Análisis a fondo del almacenamiento en caché en Elasticsearch: Impulsar la velocidad de búsqueda, una memoria caché a la vez
La memoria caché manda en la recuperación rápida de datos. Si te interesa conocer cómo Elasticsearch aprovecha varias memorias caché para garantizar que recuperas los datos lo más rápido posible, ponte cómodo para los próximos 15 minutos y lee este blog. Aquí aclararemos las características del almacenamiento en varias memorias caché de Elasticsearch que te ayudan a recuperar los datos más rápido después de los accesos iniciales a los datos. Elasticsearch recurre mucho al uso de varias memorias caché, pero en este blog nos enfocaremos solo en lo siguiente:
- Memoria caché de páginas (a veces llamada "memoria caché de sistema de archivos")
- Memoria caché de solicitud a nivel de shard
- Memoria caché de búsqueda
Verá qué hace cada una de estas memorias caché, cómo funciona y cuál es la mejor en cada caso de uso. También analizaremos cómo algunas veces puedes controlar el almacenamiento en caché y otras debes confiar en que algún componente haga un buen trabajo en cuanto a ello.
Además, echaremos un vistazo a cómo las memorias caché de páginas manejan la caducidad de los datos. Algo que nunca querrás encontrar es una memoria caché que devuelva datos caducados; debe estar vinculada al ciclo de vida de los datos. Veremos cómo funciona esto en cada caso.
Si te preguntas si este blog se aplica en tu caso: no importa si ejecutas Elasticsearch por tu cuenta o usas Elastic Cloud, usarás estas memorias caché desde el comienzo. Bien, comencemos.
Memoria caché de páginas
La primera memoria caché se encuentra a nivel del sistema operativo. Si bien esta sección se enfoca principalmente en la implementación de Linux, otros sistemas operativos tienen una característica similar.
La idea básica de la memoria caché de páginas es colocar los datos en la memoria disponible luego de leerlos desde el disco, así la lectura siguiente se devuelve desde la memoria y no se requiere una búsqueda en el disco para obtener los datos. Todo esto es completamente transparente para la aplicación, que emite las mismas llamadas al sistema, pero el sistema operativo tiene la capacidad de usar la memoria caché de páginas en lugar de leer desde el disco.
Echemos un vistazo a este diagrama, donde la aplicación está ejecutando una llamada al sistema para leer datos desde el disco y el kernel/sistema operativo recurriría al disco para la primera lectura y colocaría los datos en la memoria caché de páginas en la memoria. El kernel podría entonces redirigir una segunda lectura a la memoria caché dentro de la memoria del sistema operativo, lo que resultaría mucho más rápido.
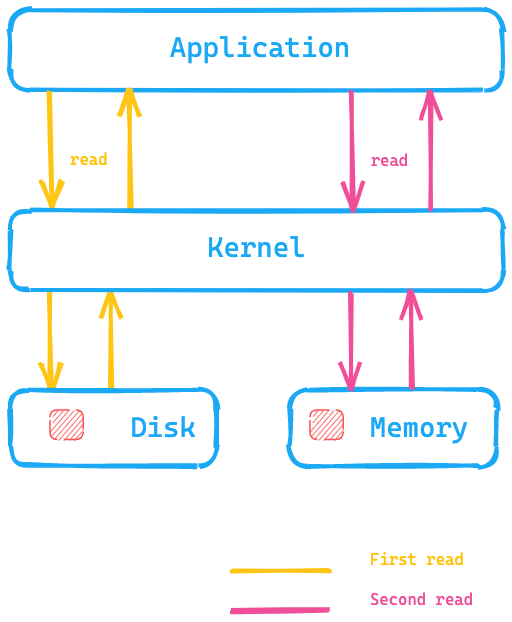
¿Qué significa esto para Elasticsearch? En lugar de acceder a los datos en el disco, la memoria caché de páginas puede resultar mucho más rápida para acceder a los datos. Este es uno de los motivos por los que la recomendación de memoria de Elasticsearch, en general, no supera la mitad de tu memoria disponible total, para que la otra mitad pueda usarse para la memoria caché de páginas. Esto también significa que no se desperdicia memoria; en cambio, se la reutiliza para la memoria caché de páginas.
¿Cómo caducan los datos y se retiran de la memoria caché? Si los datos en sí se modifican, la memoria caché de páginas marca los datos como con modificaciones, y se quitan de la memoria caché de páginas. Como los segmentos con Elasticsearch y Lucene solo se escriben una vez, este mecanismo se adapta muy bien a la manera en que se almacenan los datos. Los segmentos son de solo lectura luego de la escritura inicial, por lo que un cambio de los datos podría ser una fusión o el agregado de datos nuevos. En este caso, se requiere acceder nuevamente al disco. La otra posibilidad es que la memoria se llene. En tal caso, la memoria caché se comportará de forma similar a un LRU como se establece en la documentación del kernel.
Prueba de la memoria caché de páginas
Si deseas probar la funcionalidad de la memoria caché de páginas, podemos usar hyperfine para hacerlo. hyperfine es una herramienta de evaluación comparativa de CLI. Creemos un archivo con un tamaño de 10 MB mediante dd.
dd if=/dev/urandom of=test1 bs=1M count=10
Si deseas ejecutar lo anterior en macOS, usa gdd.
Y asegúrate de que coreutils esté instalado mediante brew.
# para Linux hyperfine --warmup 5 'cat test1 > /dev/null' \ --prepare 'sudo sync; sudo echo 3 > /proc/sys/vm/drop_caches'
# para osx hyperfine --warmup 5 'cat test1 > /dev/null' --prepare 'sudo purge' Benchmark #1: cat test1 > /dev/null Time (mean ± σ): 38.1 ms ± 6.4 ms [User: 1.4 ms, System: 17.5 ms] Range (min … max): 30.4 ms … 50.5 ms 10 runs hyperfine --warmup 5 'cat test1 > /dev/null' Benchmark #1: cat test1 > /dev/null Time (mean ± σ): 3.8 ms ± 0.6 ms [User: 0.7 ms, System: 2.8 ms] Range (min … max): 2.9 ms … 7.0 ms 418 runs
Entonces, es aproximadamente 10 veces más rápido en la instancia de macOS local que ejecuta el mismo comando cat sin borrar la memoria caché de páginas, porque se puede omitir el acceso al disco. Definitivamente querrás este tipo de patrón de acceso para tus datos de Elasticsearch.
En profundidad
La clase responsable de leer un índice Lucene es la clase HybridDirectory. Sobre la base de la extensión de los archivos en un índice Lucene, se debe decidir si usar el mapping de memoria o el acceso convencional a archivos con Java NIO.
También ten en cuenta que algunas aplicaciones son más sensibles a sus propios patrones de acceso y tienen sus propias memorias caché muy específicas y optimizadas, y probablemente la memoria caché de páginas obstaculice esto. De ser necesario, cualquier aplicación puede omitir la memoria caché de páginas con O_DIRECT al abrir un archivo. Regresaremos sobre esto al final de este blog.
Si deseas comprobar la tasa de aciertos de la memoria caché, puedes usar cachestat, parte de perf-tools.
Una última cosa relacionada con Elasticsearch: puedes configurar Elasticsearch para que precargue datos en la memoria caché de páginas a través de la configuración del índice. Considera esta como una configuración para expertos y ten cuidado con ella, asegúrate de que la memoria caché de páginas no falle constantemente.
Resumen
La memoria caché de páginas ayuda a ejecutar búsquedas arbitrarias más rápido cargando estructuras de datos de índice completo en la memoria principal de tu sistema operativo. No hay más granularidad y se debe únicamente al patrón de acceso de tus datos. El sistema operativo se encarga del desalojo.
Pasemos al siguiente nivel de memorias caché.
Memoria caché de solicitud a nivel de shard
Esta memoria caché ayuda mucho a acelerar Kibana con el almacenamiento en caché de las respuestas a búsquedas que consisten únicamente en agregaciones. Superpongamos la respuesta de una agregación con los datos tomados de varios índices para visualizar el problema que resuelve esta memoria caché.
Un dashboard de Kibana en tu oficina generalmente muestra datos de varios índices, y tú simplemente especificas un período como los últimos 7 días. No te interesa cuántos índices o shards se consultan. Entonces, si usas flujos de datos para tus índices basados en el tiempo, puedes obtener una visualización como esta que abarque cinco índices.
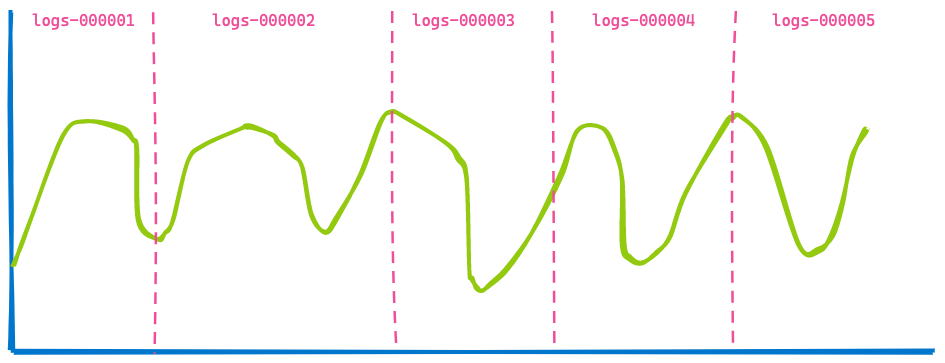
Ahora, avancemos 3 horas hacia adelante, en el mismo dashboard:
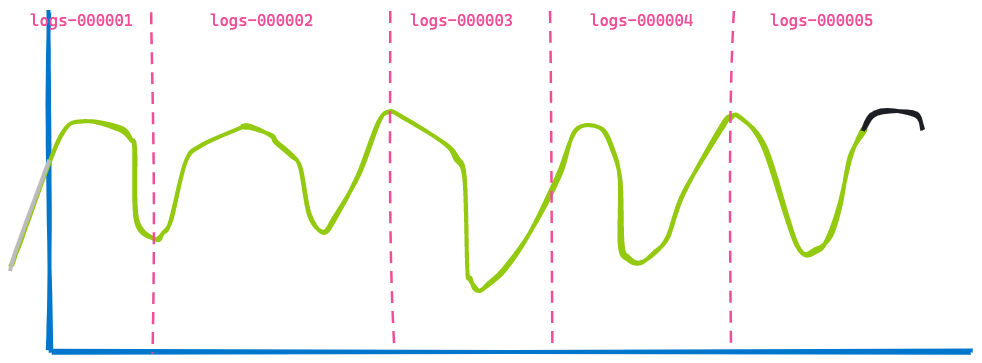
La segunda visualización es muy similar a la primera; algunos datos ya no se muestran porque caducaron (a la izquierda de la línea azul), y otros datos se agregaron al final (línea negra). ¿Puedes identificar lo que no cambió? Los datos devuelto de los índices logs-000002, logs-000003 y logs-000004.
Incluso si estos datos hubieran estado en la memoria caché de páginas, aún así necesitaríamos ejecutar la búsqueda y la agregación sobre los resultados. No es necesario hacer este trabajo dos veces. Para llevar a cabo esta tarea, se agregó una optimización más en Elasticsearch: la capacidad de volver a escribir una búsqueda. En lugar de especificar un intervalo de marcas de tiempo para los índices de logs logs-000002, logs-000003 y logs-000004, podemos volver a escribir esto internamente en una búsqueda match_all dado que cada documento dentro de ese índice coincide en cuanto a la marca de tiempo (por supuesto, también aplicarían otros filtros). Con esta reescritura, ambas solicitudes ahora terminan siendo exactamente la misma solicitud en esos tres índices y, por lo tanto, pueden almacenarse en caché.
Esto se convirtió en la memoria caché de solicitud a nivel de shard. La idea es almacenar en caché la respuesta completa de una solicitud para no tener que ejecutar ninguna búsqueda y, básicamente, poder devolver las respuestas al instante (siempre y cuando los datos no hayan cambiado, para asegurarte de no devolver datos caducados).
En profundidad
El componente responsable de almacenar en la memoria caché es la clase IndicesRequestCache. Este método se usa en SearchService al ejecutar la fase de búsqueda. También hay una comprobación adicional cuando una búsqueda es elegible para el almacenamiento en memoria caché; por ejemplo, las búsquedas que se están perfilando nunca se almacenan en memoria caché para evitar distorsionar los resultados.
Esta memoria caché está habilitada de forma predeterminada, puede aceptar hasta un uno por ciento de la heap total e incluso puede configurarse por solicitud, si lo necesitas. De forma predeterminada, esta memoria caché está habilitada para solicitudes de búsqueda que no devuelven ningún acierto; precisamente lo que es una visualización de Kibana. Sin embargo, también puedes usar esta memoria caché cuando se devuelven aciertos habilitándola a través de un parámetro de solicitud.
Puedes recuperar estadísticas sobre el uso de esta memoria caché a través de lo siguiente:
GET /_nodes/stats/indices/request_cache?human
Resumen
La memoria caché de solicitud a nivel de shard recuerda las respuestas completas a una solicitud de búsqueda y las devuelve si ingresa nuevamente la misma búsqueda sin recurrir al disco o la memoria caché de páginas. Como lo indica su nombre, la estructura de datos está vinculada al shard que contiene los datos y nunca devolverá datos caducados.
Memoria caché de búsqueda
La memoria caché de búsqueda es la última que analizaremos en este blog. Nuevamente, la forma en que funciona esta memoria caché es bastante diferente a las otras. La memoria caché de páginas almacena en caché datos independientemente de cuántos de estos datos se leen realmente de una búsqueda. La memoria caché de búsqueda a nivel de shard almacena en caché los datos cuando se usa una búsqueda similar. La memoria caché de búsqueda es incluso más granular y puede almacenar en caché datos que se reutilizan entre diferentes búsquedas.
Veamos cómo funciona. Imaginemos que buscamos en todos los logs. Puede haber tres usuarios buscando en los datos de este mes. Sin embargo, cada usuario emplea un término de búsqueda distinto:
- El usuario 1 buscó "falla".
- El usuario 2 buscó "Excepción".
- El usuario 3 buscó "pcre2_get_error_message".
Cada búsqueda devuelve resultados diferentes, sin embargo, se encuentran en el mismo período. Aquí es donde entra en juego la memoria caché de búsqueda: puede almacenar en caché solo esa parte de una búsqueda. La idea básica es almacenar en caché información que llega al disco y solo buscar en esos productos. Probablemente tu búsqueda se vea así:
GET logs-*/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"message": "pcre2_get_error_message"
}
}
],
"filter": [
{
"range": {
"@timestamp": {
"gte": "2021-02-01",
"lt": "2021-03-01"
}
}
}
]
}
}
}
En cada búsqueda, la parte de filter permanece igual. Esta es una vista muy simplificada de cómo se ven los datos en un índice invertido. Cada marca de tiempo se mapea a una ID de documento.
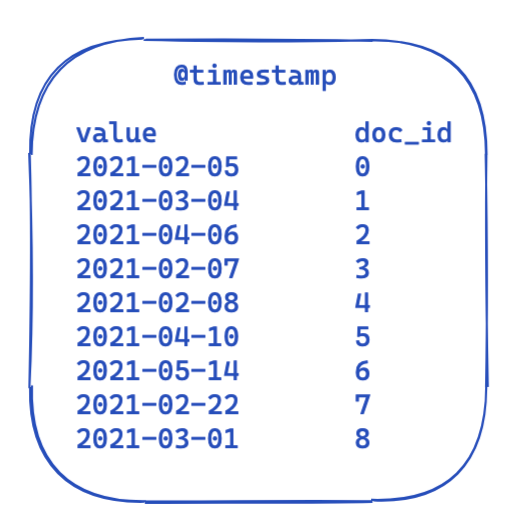
Entonces, ¿cómo se puede optimizar y reutilizar esto en todas las búsquedas? Aquí es donde entran en juego los conjuntos de bits (también llamados "matrices de bits"). Un conjunto de bits es básicamente una matriz en la que cada bit representa un documento. Podemos crear un conjunto de bits dedicado para este filtro @timestamp en particular que abarque un solo mes. Un 0 significa que el documento está fuera de este intervalo, mientras que un 1 significa que está dentro. El conjunto de bits resultante se vería así:
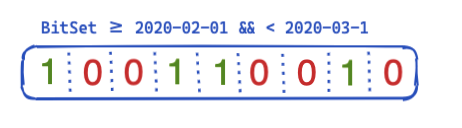
Después de crear este conjunto de bits por segmento (es decir que tendría que recrearse tras una fusión o cuando se crea un segmento nuevo), la búsqueda siguiente no necesita acceder a ningún disco para descartar cuatro documentos incluso antes de ejecutar el filtro. Los conjuntos de bits tienen algunas propiedades interesantes. En primer lugar, pueden combinarse. Si tienes dos filtros y dos conjuntos de bits, puedes descubrir fácilmente los documentos en los que ambos bits están establecidos; o fusionar una búsqueda OR. Otro aspecto interesante de los sets de bits es la compresión. De forma predeterminada, necesitas un bit por documento por filtro. Sin embargo, con el uso de conjuntos de bits no fijados, pero otra implementación como mapas de bit roaring, puedes reducir los requisitos de memoria.
Entonces, ¿cómo se implementa esto en Elasticsearch y Lucene? Echemos un vistazo.
En profundidad
Elasticsearch posee una clase IndicesQueryCache. Esta clase está vinculada al ciclo de vida de IndicesService, lo que significa que no es una característica por índice, sino por nodo; esto tiene sentido, porque la memoria caché en sí usa la heap de Java. Esa memoria caché de búsqueda de índices acepta dos opciones de configuración:
indices.queries.cache.count: la cantidad total de entradas de memoria caché, de manera predeterminada, es 10 000.indices.queries.cache.size: el porcentaje de la heap de Java usado para esta memoria caché, de manera predeterminada, es 10 %.
En el constructor IndicesQueryCache, se configura una ElasticsearchLRUQueryCache nueva. Esta memoria caché se extiende desde la clase LRUQueryCache de Lucene. Esa clase tiene el constructor siguiente:
public LRUQueryCache(int maxSize, long maxRamBytesUsed) {
this(maxSize, maxRamBytesUsed, new MinSegmentSizePredicate(10000, .03f), 250);
}
MinSegmentSizePredicate se asegura de que solo los segmentos con al menos 10 000 documentos sean elegibles para almacenamiento en caché y tengan más del 3 % del total de documentos de este shard.
Sin embargo, a partir de aquí se vuelve un poco más complejo. Aunque los datos se encuentran en la heap de JVM, hay otro mecanismo que hace un seguimiento de las partes de búsqueda más comunes y solo coloca esas en dicha memoria caché. Este seguimiento, sin embargo, sucede a nivel del shard. Hay una clase UsageTrackingQueryCachingPolicy que usa un FrequencyTrackingRingBuffer (implementada con matrices números enteros de tamaño fijo). Esta política de almacenamiento en caché también tiene reglas adicionales en su método shouldNeverCache, que previene el almacenamiento en caché de ciertas búsquedas como búsquedas de términos, búsquedas de coincidir todo/no documentos, o búsquedas vacías, dado que son lo suficientemente rápidas sin almacenamiento en caché. También está la condición de que la frecuencia mínima sea elegible para el almacenamiento en caché, de modo que una sola invocación no provoque que se complete la memoria caché. Puedes hacer un seguimiento del uso, las tasas de aciertos de la memoria caché y otra información a través de lo siguiente:
GET /_nodes/stats/indices/query_cache?human
Resumen
La memoria caché de búsqueda llega al siguiente nivel granular y puede reutilizarse en todas las búsqueda. Con su heurística integrada, solo almacena en caché filtros que se usan varias veces y también decide según el filtro si vale la pena almacenar en caché o si las formas existentes de buscar son lo suficientemente rápidas para evitar desperdiciar memoria heap. El ciclo de vida de esos conjuntos de bits está vinculado al ciclo de vida de un segmento para evitar que se devuelvan datos caducados. Una vez que un segmento nuevo está en uso, se necesita crear un conjunto de bits nuevo.
¿Las memorias caché son la única forma de acelerar las cosas?
Depende (ya sabías que esta respuesta aparecería en el blog en algún momento, ¿no?). Hay un desarrollo reciente en el kernel de Linux que es bastante prometedor: io_uring. Es una forma nueva de realizar E/S asíncrona en Linux usando las colas de finalización disponibles desde Linux 5.1. Ten en cuenta que io_uring aún está en pleno desarrollo. Sin embargo, hay algunos primeros intentos en el mundo de Java de usar io_uring, como netty. Las pruebas de rendimiento de aplicaciones simples se ven asombrosas. Tal vez debemos esperar un poco para ver las métricas de rendimiento en el mundo real, aunque se espera que también tengan cambios importantes. Esperemos que en algún punto haya soporte disponible para esto en JDK también. Hay planes de brindar soporte para io_uring como parte de Project Loom, que puede incorporar io_uring a JVM. Hay otras optimizaciones como poder sugerir el patrón de acceso al kernel de Linux a través de madvise() que todavía no se expusieron en JVM. Esta sugerencia evita un problema de lectura por anticipado, en la que el kernel intenta leer más datos de los necesarios antes de la siguiente lectura, lo cual es inútil cuando se requiere acceso aleatorio.
Eso no es todo. Los desarrolladores de Lucene siempre están intentando aprovechar al máximo todos los sistemas. Hay un primer borrador de una reescritura de Lucene MMapDirectory con la API Foreign Memory, que puede ser una característica en vista previa en Java 16. Sin embargo, no se hizo por cuestiones de rendimiento, sino para superar algunas limitaciones con la implementación actual de MMap.
Otro cambio reciente en Lucene fue eliminar las extensiones nativas usando la e/s directa (O_DIRECT) en la clase FileChannel. Esto significa que escribir datos no hará fallar la memoria caché de páginas; será una característica en Lucene 9.
En ocasiones, también puedes acelerar las cosas, para incluso ni tener que pensar en una memoria caché, reduciendo tu complejidad operativa. Recientemente hubo una gran mejora en la aceleración de las agregaciones date_histogram, varias veces. Tómate tu tiempo y lee ese blog, largo pero esclarecedor.
Otro muy buen ejemplo de una gran mejora (sin almacenamiento en caché) fue la implementación de block-max WAND en Elasticsearch 7.0. Puedes leer todo al respecto en este blog de Adrien Grand.
Para resumir el análisis a fondo sobre el almacenamiento en caché
Ojalá haya disfrutado del recorrido por las diversas memorias caché y ahora comprenda cuándo cada una entrará en juego. Además, tenga en cuenta que monitorear sus memorias caché puede ser específicamente útil para saber si tiene sentido usar una memoria caché o si falla reiteradamente debido al agregado y la caducidad constantes. Una vez que habilites el monitoreo de tu cluster de Elastic, podrás ver el consumo de memoria de la memoria caché de búsqueda y la memoria caché de solicitud en la pestaña Advanced (Avanzado) de un nodo, además de por índice, si observas un índice en particular:
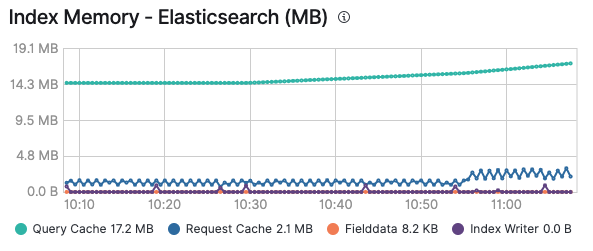
Todas las soluciones existentes sobre el Elastic Stack usarán estas memorias caché para asegurarse de ejecutar las búsquedas y entregar los datos lo más rápido posible. Recuerda que puedes habilitar el logging y monitoreo en Elastic Cloud con un solo clic y tener todos tus clusters monitoreados sin costo adicional. Pruébalo tú mismo.