Privacy-First-KI-Suche mit LangChain und Elasticsearch


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Ich habe die vergangenen Wochenenden in der faszinierenden Welt des „prompt engineering“ verbracht und gelernt, wie Vektordatenbanken wie Elasticsearch® Large Language Models (LLMs) wie ChatGPT noch wirkungsvoller machen, indem sie als Langzeitspeicher und semantischer Wissensspeicher dienen. Was mir – und vielen anderen erfahrenen Datenarchitekten – aber Sorge bereitet hat: Enorm viele Tutorials und Demos sind vollkommen davon abhängig, großen Web-Konzernen und cloudbasierten KI-Unternehmen private Daten zu senden.
Private Daten können verschiedene Formen haben und sind aus mehr als einem Grund geschützt. Startups und Konzerne wissen, dass ihre privaten Daten manchmal ihr Wettbewerbsvorteil sind. Interne Daten und Kundendaten weisen häufig Informationen auf, anhand derer Personen identifiziert werden können. Wenn sie nicht geschützt werden, hat das sowohl rechtliche als auch unmittelbar persönlich merkliche Folgen. In den Domänen Observability und Sicherheit kann mangelnde Vorsicht bei der Nutzung von Drittanbieterdiensten eine Quelle von Datenlecks sein. Wir haben sogar von mutmaßlichen Cybersicherheitsbedrohungen gehört, die mit KI-Chat-Tools in Verbindung gebracht wurden.
Es gibt keine Risikofreiheit und keinen vollständigen Datenschutz, auch nicht bei der Arbeit mit Unternehmen wie Elastic mit starkem Bekenntnis zu Sicherheit und Datenschutz oder bei Bereitstellungen in einem echten Air Gap. Ich hatte aber bereits mit genügend Anwendungsfällen für sensible Daten zu tun, dass ich weiß, dass die Anwendung von KI in einem datenschutzfokussierten Ansatz echten Mehrwert bietet. Ich fand die herausragende Anleitung meines Kollegen Jeff Vestal zur Anwendung von OpenAI-Tools mit Elasticsearch sehr gut, verfolge aber in diesem Artikel einen anderen Ansatz.
Ich habe zwei Ziele für die Herangehensweise an dieses Projekt:
- Datenschutzfokussiert – und hier gehe ich keine Kompromisse ein. Ich verwende zwar auch cloudbasiertes Elasticsearch, falls es der Anwendungsfall erfordert, möchte aber, dass dieses Projekt ohne Abstriche in einem Air Gap funktioniert. Wir möchten beweisen, dass KI-basierte Suche funktioniert, ohne dass wir dazu Dritten gegenüber Privates preisgeben müssen.
- Spaßig – das Ganze soll auch ein wenig Spaß machen. Wir nutzen einen Scrape der Wookieepedia, ein Community-Wiki zu Star Wars, das sich bei Übungen zur Datenwissenschaft großer Beliebtheit erfreut, und bauen uns einen datenschutzfreundlichen KI-Trivia-Helfer. Ich habe diesen Text kurz vor dem Star-Wars-Day am 4. Mai verfasst. Dieses Datum ist nun bei Veröffentlichung dieses Posts zwar vorbei, aber ich bin natürlich das ganze Jahr lang Fan.
Sie können den Schritten hier am einfachsten direkt folgen, wenn Sie eine Elasticsearch Instanz auf Elastic Cloud eröffnen und das bereitgestellte Python-Notizbuch durchgehen. So implementieren Sie das Projekt im kleinen Rahmen. Wenn Sie den gesamten Scrape der Wookieepedia mit 180.000 Absätzen gesammelten Star-Wars-Wissens verwenden und eine umfassende Suche erstellen möchten, folgen Sie dem Code in diesem GitHub-Repository.
Wenn Sie fertig sind, sollte das Ganze so aussehen:
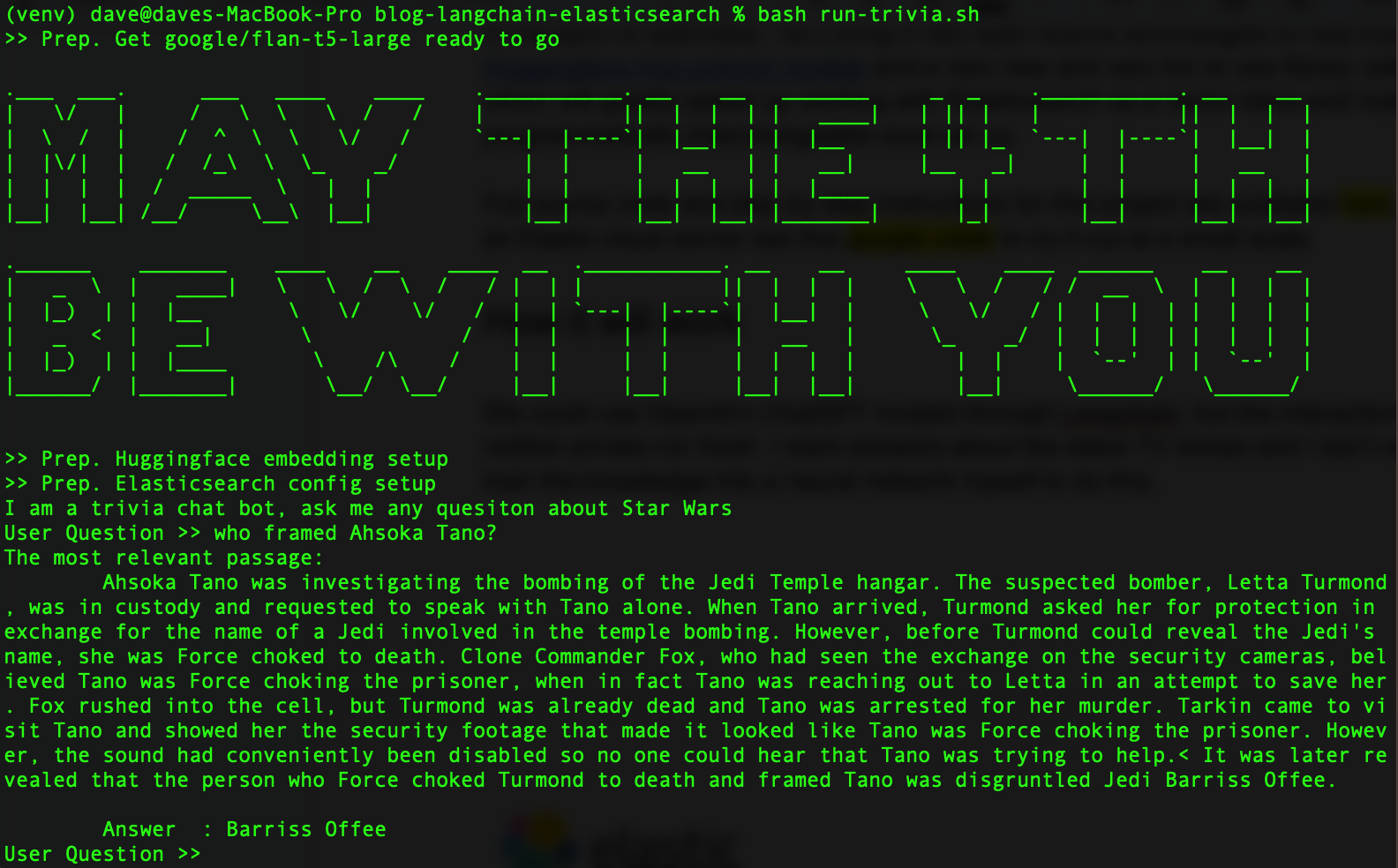
Um unser Vorhaben offen zu gestalten, ziehen wir zwei Open-Source-Technologien heran, um Elasticsearch zu unterstützen: Die Transformer-Bibliothek von Hugging Face und die neue Python-Bibliothek LangChain, deren Anwendung nicht nur Spaß macht, sondern die auch die Arbeit mit Elasticsearch als Vektordatenbank beschleunigen. Ein toller Bonus: LangChain macht unsere LLMs nach der Einrichtung programmatisch austauschbar, sodass wir mit unterschiedlichen Modellen experimentieren können.
Funktionsweise
Was ist LangChain? LangChain ist ein Python- und JavaScript-Framework für die Entwicklung von Anwendungen auf Basis von Large Language Models. LangChain funktioniert mit den APIs von OpenAI, ist aber auch sehr gut darin, die Unterschiede zwischen Datenbanken und KI-Tools wegzuabstrahieren.
ChatGPT selbst ist schon ganz gut in Sachen Star-Wars-Trivia. Allerdings ist sein Trainingsdatensatz nun schon mehrere Jahre alt und wir wollen Antworten zu den aktuellen TV-Serien und Ereignissen im Star-Wars-Universum. Denken Sie außerdem daran, dass wir so tun, als seien diese Daten zu privat, um sie mit einem großen LLM in der Cloud zu teilen. Wir könnten ein LLM selbst mit aktuelleren Daten füttern, aber es gibt eine viel einfachere Methode, die es uns auch ermöglicht, immer die frischesten Daten zu verwenden.
Heute ziehen wir ein kleineres und leicht selbst zu hostendes LLM heran. Ich habe mit dem flan-t5-large Modell von Google gute Ergebnisse erzielt. Es gleicht sein mangelndes Training durch eine gute Fähigkeit zum Auslesen von Antworten aus eingebrachtem Kontext aus. Wir verwenden eine semantische Suche, um unser privates Wissen abzurufen, und bringen dann diesen Kontext mit einer Frage in unser privates LLM ein.
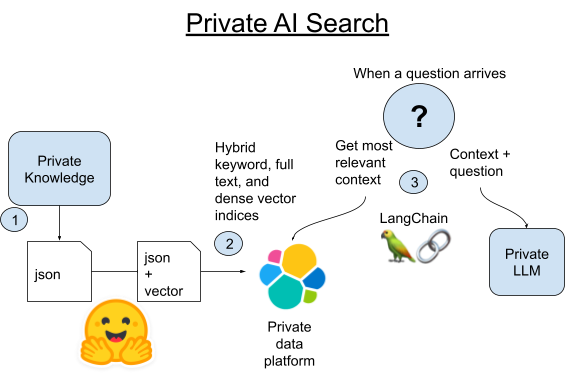
1. Scrapen Sie alle kanonischen Artikel aus Wookieepedia und platzieren Sie die Daten in gestaffelten Python-Pickle-Dateien.
2A. Laden Sie jeden Absatz dieser Artikel mit LangChains integrierter Vectorstore Bibliothek in Elasticsearch.
2B. Alternativ können wir LangChain mit der neuen Möglichkeit zum Hosten von pytorch-Transformern in Elasticsearch selbst vergleichen. Wir stellen das Modell zur Texteinbettung in Elasticsearch bereit, um die Rechenlast zu verteilen und den Vorgang zu beschleunigen.
3. Wenn eine Frage eingeht, finden wir mit der Vektorsuche von Elasticsearch den der Frage semantisch ähnlichsten Absatz. Wir fügen den Absatz dann der Eingabe eines kleinen lokalen LLM als Kontext zur Frage hinzu und überlassen es dann dem Zauber der generativen KI, eine kurze Antwort zu unserer Trivia-Frage zu erstellen.
Einrichtung der Python- und Elasticsearch-Umgebung
Stellen Sie sicher, dass Sie Python 3.9 oder ähnliche Versionen auf dem Rechner haben. Ich verwende 3.9 für einfachere Kompatibilität von Bibliotheken mit GPU-Beschleunigung, aber das ist für dieses Projekt nicht notwendig. Jede aktuellere 3.X-Version von Python funktioniert.
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install beautifulsoup4 eland elasticsearch huggingface-hub langchain tqdm torch requests sentence_transformersWenn Sie den Beispielcode heruntergeladen haben, können Sie stattdessen auch einfach genau die Versionen des Codes, den ich verwendet habe, mit dem folgenden pip install-Befehl abrufen.
pip install -r requirements.txtEinen Elasticsearch Cluster richten Sie wie hier beschrieben ein. Das kostenlose Cloud-Probeabo ist die einfachste Art, gleich loszulegen.
Erstellen Sie eine .env-Datei in dem Ordner und laden Sie Ihre Verbindungsdetails für Elasticsearch hoch.
export ES_SERVER="YOURDESSERVERNAME.es.us-central1.gcp.cloud.es.io"
export ES_USERNAME="YOUR READ WRITE AND INDEX CREATING USER"
export ES_PASSWORD="YOUR PASSWORD"Schritt 1. Daten scrapen
Das Code-Repo hat unter Dataset/starwars_small_sample_data.pickle einen kleinen Datensatz. Wenn es für Sie in Ordnung ist, im kleinen Maßstab zu arbeiten, können Sie diesen Schritt überspringen.
Der Code für das Scraping folgt Dennis Bakhuis‘ hervorragendem Blog und Projekt zur Datenwissenschaft – Reinschauen lohnt sich! Er ruft nur den ersten Absatz jedes Artikels auf. Ich habe den Code so angepasst, dass der gesamte Text abgerufen wird. Möglicherweise musste er die Datengröße so beschränken, dass sie im Primärspeicher Platz findet. Wir aber haben das Problem nicht, weil wir Elasticsearch nutzen, mit dem wir dieses Projekt auch in die Petabytes hochskalieren könnten.
Sie könnten hier auch sehr leicht Ihre eigene private Datenquelle einbinden. LangChain verfügt über einige tolle Utility-Bibliotheken, mit denen Sie Ihre Textdaten in kleinere Happen aufteilen können.
Scraping ist nicht das Augenmerk dieses Artikels. Sehen Sie sich das Python-Notizbuch an, wenn Sie es selbst in kleinem Umfang ausführen wollen, oder laden Sie den Quellcode herunter und führen Sie ihn so aus:
source .env
python3 step-1A-scrape-urls.py
python3 step-1B-scrape-content.py
Wenn Sie fertig sind, sollten Sie wie folgt durch die gespeicherten Pickle-Dateien gehen können, um sicherzustellen, dass es funktioniert hat.
from pathlib import Path
import pickle
bookFilePath = "starwars_*_data*.pickle"
files = sorted(Path('./Dataset').glob(bookFilePath))
for fn in files:
with open(fn,'rb') as f:
part = pickle.load(f)
for key, value in part.items():
title = value['title'].strip()
print(title)Wenn Sie das Web Scraping übersprungen haben, ändern Sie einfach bookFilePath in „starwars_small_sample_data.pickle“, um die Beispieldatei aus dem GitHub-Repository zu verwenden.
Schritt 2A. Einbettungen in Elasticsearch laden
Der vollständige Code zeigt, wie ich das nur mit LangChain mache. Der wesentliche Teil des Codes besteht darin, aus den gespeicherten Pickle-Dateien wie dem Beispiel oben eine Liste an Strings zu extrahieren, die den Absätzen entsprechen, und sie dann an die from_texts()-Funktion des LangChain Vectorstore zu leiten.
from langchain.vectorstores import ElasticVectorSearch
from langchain.embeddings import HuggingFaceEmbeddings
from pathlib import Path
import pickle
import os
from tqdm import tqdm
model_name = "sentence-transformers/all-mpnet-base-v2"
hf = HuggingFaceEmbeddings(model_name=model_name)
index_name = "book_wookieepedia_mpnet"
endpoint = os.getenv('ES_SERVER', 'ERROR')
username = os.getenv('ES_USERNAME', 'ERROR')
password = os.getenv('ES_PASSWORD', 'ERROR')
url = f"https://{username}:{password}@{endpoint}:443"
db = ElasticVectorSearch(embedding=hf, elasticsearch_url=url, index_name=index_name)
batchtext = []
bookFilePath = "starwars_*_data*.pickle"
files = sorted(Path('./Dataset').glob(bookFilePath))
for fn in files:
with open(fn,'rb') as f:
part = pickle.load(f)
for ix, (key, value) in tqdm(enumerate(part.items()), total=len(part)):
paragraphs = value['paragraph']
for p in paragraphs:
batchtext.append(p)
db.from_texts(batchtext,
embedding=hf,
elasticsearch_url=url,
index_name=index_name)
Schritt 2B. Mit gehosteten trainierten Modellen Zeit und Geld sparen
Ich habe festgestellt, dass es auf meinem älteren Intel Macbook viele Rechenstunden erfordert hätte, Einbettungen zu erstellen. Weniger gütig ausgedrückt wären es wohl eher mehrere Tage gewesen. Ich bin der Meinung, dass ich mit den dynamisch skalierbaren ML-Knoten (Machine Learning) des gehosteten Diensts von Elastic schneller und deutlich günstiger davonkomme. In den Clustern im kostenlosen Probeabo ist diese Stufe allerdings nicht enthalten, weswegen dieser Schritt für manche sinnvoller sein kann als für andere.
Das Endergebnis: Diese Herangehensweise hat in Elastic Cloud 40 Minuten gedauert, auf Knoten, die mich 5 $ pro Stunde kosten. Das ist deutlich schneller als meine lokale Hardware und vom Kostenfaktor für die Verarbeitung von Einbettungen gleichauf mit den aktuellen Token-Gebühren von OpenAI. Das Ganze effizient zu gestalten ist ein umfangreicheres Thema, aber ich bin beeindruckt, wie schnell ich eine parallele Inferenzpipeline in Elastic Cloud zum Laufen gebracht habe, ohne mir neue Fähigkeiten aneignen oder meine Daten an eine nicht private API aushändigen zu müssen.
Für diesen Schritt lagern wir die Erstellung von Einbettungen an den Elasticsearch Cluster selbst aus. Er kann das Einbettungsmodell hosten und die Textabschnitte verteilt einbetten. Dazu müssen wir die Daten laden und Ingestionspipelines nutzen, um sicherzustellen, dass die endgültige Form dem Index Mapping von LangChain entspricht. Führen Sie den folgenden REST-Befehl in den Entwicklertools von Kibana aus:
PUT /book_wookieepedia_mpnet
{
"settings": {
"number_of_shards": 4
},
"mappings": {
"properties": {
"metadata": {
"type": "object"
},
"text": {
"type": "text"
},
"vector": {
"type": "dense_vector",
"dims": 768
}
}
}
}
Als Nächstes laden wir das Einbettungsmodell mit der Python-Bibliothek eland in Elasticsearch hoch.
source .env
python3 step-3A-upload-model.pyWir wechseln dann in die Elastic Cloud Konsole und skalieren unsere ML-Stufe auf insgesamt 64 vCPUs hoch (achtmal so viel Leistung wie mein derzeitiger Laptop).
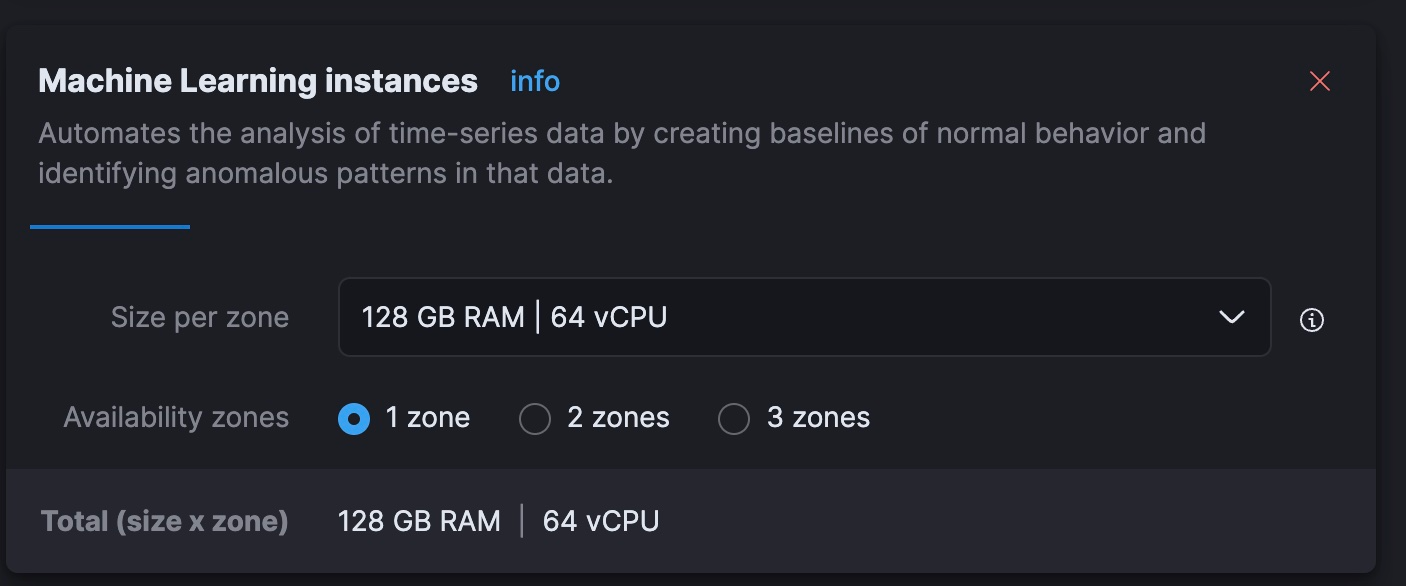
In Kibana stellen wir nun das trainierte KI-Modell bereit. In großen Rahmen haben Leistungstests gezeigt, dass Nutzer mit 1 Thread pro Modellzuweisung beginnen und die Anzahl an Zuweisungen erhöhen sollten, um den Durchsatz zu erhöhen. Die Dokumentation und Leitfäden finden sich hier. Ich habe experimentiert und bei diesem kleineren Satz optimale Ergebnisse mit 32 Instanzen mit je 2 Threads erzielt. Die Einrichtung erfolgt über Stack-Management > Machine Learning. Verwenden Sie die Funktion Synchronize saved objects (Gespeicherte Objekte synchronisieren), damit Kibana das Modell sehen kann, das wir mit dem Python-Code an Elasticsearch übertragen haben. Stellen Sie das Modell dann über das Menü bereit, das erscheint, wen Sie darauf klicken.

Wir verwenden nun erneut die Entwickler-Tools, um eine neue Indexierungs- und Ingestierungspipeline zu erstellen, die den Textabsatz in einem Dokument verarbeitet, das Ergebnis in ein dichtes Vektorfeld namens „vector“ platziert und den Absatz in das erwartete Feld „text“ kopiert.
PUT /book_wookieepedia_mpnet
{
"settings": {
"number_of_shards": 4
},
"mappings": {
"properties": {
"metadata": {
"type": "object"
},
"text": {
"type": "text"
},
"vector": {
"type": "dense_vector",
"dims": 768
}
}
}
}
PUT _ingest/pipeline/sw-embeddings
{
"description": "Text embedding pipeline",
"processors": [
{
"inference": {
"model_id": "sentence-transformers__all-mpnet-base-v2",
"target_field": "text_embedding",
"field_map": {
"text": "text_field"
}
}
},
{
"set":{
"field": "vector",
"copy_from": "text_embedding.predicted_value"
}
},
{
"remove": {
"field": "text_embedding"
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
Testen Sie die Pipeline, um sicherzustellen, dass sie funktioniert.
POST _ingest/pipeline/sw-embeddings/_simulate
{
"docs": [
{
"_source": {
"text": "Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.",
"metadata": {
"a": "b"
}
}
}
]
}
Nun können wir Daten über die normale Python-Bibliothek für Elasticsearch als Batch laden; wir weisen dabei auf unsere Ingestierungspipeline, um die Vektoreinbettung korrekt zu erstellen und unsere Daten so zu transformieren, dass sie den Erwartungen von LangChain entsprechen.
source .env
python3 step-3B-batch-hosted-vectorize.pyGeschafft! Bei OpenAI umfasst die Datenmenge etwa 13 Millionen Tokens. Nicht privat und in der Cloud verarbeitet wären das also Kosten von etwa 5,40 $. Mit Elastic Cloud waren wir in 40 Minuten fertig, bei Gerätekosten von 5 $ pro Stunde.
Wenn die Daten geladen sind, denken Sie daran, ihr Cloud-ML über die Cloud-Konsole wieder auf null oder einen anderen sinnreichen Wert herunterzuskalieren.
Schritt 3. Erfolg bei Star-Wars-Trivia
Nun spielen wir mit dem LLM und LangChain. Ich habe für diesen Code die Bibliotheksdatei lib_llm.py erstellt.
from langchain import PromptTemplate, HuggingFaceHub, LLMChain
from langchain.llms import HuggingFacePipeline
from transformers import AutoTokenizer, pipeline, AutoModelForSeq2SeqLM
from langchain.vectorstores import ElasticVectorSearch
from langchain.embeddings import HuggingFaceEmbeddings
import os
cache_dir = "./cache"
def getFlanLarge():
model_id = 'google/flan-t5-large'
print(f">> Prep. Get {model_id} ready to go")
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(model_id, cache_dir=cache_dir)
pipe = pipeline(
"text2text-generation",
model=model,
tokenizer=tokenizer,
max_length=100
)
llm = HuggingFacePipeline(pipeline=pipe)
return llm
local_llm = getFlanLarge()
def make_the_llm():
template_informed = """
I am a helpful AI that answers questions.
When I don't know the answer I say I don't know.
I know context: {context}
when asked: {question}
my response using only information in the context is: """
prompt_informed = PromptTemplate(
template=template_informed,
input_variables=["context", "question"])
return LLMChain(prompt=prompt_informed, llm=local_llm)
## continued below
template_informed ist hier der wesentliche, aber auch leicht verständliche Teil. Wir formatieren nur eine Eingabevorlage, die unsere beiden Parameter verwendet: den Kontext und die Frage des Nutzers.
Mit dem fortgesetzten Hauptcode von oben sieht das wie folgt aus:
## continued from above
topic = "Star Wars"
index_name = "book_wookieepedia_mpnet"
# Create the HuggingFace Transformer like before
model_name = "sentence-transformers/all-mpnet-base-v2"
hf = HuggingFaceEmbeddings(model_name=model_name)
## Elasticsearch as a vector db, just like before
endpoint = os.getenv('ES_SERVER', 'ERROR')
username = os.getenv('ES_USERNAME', 'ERROR')
password = os.getenv('ES_PASSWORD', 'ERROR')
url = f"https://{username}:{password}@{endpoint}:443"
db = ElasticVectorSearch(embedding=hf, elasticsearch_url=url, index_name=index_name)
## set up the conversational LLM
llm_chain_informed= make_the_llm()
def ask_a_question(question):
## get the relevant chunk from Elasticsearch for a question
similar_docs = db.similarity_search(question)
print(f'The most relevant passage: \n\t{similar_docs[0].page_content}')
informed_context= similar_docs[0].page_content
informed_response = llm_chain_informed.run(
context=informed_context,
question=question)
return informed_response
# The conversational loop
print(f'I am a trivia chat bot, ask me any question about {topic}')
while True:
command = input("User Question >> ")
response= ask_a_question(command)
print(f"\tAnswer : {response}")
Fazit
Mit etwas kreativem Umgang mit Daten haben wir nun KI genutzt, ohne unsere Daten an ein bei Drittanbietern gehostetes LLM preiszugeben. Die Welt der KI verändert sich rasant, aber wir alle sollten aufgrund der regulatorischen, finanziellen und persönlichen Folgen von Datenlecks die Sicherheit von und die Kontrolle über personenbezogene Daten wahren. Denn dieser Faktor wird sich nicht ändern. Wir arbeiten mit Kunden, die Suchen verwenden, um Betrugsfälle aufzudecken, ihr Land zu verteidigen und Ergebnisse für vulnerable Patientengruppen zu verbessern. Datenschutz ist wichtig. Hier erfahren Sie mehr darüber, wie Elastic in diesen Bereichen verwendet wird:
Finden Sie LangChain nun auch so toll wie ich? Wie ein weiser alter Jedi einst sagte: „Das ist gut. Du hast den ersten Schritt in eine größere Welt getan.“ Von hier aus können wir verschiedenste Richtungen einschlagen. LangChain vereinfacht die Arbeit mit Prompt Engineering für KI. Ich weiß, dass Elasticsearch hier viele andere Rollen als Speicher für generative KI einnimmt. Deswegen freue ich mich sehr, die Ergebnisse aus diesem hochdynamischen Bereich zu sehen.
In diesem Blogpost haben wir möglicherweise generative KI-Tools von Drittanbietern verwendet, die von ihren jeweiligen Eigentümern betrieben werden. Elastic hat keine Kontrolle über die Drittanbieter-Tools und übernimmt keine Verantwortung oder Haftung für ihre Inhalte, ihren Betrieb oder ihre Anwendung sowie für etwaige Verluste oder Schäden, die sich aus Ihrer Anwendung solcher Tools ergeben. Gehen Sie vorsichtig vor, wenn Sie KI-Tools mit persönlichen, sensiblen oder vertraulichen Daten verwenden. Alle Daten, die Sie eingeben, können für das Training von KI oder andere Zwecke verwendet werden. Es gibt keine Garantie dafür, dass Informationen, die Sie bereitstellen, sicher oder vertraulich behandelt werden. Setzen Sie sich vor Gebrauch mit den Datenschutzpraktiken und den Nutzungsbedingungen generativer KI-Tools auseinander.
Elastic, Elasticsearch und zugehörige Marken, Waren- und Dienstleistungszeichen sind Marken oder eingetragene Marken von Elastic N.V. in den USA und anderen Ländern. Alle weiteren Marken- oder Warenzeichen sind eingetragene Marken oder eingetragene Warenzeichen der jeweiligen Eigentümer.
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken

