Echtzeit-Einblicke in Ihr Kubernetes-Ökosystem
Führen Sie Logdaten, Metriken und Traces aus Ihrem Kubernetes-Cluster – und den Workloads, die auf ihm laufen – in einer zentralen Lösung zusammen. Mit dynamischer Diensterkennung, zentraler Agent-Verwaltung und angereicherten Telemetriedaten aus Ihren Clustern können Sie schnell Probleme mit Ihren Anwendungen, Ihren Diensten und Ihrer Umgebung identifizieren.
Nutzen Sie einen zentral verwalteten Elastic Agent, um Einblicke in Ihre Kubernetes-Deployments auf EKS, AKS, GKE oder selbstverwalteten Clustern zu erhalten.
Mehr erfahrenVerwalten und überwachen Sie Ihre Kubernetes-Umgebung mit Elastic Observability.
Mehr erfahrenErfahren Sie, wie Sie für eine OpenTelemetry-Anwendung auf Ihrem Kubernetes-Cluster Observability und Security nutzen können.
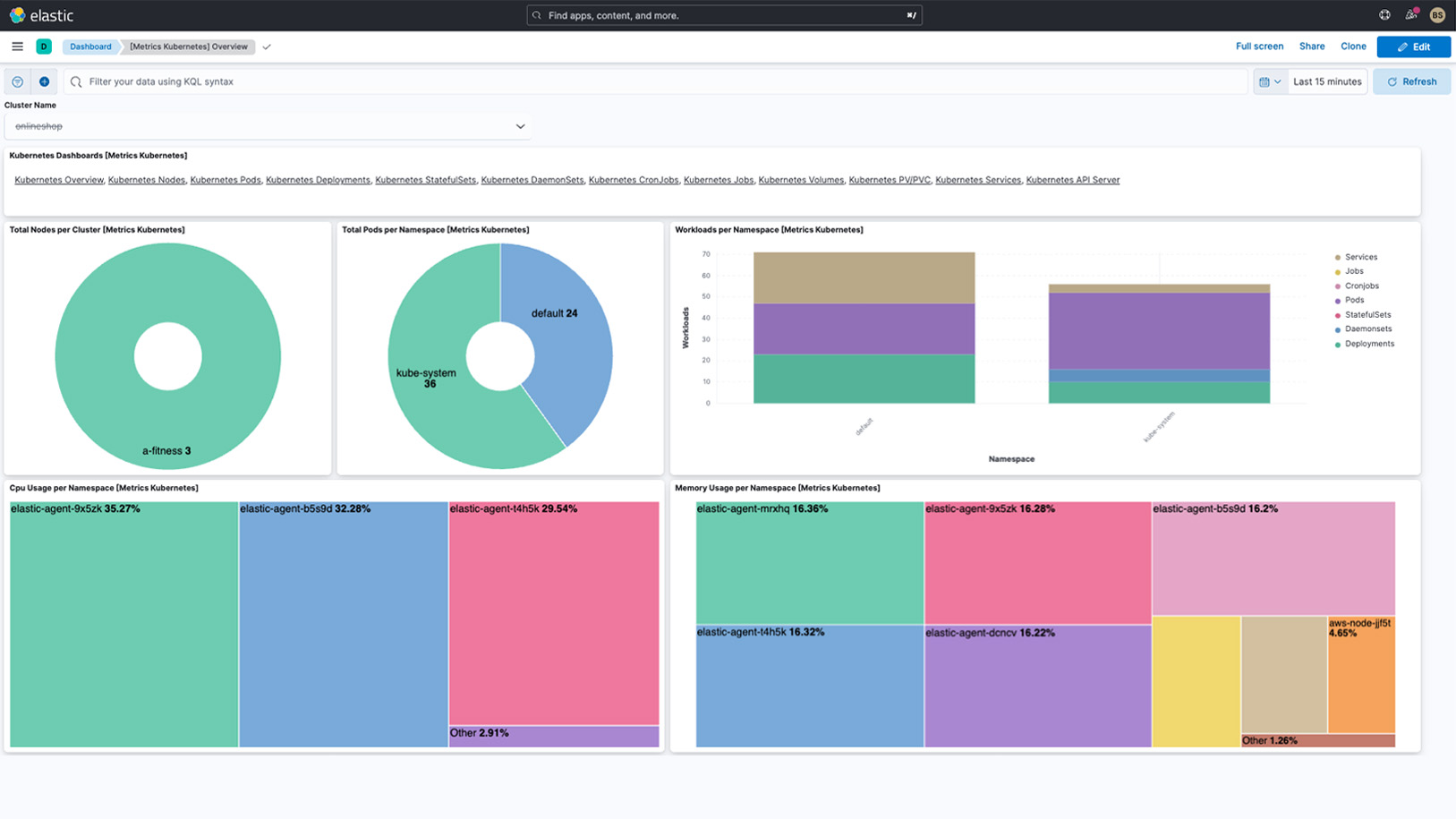
Mehr erfahrenAutomatisches Erkennen dynamischer Workloads mit vorkonfigurierten Dashboards
Wo die Workloads dynamisch sind, muss auch das Monitoring dynamisch sein – und gerade Anwendungen in Containern sind sehr kurzlebig. Die automatische Erkennung von Elastic erkennt diese Änderungen und hilft Ihnen, Ihre Kubernetes-Dienste und ‑Komponenten stets im Blick zu behalten, gleich, wo sie ausgeführt werden. Und dank Metadatenanreicherung beim Ingestieren können Sie gemeinsame Attribute des Systems filtern, verfolgen und identifizieren. Behalten Sie dank umfangreicher vorkonfigurierter Dashboards Änderungen und zugehörige Metriken, Logdaten und Analysen im Blick.
Unterstützung für offene Standards
Elastic-Integrationen unterstützen aus sich selbst heraus offene Standards wie OpenTelemetry, Prometheus und Istio für Metriken und vieles mehr. Mit PromQL können Sie Ihre vorhandenen Prometheus-Metriken erfassen, transformieren und visualisieren.
Neben dem Elastic Agent werden über Integrationen auch native Tools zum Ingestieren von Logdaten, Metriken und Traces mit Unterstützung für offene Standards, einschließlich OpenTelemetry für Metriken und Traces, Prometheus-Metriken und Istio-Metriken unterstützt; dazu gehört auch die Unterstützung für PromQL-Abfragen für die Metrikenerfassung.

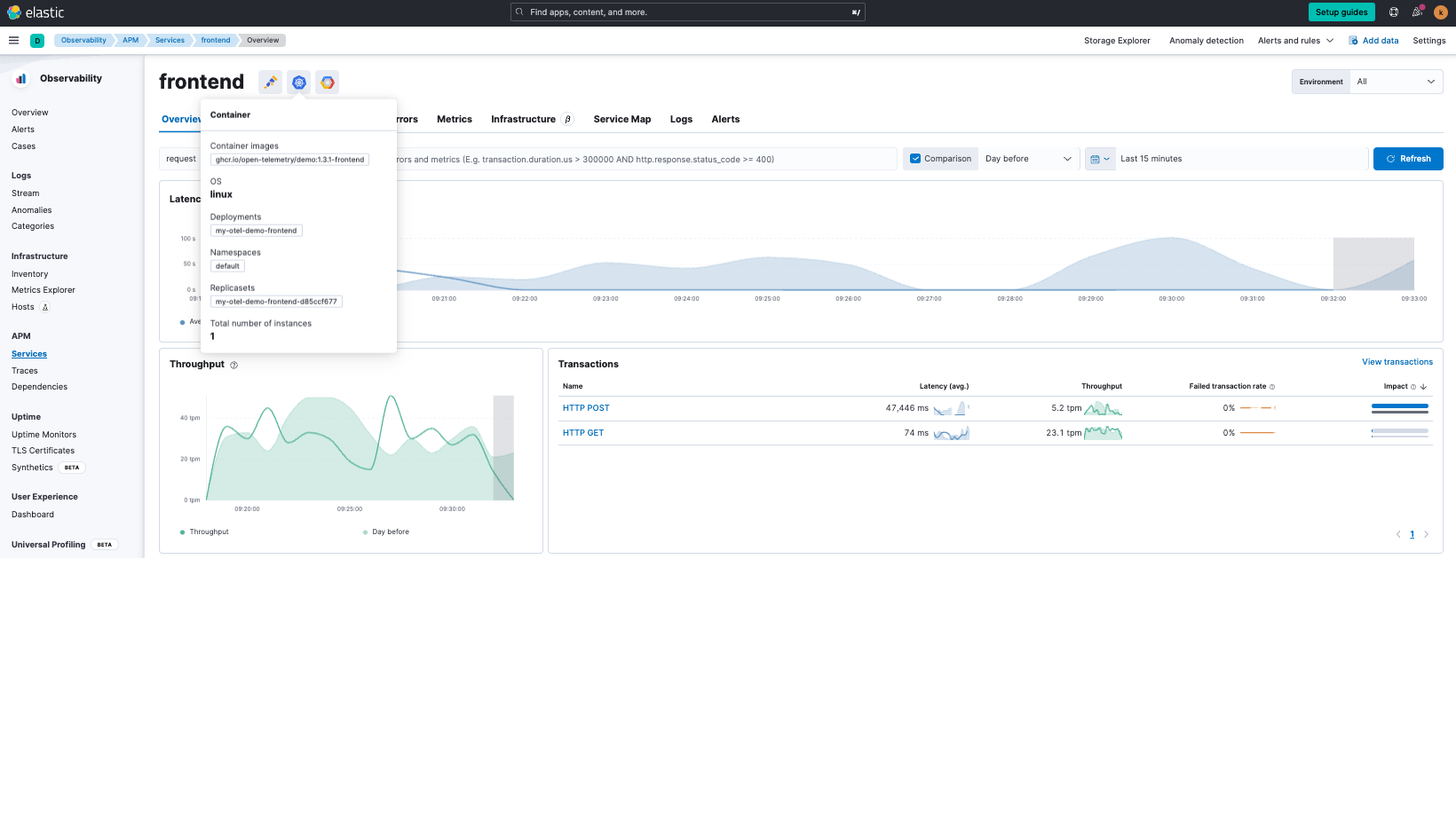
End-to-End-Transparenz – von der Anwendung über Kubernetes bis zur Cloud
Elastic APM bietet nicht nur Einblicke in Ihre Anwendungsdienste, sondern korreliert diese auch mit den zugehörigen Kubernetes- und Cloud-Komponenten. Zusätzliche Einblicke in die Zusammenhänge zwischen den Schichten erhalten Sie mit Machine Learning von Elastic.
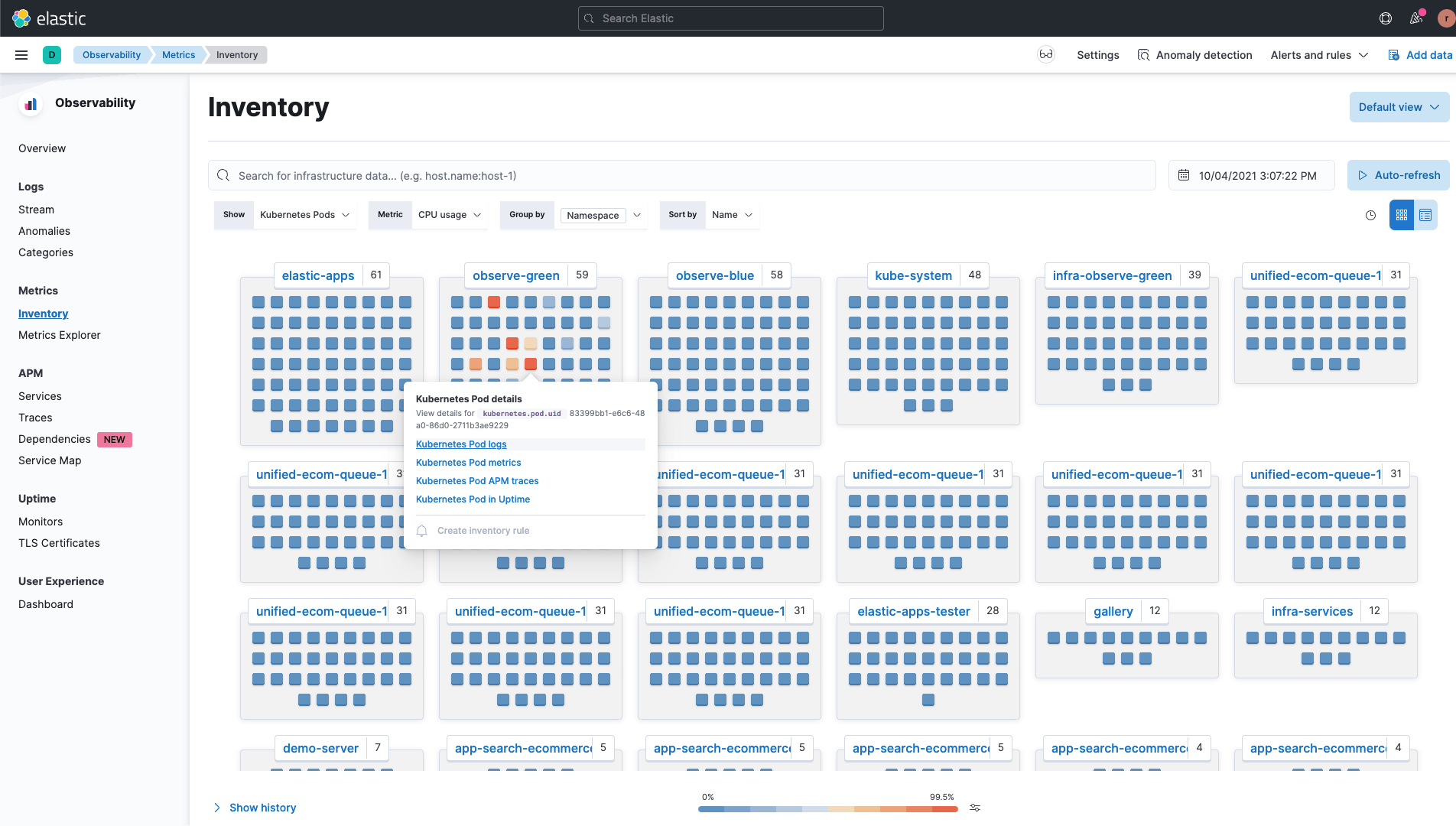
Tiefgreifende Analysen Ihres gesamten Ökosystems
Erhalten Sie tiefe Einblicke in Ihren Kubernetes-Cluster und die darauf ausgeführten Dienste, einschließlich der Kubernetes-Knoten, der Komponenten der Steuerungsebene (Control plane) und Ihrer Workloads. Navigieren Sie schnell zu den entsprechenden Logs, Metriken oder Traces, um Probleme schneller und effizienter zu identifizieren und zu beheben.
Problemlose Bereitstellung und reibungsloser Betrieb von Kubernetes-Architekturen
Eine korrelierte und kontextualisierte Benutzeroberfläche für die Ad-hoc-Analyse reduziert die Komplexität verteilter Microservice-Architekturen und hilft dabei, Probleme schneller aufzuspüren. Nutzen Sie die Machine-Learning-Funktionen von Elastic, um Ihre Kubernetes-Cluster besser zu verwalten.