Was ist Textklassifizierung?
Definition von „Textklassifizierung“
Die Textklassifizierung ist eine Form von Machine Learning, bei der Textdokumente oder Sätze in vordefinierte Klassen oder Kategorien eingeteilt werden. Der Inhalt und die Bedeutung des Textes werden analysiert und anschließend wird dem Text das am besten passende Text-Label zugewiesen.
Zu den praktischen Anwendungen der Textklassifizierung gehören die Sentimentanalyse (zur Ermittlung positiver oder negativer Stimmungen in Rezensionen), die Erkennung von Spam (z. B. von Junk-E‑Mails) und die Themenkategorisierung (z. B. die Zuordnung von Nachrichtenartikeln zu relevanten Themen). Die Textklassifizierung spielt eine wichtige Rolle bei der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP), denn sie versetzt Computer in die Lage, große Mengen von unstrukturiertem Text zu verstehen und zu organisieren. Außerdem werden so Aufgaben wie das Filtern von Inhalten, das Unterbreiten von Empfehlungen und die Analyse von Kundenfeedback vereinfacht.
Arten der Textklassifizierung
Es gibt verschiedene Arten der Textklassifizierung. Dazu gehören die folgenden:
Sentimentanalyse (Sentiment Analysis): Bei dieser Form der Textklassifizierung wird die Stimmung oder Geisteshaltung ermittelt, die im jeweiligen Text zum Ausdruck gebracht wird. In der Regel erfolgt die Einteilung in „positiv“, „negativ“ und „neutral“. Die Analyse wird verwendet, um Produktrezensionen, Social-Media-Posts und Kundenfeedback zu analysieren.
Toxizitätserkennung (Toxicity Detection): Bei dieser Form der Textklassifizierung, die als Unterform der Sentimentanalyse bezeichnet werden kann, werden anstößige oder beleidigende Formulierungen in Online-Texten identifiziert. Das erleichtert es Moderator:innen von Online-Communitys, in der digitalen Welt, z. B. in Online-Diskussionen, Online-Kommentaren oder Social-Media-Posts, für einen respektvollen Umgang zu sorgen.
Absichtserkennung (Intent Recognition): Diese Form der Textklassifizierung, ebenfalls eine Unterform der Sentimentanalyse, hat zum Ziel, den Zweck (oder die Absicht) hinter der Texteingabe der Nutzerin oder des Nutzers zu ermitteln. Sie hilft Chatbots und virtuellen Assistenten, auf Nutzerfragen zu reagieren.
Binäre Klassifizierung (Binary Classification): Bei dieser Form der Textklassifizierung werden Texte in eine von zwei Klassen oder Kategorien eingeteilt. Ein gängiges Beispiel dafür ist die Spam-Erkennung, die Texte, z. B. E‑Mails oder Nachrichten, entweder in die Kategorie „Spam“ oder in die Kategorie „legitim“ einteilt. So können unerwünschte und potenziell schädliche Inhalte automatisch herausgefiltert werden.
Mehrklassenklassifizierung (Multiclass Classification): Bei dieser Form der Textklassifizierung werden Texte in mindestens drei verschiedene Klassen oder Kategorien eingeteilt. Dies erleichtert das Organisieren und Abrufen von Informationen aus Inhalten wie Nachrichtenartikeln, Blogposts oder Studienberichten.
Themenkategorisierung (Topic Categorization): Bei dieser Form der Textkategorisierung, die mit der Mehrklassenklassifizierung verwandt ist, werden Dokumente und Artikel vordefinierten Themen zugeordnet. Bei Nachrichtenartikeln könnten dies beispielsweise die Themenbereiche Politik, Sport und Unterhaltung sein.
Spracherkennung (Language Identification): Bei dieser Form der Textklassifizierung wird ermittelt, in welcher Sprache ein Text verfasst wurde, was in mehrsprachigen Kontexten und für sprachbasierte Anwendungen eingesetzt werden kann.
Eigennamenerkennung (Named Entity Recognition, NER): Bei dieser Form der Textklassifizierung geht es um das Identifizieren und Klassifizieren von Eigennamen, also z. B. der Namen von Personen, Organisationen und Orten, aber auch von Datumsangaben.
Fragenklassifizierung (Question Classification): Bei dieser Form der Textklassifizierung geht es um die Kategorisierung von Fragen auf der Grundlage des erwarteten Antworttyps, was für Suchmaschinen und Fragenbeantwortungssysteme nützlich sein kann.
Ablauf der Textklassifizierung
Die Textklassifizierung ist ein aus mehreren Schritten bestehender Prozess, angefangen von der Datenerfassung bis zur Modellbereitstellung. Zusammengefasst funktioniert sie wie folgt:
Schritt 1: Erfassung der Daten
Es werden verschiedene Textdokumente mit ihren entsprechenden Kategorien erfasst, um sie jeweils mit einem Text-Label zu versehen.
Schritt 2: Vorverarbeitung der Daten
Die Textdaten werden bereinigt und vorbereitet, indem unnötige Symbole entfernt, Großschreibung in Kleinschreibung geändert und Sonderzeichen, wie z. B. Interpunktion, verarbeitet werden.
Schritt 3: Tokenisierung
Der Text wird in sogenannte „Token“ zerlegt. Token sind kleine Einheiten, z. B. einzelne Wörter. Durch diese Tokenisierung entstehen individuell auffindbare Teile, was die Suche nach Übereinstimmungen und Zusammenhängen erleichtert. Dieser Schritt ist besonders hilfreich für die Vektorsuche und die semantische Suche, bei deren Ergebnissen die Nutzerabsicht berücksichtigt wird.
Schritt 4: Extrahierung von Merkmalen
Der Text wird in numerische Darstellungen umgewandelt, die für die Verarbeitung durch Machine-Learning-Modelle geeignet sind. Zu den gängigsten Methoden gehören das Zählen, wie oft ein Wort vorkommt (kommt beim „Bag-of-Words-Modell“ zum Einsatz) oder die Verwendung von Worteinbettungen zur Erfassung von Wortbedeutungen.
Schritt 5: Trainieren des Modells
Die Daten sind jetzt bereinigt und vorverarbeitet und können zum Trainieren eines Machine-Learning-Modells verwendet werden. Das Modell erlernt Muster und Zusammenhänge zwischen den Textmerkmalen und deren Kategorien. Das hilft ihm, anhand der bereits mit einem Label versehenen Beispiele die Konventionen des Text-Labelings zu verstehen.
Schritt 6: Text-Labeling
Um mit dem Text-Labeling und dem Klassifizieren von Text beginnen zu können, wird ein neuer, separater Satz von Daten erstellt. Beim Text-Labeling teilt das Modell den Text in die vorgegebenen Kategorien aus dem Datenerfassungsschritt auf.
Schritt 7: Evaluieren des Modells
Anhand der Text-Labeling-Leistung des trainierten Modells wird untersucht, wie gut das Modell unbekannten Text klassifizieren kann.
Schritt 8: Hyperparameter-Tuning
Je nach Evaluierungsergebnis können Sie jetzt noch die Einstellungen des Modells anpassen, um dessen Leistung zu verbessern.
Schritt 9: Bereitstellen des Modells
Verwenden Sie jetzt das trainierte und optimierte Modell, um neue Textdaten in die entsprechenden Kategorien einzuordnen.
Warum ist die Textklassifizierung wichtig?
Die Textklassifizierung ist wichtig, weil sie Computer in die Lage versetzt, große Mengen von Textdaten automatisch zu kategorisieren und zu verstehen. In unserer digitalen Welt sind wir ständig mit großen Mengen von Textinformationen konfrontiert, ob E‑Mails, soziale Medien, Rezensionen und und und. Mithilfe der Textklassifizierung können Computer diese unstrukturierten Daten in sinnvolle Gruppen einteilen und mit Text-Labeln versehen. Die Textklassifizierung hilft, auf den ersten Blick undurchschaubare Inhalte durchschaubar zu machen, und sorgt so für mehr Effizienz, einfachere Entscheidungen und eine bessere User Experience.
Anwendungsfälle der Textklassifizierung
Die Textklassifizierung findet vielfältige Anwendung in professionellen Umgebungen. Hier ein paar Beispiele für Anwendungsfälle in der Praxis:
- Automatisieren und Kategorisieren von Kundensupporttickets sowie Priorisierung und Weiterleitung der Tickets an die richtigen Teams
- Analysieren von Kundenfeedback, Umfrageantworten und Online-Diskussionen zur Identifizierung von Markttrends und Verbrauchervorlieben
- Verfolgen von Erwähnungen in sozialen Medien und Online-Rezensionen für die Reputations- und Sentimentanalyse für eine Marke
- Organisieren und Kennzeichnen von Inhalten auf Websites und E‑Commerce-Plattformen mithilfe von Text-Labels oder Tags, um die Auffindbarkeit von Inhalten zu verbessern und so für ein besseres Nutzungserlebnis zu sorgen
- Identifizieren potenzieller Kund:innen in sozialen Medien und anderen Online-Quellen anhand bestimmter Schlüsselwörter und Kriterien
- Analysieren von Rezensionen und Feedback für Mitbewerber, um sich ein Bild von deren Stärken und Schwächen zu machen
- Segmentieren von Kund:innen anhand ihrer Interaktionen und ihres Feedbacks mithilfe von Text-Labels, um maßgeschneiderte Marketingstrategien und ‑kampagnen zu entwickeln
- Erkennen betrügerischer Aktivitäten und Transaktionen in Finanzsystemen anhand von Text-Labeling-Mustern und Anomalien (auch bekannt als Anomalieerkennung)
Verfahren und Algorithmen für die Textklassifizierung
Bei der Textklassifizierung kommen unter anderem die folgenden Verfahren und Algorithmen zum Einsatz:
- Bag-of-Words (BoW) ist ein einfaches Verfahren, bei dem gezählt wird, wie oft ein Wort auftaucht, ohne dabei die Reihenfolge des Vorkommens zu berücksichtigen.
- Worteinbettungen nutzen verschiedene Verfahren, um Wörter in numerische Darstellungen umzuwandeln und sie in einem mehrdimensionalen Raum abzubilden. So können komplexe Beziehungen zwischen den Wörtern erfasst werden.
- Entscheidungsbäume sind Machine-Learning-Algorithmen, die eine baumartige Struktur mit Entscheidungsknoten und ‑blättern erstellen. An jedem Knoten wird das Vorhandensein eines Worts geprüft, was dem Baum hilft, Muster in den Textdaten zu erkennen.
- Random Forest ist eine Methode, bei der mehrere Entscheidungsbäume miteinander kombiniert werden, um die Treffsicherheit der Textklassifizierung zu verbessern.
- BERT (Bidirectional Encoder Representations from Transformers) ist ein komplexes transformatorbasiertes Klassifizierungsmodell, das den Kontext von Wörtern verstehen kann.
- Naive-Bayes-Klassifikatoren berechnen die Wahrscheinlichkeit, mit der ein konkretes Dokument zu einer bestimmten Klasse gehört. Die Grundlage für diese Berechnung ist die Häufigkeit des Auftretens von Wörtern im Dokument. Es wird geschätzt, wie hoch die Wahrscheinlichkeit ist, dass jedes Wort in jeder Klasse vorkommt, und diese Wahrscheinlichkeiten werden mithilfe des Satzes von Bayes (eines Hauptsatzes der Wahrscheinlichkeitstheorie) kombiniert, um Vorhersagen zu treffen.
- SVM (Support Vector Machine) ist ein Machine-Learning-Algorithmus, der für Aufgaben im Bereich der binären und Mehrklassenklassifizierung verwendet wird. SVM sucht nach der Hyperebene, die die Datenpunkte verschiedener Klassen in einem hochdimensionalen Merkmalsraum am besten trennt. So kann der Algorithmus bei neuen, ihm noch unbekannten Textdaten korrekte Vorhersagen treffen.
- TF-IDF (Term Frequency-Inverse Document Frequency) ist eine Methode, die die Wichtigkeit von Wörtern in einem Dokument im Vergleich zum gesamten Datenbestand misst.
Bewertungsmetriken bei der Textklassifizierung
Bewertungsmetriken bei der Textklassifizierung werden verwendet, um die Leistung des Modells auf unterschiedliche Weise zu messen. Im Folgenden finden Sie ein paar gängige Bewertungsmetriken:
Treffsicherheit (Accuracy)
Gibt den Anteil der korrekt klassifizierten Textstichproben im Verhältnis zur Gesamtzahl der Textstichproben an. Damit ist diese Metrik ein Gesamtmaß für die Korrektheit des Modells.
Genauigkeit (Precision)
Gibt den Anteil der korrekt vorhergesagten positiven Stichproben im Verhältnis zur Gesamtzahl aller vorhergesagten positiven Stichproben an. Damit drückt diese Metrik aus, wie viele der vorhergesagten positiven Instanzen tatsächlich korrekt waren.
Sensitivität (Recall oder Sensitivity)
Gibt den Anteil der korrekt vorhergesagten positiven Stichproben im Verhältnis zur Gesamtzahl aller tatsächlich positiven Stichproben an. Dieser Metrik lässt sich entnehmen, wie gut das Modell positive Instanzen identifizieren kann.
F1-Score (F1 Score)
Ausgewogenes Maß, das die Metriken „Genauigkeit“ und „Sensitivität“ kombiniert und eine Gesamtbewertung der Leistung des Modells liefert, wenn es auf unausgewogene Klassen stößt.
AUC-ROC (Area Under the Receiver Operating Characteristic Curve)
Grafische Darstellung der Fähigkeit des Modells, zwischen verschiedenen Klassen zu unterscheiden. Diese Darstellung ist insbesondere bei der binären Klassifizierung praktisch.
Konfusionsmatrix (Confusion Matrix)
Tabelle mit Angaben zur Zahl Richtig-Positiver, Richtig-Negativer, Falsch-Positiver und Falsch-Negativer. Damit erhalten Sie eine detaillierte Aufschlüsselung der Leistung Ihres Modells.
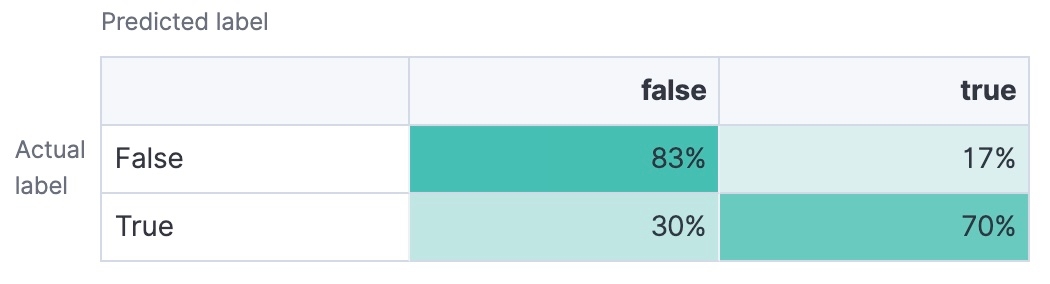
Letztendlich sollten Sie darauf abzielen, ein Textklassifizierungsmodell mit sehr guten Werten bei Treffsicherheit, Genauigkeit, Sensitivität und F1-Score zu wählen – je nachdem, wie Ihre konkreten Anforderungen aussehen. AUC-ROC und die Konfusionsmatrix können ebenfalls hilfreiche Einblicke in die Fähigkeit Ihres Modells bieten, mit verschiedenen Klassifizierungsschwellenwerten umzugehen und die Leistung des Modells besser zu verstehen.
Zukunftstrends bei der Textklassifizierung
Zukunftstrends bei der Textklassifizierung reichen von Open AI bis zu branchenspezifischen Tools. In dem Maße, wie sich die Machine-Learning-Technologie weiterentwickelt, werden sich auch die Möglichkeiten der Textklassifizierung erweitern. So müssen beispielsweise die neuesten Tools und Technologien nicht nur leichter zugänglich, sondern auch vielfältiger werden. Schon bald wird es mehrsprachige Textklassifizierung geben, um dem wachsenden Bedarf an der Unterstützung mehrerer Sprachen in globalen Anwendungen gerecht zu werden. So können mehrere Sprachen im selben Datenbestand effektiv analysiert werden. Auch die fachspezifische Textklassifizierung wird sich durchsetzen, da die Modelle so trainiert werden, dass sie spezifischere und damit treffsicherere Klassifizierungen für Fachbereiche wie Recht, Medizin oder Finanzen liefern.
Bei neuen KI-Funktionen werden die Trends bei der Textklassifizierung ebenfalls eine Rolle spielen. Mit der zunehmenden Verbreitung von KI-Anwendungen steigt der Bedarf an transparenten und interpretierbaren Textklassifizierungsmodellen. Explainable AI (XAI) beinhaltet die Berücksichtigung von Erklärbarkeitsmethoden, um die den Modellvorhersagen zugrunde liegenden Überlegungen zu verstehen.
Deep-Learning-Modelle, wie z. B. CNNs (Convolutional Neural Networks) und RNNs (Recurrent Neural Networks), sowie Hybridmodelle sind neuronale Netzwerkarchitekturen, die bei der Textklassifizierung eingesetzt werden. CNNs werden in erster Linie für Bildverarbeitungsaufgaben eingesetzt, während RNNs für die Verarbeitung sequenzieller Daten konzipiert sind, aber beide haben bereits gezeigt, dass sie Textmuster verstehen können. Hybridmodelle kombinieren mehrere Architekturen (wie CNNs, RNNs und transformatorbasierte Modelle wie BERT), um die Stärken verschiedener Ansätze für eine bessere Textklassifizierung zu nutzen.
Die zukünftige Forschung kann sich auch mit Verfahren beschäftigen, die es Textklassifizierungsmodellen ermöglichen, aus weniger gelabelten Stichproben zu lernen (Few-Shot Learning) oder sogar Textklassifizierung in Klassen durchzuführen, die während des Trainings nicht vorkamen (Zero-Shot Learning). Beide haben das Potenzial, die Abhängigkeit von großen, gelabelten Datenbeständen deutlich zu verringern und die Textklassifizierung skalierbarer und anpassbarer an neue Aufgaben zu machen.
Textklassifizierung mit Elasticsearch
Die Textklassifizierung ist eine der vielen Funktionen im Zusammenhang mit der Verarbeitung natürlicher Sprache in Elastic Search-Lösungen. Mit Elasticsearch können Sie Ihren unstrukturierten Text klassifizieren, Informationen daraus extrahieren und diese schnell und einfach Ihren Geschäftsanforderungen entsprechend anwenden.
Egal, ob Sie die Textklassifizierung für Search, Observability oder Security benötigen – mit Elastic können Sie die Textklassifizierung nutzen, um Informationen effizienter zu extrahieren und zu organisieren.