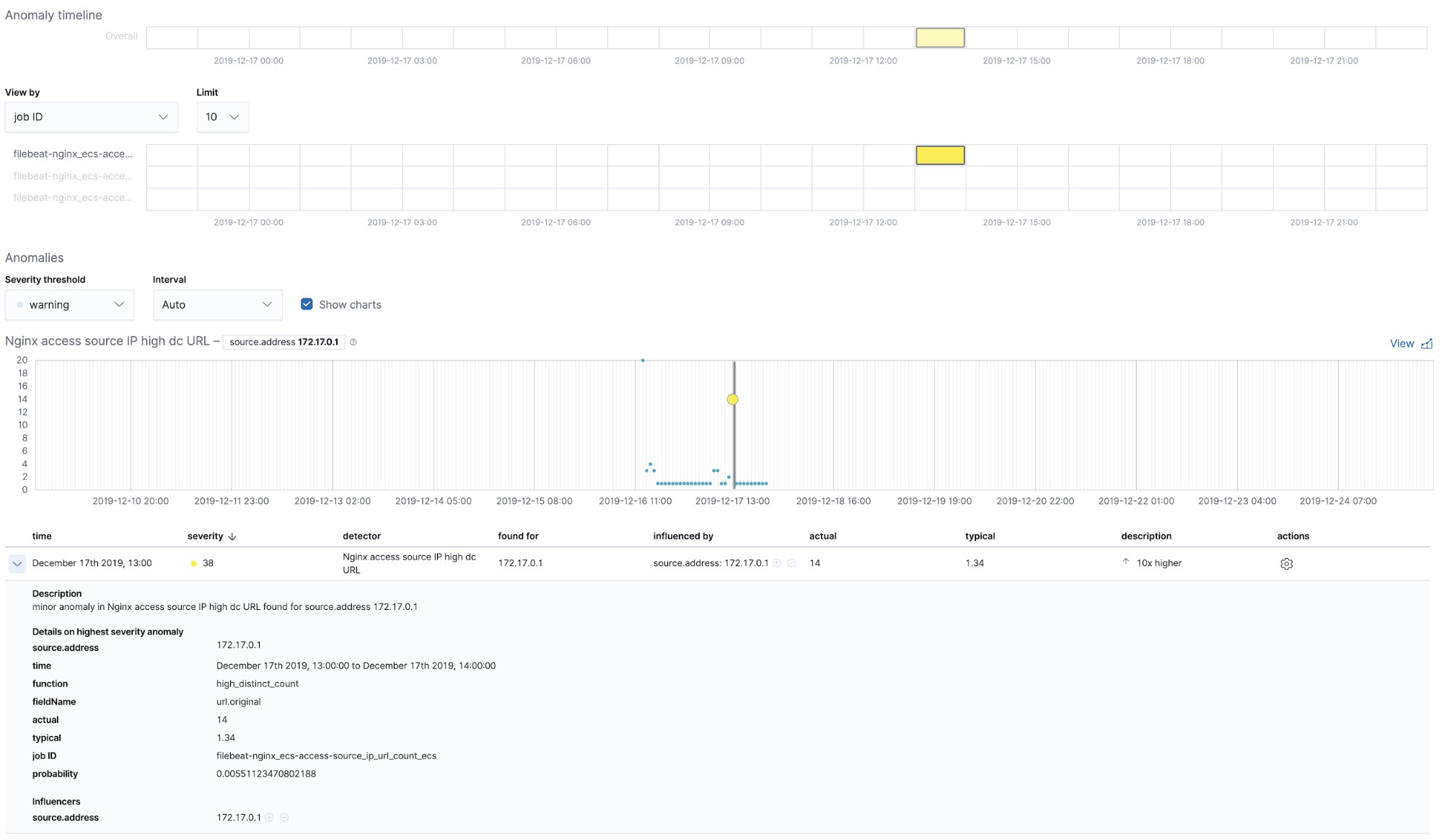
Trabajos de Machine Learning listos para usar: NGINX
En el momento en que ejecutamos el trabajo filebeat-setup, se crearon de forma preliminar los trabajos de Machine Learning listos para usar. Si están activados, pueden comenzar a detectar anomalías en los datos stdout y stderr de NGINX ingestados desde Filebeat.
Resumen
En esta parte, ingestamos logs de Kubernetes en el Elastic Stack usando Filebeat y sus módulos. Puedes comenzar a monitorear tus sistemas e infraestructura hoy registrándote para una prueba gratuita de Elasticsearch Service en Elastic Cloud o descargando el Elastic Stack y hospedándolo tú mismo. Una vez en marcha, monitorea la disponibilidad de tus hosts con Elastic Uptime e instrumenta las aplicaciones que se ejecutan en tus hosts con Elastic APM. Estarás camino a un sistema completamente observable, integrado por completo con tu cluster de métricas nuevas. Si encuentras algún obstáculo o tienes preguntas, visita nuestros foros de debate; estamos aquí para ayudarte.
A continuación: Métricas de estado y rendimiento de recopilación