Cómo desplegar NLP: Ejemplo de reconocimiento de entidades con nombre (NER)


 Share on Twitter
Share on TwitterComparte en Twitter

 Share on LinkedIn
Share on LinkedInComparte en LinkedIn

 Share on Facebook
Share on FacebookComparte en Facebook

 Share by Email
Share by EmailComparte por correo electrónico

 Print this page
Print this pageImprime
Como parte de nuestra serie de varias entradas sobre el procesamiento de lenguaje natural (NLP), analizaremos un ejemplo utilizando un modelo de NLP de reconocimiento de entidades con nombre (NER) para ubicar y extraer categorías predefinidas de entidades en campos de texto no estructurados. Usando un modelo disponible públicamente, te mostraremos cómo desplegar ese modelo en Elasticsearch, encontrar entidades con nombre en texto con la nueva API de _infer y utilizar el modelo de NER en un pipeline de ingesta para extraer entidades a medida que se ingestan documentos en Elasticsearch.
Los modelos de NER son útiles para utilizar el lenguaje natural a fin de extraer entidades como personas, lugares y organizaciones de campos de texto completos.
En este ejemplo, analizaremos párrafos del libro Los miserables con un modelo de NER y utilizaremos el modelo para extraer los personajes y lugares del texto, así como visualizar las relaciones entre ellos.
Cómo desplegar un modelo de NER en Elasticsearch
En primer lugar, tenemos que seleccionar un modelo de NER que pueda extraer de los campos de texto los nombres de los personajes y las ubicaciones. Afortunadamente, hay varios modelos de NER disponibles en Hugging Face entre los que podemos elegir, y revisando la documentación de Elastic, vemos uno para un modelo de NER de Elastic no sensible a las letras mayúsculas que podemos probar.
Ahora que seleccionamos el modelo de NER que usaremos, podemos utilizar Eland para instalar el modelo. En este ejemplo, ejecutaremos el comando Eland a través de una imagen de Docker, pero primero debemos compilar la imagen de Docker clonando el repositorio de GitHub de Eland y, luego, crear una imagen de Docker de Eland en tu sistema cliente:
git clone [email protected]:elastic/eland.git
cd eland
docker build -t elastic/eland .
Ahora que está listo nuestro cliente docker eland, podemos instalar el modelo de NER ejecutando el comando eland_import_hub_model en la nueva imagen de Docker con el siguiente comando:
docker run -it --rm elastic/eland \
eland_import_hub_model \
--url $ELASTICSEARCH_URL \
--hub-model-id elastic/distilbert-base-uncased-finetuned-conll03-english \
--task-type ner \
--startDeberás reemplazar ELASTICSEACH_URL por la URL de tu cluster de Elasticsearch. Para fines de autenticación, deberás incluir un nombre de usuario y una contraseña de administrador en la URL con el formato https://username:password@host:port.
Como usamos la opción --start al final del comando eland import, Elasticsearch desplegará el modelo en todos los nodos disponibles de machine learning y cargará el modelo en la memoria. Si tuviéramos varios modelos y quisiéramos seleccionar qué modelo desplegar, podríamos usar la interfaz de usuario Machine Learning > Model Management (Administración de modelos) de Kibana para gestionar el inicio y la detención de los modelos.
Cómo probar el modelo de NER
Los modelos desplegados pueden evaluarse mediante la nueva API de _infer. La entrada es el texto que queremos analizar. En la solicitud de abajo, text_field es el nombre del campo donde el modelo espera encontrar la entrada, como se define en la configuración del modelo. De forma predeterminada, si el modelo se cargó a través de Eland, el campo de entrada es text_field.
Prueba este ejemplo en la consola de herramientas para desarrolladores de Kibana:
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_infer
{
"docs": [
{
"text_field": "Hi my name is Josh and I live in Berlin"
}
]
}
El modelo encontró dos entidades: la persona "Josh" y el lugar "Berlín".
{
"predicted_value" : "Hi my name is [Josh](PER&Josh) and I live in [Berlin](LOC&Berlin)",
"entities" : {
"entity" : "Josh",
"class_name" : "PER",
"class_probability" : 0.9977303419824,
"start_pos" : 14,
"end_pos" : 18
},
{
"entity" : "Berlin",
"class_name" : "LOC",
"class_probability" : 0.9992474323902818,
"start_pos" : 33,
"end_pos" : 39
}
]
}
predicted_value es el texto de entrada en formato de texto anotado, class_name es la clase predicha y class_probability indica el nivel de confianza en la predicción. start_pos y end_pos son las posiciones del carácter inicial y final de la entidad identificada.
Cómo agregar el modelo de NER a un pipeline de ingesta de inferencia
La API de _infer es una forma divertida y fácil de empezar, pero solo acepta una única entrada, y las entidades detectadas no se almacenan en Elasticsearch. Una alternativa es realizar una inferencia masiva en los documentos a medida que se ingestan a través de un pipeline de ingesta con el procesador de inferencia.
Puedes definir un pipeline de ingesta en la UI de Stack Management o configurarlo en la consola de Kibana, que contiene varios procesadores de ingesta:
PUT _ingest/pipeline/ner
{
"description": "NER pipeline",
"processors": [
{
"inference": {
"model_id": "elastic__distilbert-base-uncased-finetuned-conll03-english",
"target_field": "ml.ner",
"field_map": {
"paragraph": "text_field"
}
}
},
{
"script": {
"lang": "painless",
"if": "return ctx['ml']['ner'].containsKey('entities')",
"source": "Map tags = new HashMap(); for (item in ctx['ml']['ner']['entities']) { if (!tags.containsKey(item.class_name)) tags[item.class_name] = new HashSet(); tags[item.class_name].add(item.entity);} ctx['tags'] = tags;"
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{ _index }}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
Empezando por el procesador inference, el propósito de field_map es mapear paragraph (el campo que se analizará en los documentos fuente) a text_field (el nombre del campo que el modelo está configurado para usar). target_field es el nombre del campo en el que se deben escribir los resultados de la inferencia.
El procesador script extrae las entidades y las agrupa por tipo. El resultado final son listas de personas, lugares y organizaciones detectadas en el texto de entrada. Agregaremos este script painless para que podamos compilar visualizaciones a partir de los campos que se crean.
La cláusula on_failure está ahí para detectar errores. Define dos acciones. En primer lugar, establece el campo meta _index con un nuevo valor, y el documento ahora se almacenará allí. En segundo lugar, el mensaje de error se escribe en un nuevo campo: ingest.failure. La inferencia puede fallar debido a una serie de razones fácilmente solucionables. Puede que el modelo no se haya desplegado o que falte el campo de entrada en alguno de los documentos fuente. Al redirigir los documentos fallidos a otro índice y establecer el mensaje de error, esas inferencias fallidas no se pierden y pueden ser revisadas posteriormente. Una vez solucionados los errores, vuelve a indexar desde el índice fallido para recuperar las solicitudes con error.
Cómo elegir los campos de texto para la inferencia
El NER puede aplicarse a muchos sets de datos. A modo de ejemplo, elegí la clásica novela de Victor Hugo de 1862 Los miserables. Puedes subir los párrafos de Los miserables de nuestro archivo json de ejemplo utilizando la función de carga de archivos de Kibana. El texto se divide en 14 021 documentos JSON, cada uno de los cuales contiene un único párrafo. Tomemos un párrafo al azar como ejemplo:
{
"paragraph": "Father Gillenormand did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"line": 12700
}
Una vez que el párrafo se ingesta a través del pipeline de NER, el documento resultante almacenado en Elasticsearch se marca con una persona identificada.
{
"paragraph": "Father Gillenormand did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"@timestamp": "2020-01-01T17:38:25",
"line": 12700,
"ml": {
"ner": {
"predicted_value": "Father [Gillenormand](PER&Gillenormand) did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"entities": [{
"entity": "Gillenormand",
"class_name": "PER",
"class_probability": 0.9806354093873283,
"start_pos": 7,
"end_pos": 19
}],
"model_id": "elastic__distilbert-base-cased-finetuned-conll03-english"
}
},
"tags": {
"PER": [
"Gillenormand"
]
}
}
Un cloud de etiquetas es una visualización que escala las palabras según la frecuencia con la que aparecen y es la infografía perfecta para ver las entidades que se encuentran en Los miserables. Abre Kibana, crea una nueva visualización basada en agregaciones y luego elige Tag Cloud (Cloud de etiquetas). Selecciona el índice que contiene los resultados del NER y añade una agregación de términos en el campo tags.PER.keyword.
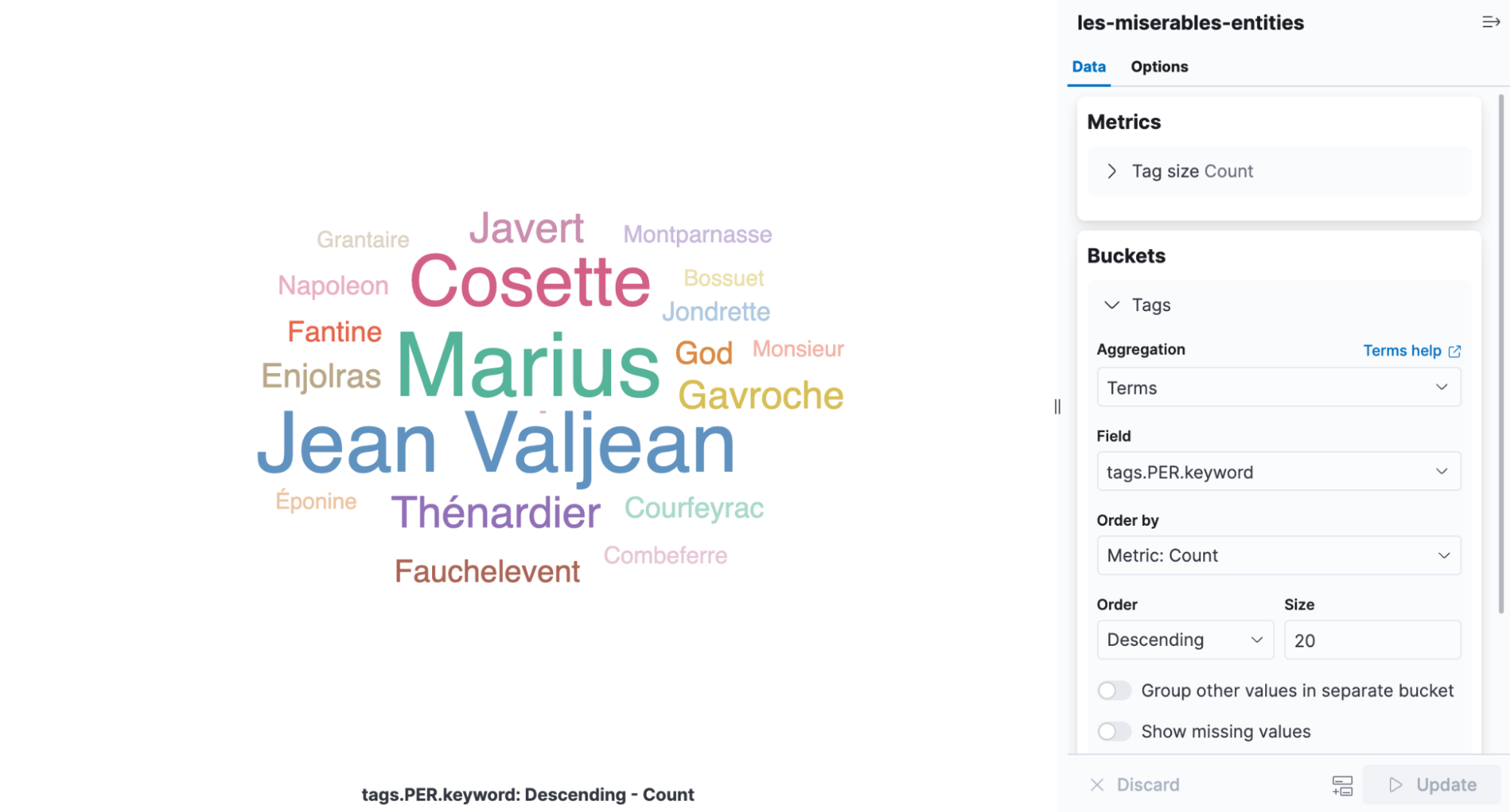
Es fácil apreciar en la visualización que Cosette, Marius y Jean Valjean son los personajes más mencionados en el libro.
Cómo ajustar el despliegue
Volviendo a la UI de Model Management (Administración de modelos), en Deployment stats (Estadísticas de despliegue), encontrarás Avg Inference Time (Tiempo medio de inferencia). Es el tiempo que mide el proceso nativo para realizar la inferencia en una sola solicitud. Al iniciar un despliegue, hay dos parámetros que controlan cómo se utilizan los recursos de la CPU: inference_threads y model_threads.
inference_threads es el número de subprocesos usados para ejecutar el modelo por solicitud. Aumentar inference_threads reduce directamente el tiempo medio de inferencia. La cantidad de solicitudes que se evalúan en paralelo se controla con model_threads. Esta configuración no reduce el tiempo medio de inferencia, pero aumenta el rendimiento.
En general, hay que ajustar la latencia aumentando el número de inference_threads y aumentar el rendimiento elevando el número de model_threads. Ambas configuraciones son las predeterminadas de un subproceso, por lo que se puede ganar mucho rendimiento modificándolas. El efecto se demuestra usando el modelo de NER.
Para cambiar una de las configuraciones de los subprocesos, se debe detener y reiniciar el despliegue. El parámetro ?force=true se pasa a la API de detención porque el despliegue está referenciado por un pipeline de ingesta que normalmente impediría la detención.
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_stop?force=true
Y reiniciar con cuatro subprocesos de inferencia. El tiempo medio de inferencia se restablece cuando se reinicia el despliegue.
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_start?inference_threads=4Al procesar los párrafos de Los miserables, el tiempo medio de inferencia desciende a 55.84 milisegundos por solicitud, frente a los 173.86 milisegundos de un subproceso.
Más información y pruebas
El NER es solo una de las tareas de NLP que se pueden utilizar ahora. También están disponibles la clasificación de textos, la clasificación de tomas cero y las incrustaciones de textos. Se pueden encontrar más ejemplos en la documentación de NLP junto con una lista para nada exhaustiva de modelos desplegables en Elastic Stack.
El NLP es una nueva e importante característica de Elastic Stack para la versión 8.0 con un emocionante roadmap. Descubre características nuevas y mantente al tanto de los desarrollos más recientes creando tu cluster en Elastic Cloud. Suscríbete para una prueba gratuita de 14 días hoy y prueba los ejemplos de este blog.
Si deseas conocer más sobre NLP, lee:
Comparte
- Share on Twitter
Comparte en Twitter
- Share on LinkedIn
Comparte en LinkedIn
- Share on Facebook
Comparte en Facebook
- Share by Email
Comparte por correo electrónico
- Print this page
Imprime

