Erklären von mit Elastic Machine Learning entdeckten Anomalien


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Warum gibt es hier eine Anomalie? Wieso ist der Anomalie-Score nicht höher? Die Anomalieerkennung ist eine hilfreiche Machine-Learning-Funktion, die in Elastic Security und Observability zum Einsatz kommt. Aber all die Zahlen und Werte können einen ziemlich überfordern. Da wäre es schon schön, wenn man das in eine verständliche Sprache übersetzt oder, besser noch, bildlich dargestellt bekäme.
In Elastic 8.6 erhalten Sie Zugang zu zusätzlichen Details von Anomaliedatensätzen. Diese Details bieten einen Blick hinter die Kulissen des Anomalie-Scoring-Algorithmus.
Das Anomalie-Scoring und die Normalisierung waren bereits Gegenstand dieses Blogposts. Der Algorithmus für die Anomalieerkennung analysiert online Zeitreihen von Daten. So erkennt er Trends und periodisch wiederkehrende Muster in unterschiedlichen Zeiträumen, also z. B. täglich, wöchentlich, monatlich oder jährlich. Echtzeitdaten bestehen in aller Regel aus einer Mischung aus Trends und wiederkehrenden Mustern in unterschiedlichen Zeiträumen. Und was auf den ersten Blick wie eine Anomalie aussehen mag, kann sich bei näherem Hinschauen als neu auftretendes wiederkehrendes Muster erweisen.
Der Anomalieerkennungsjob liefert Hypothesen zur Erklärung der Daten. Diese gewichtet und mischt er anhand der verfügbaren Evidenzdaten. Alle Hypothesen sind Wahrscheinlichkeitsverteilungen. Das bedeutet, dass wir mit einem Konfidenzintervall angeben können, wie „normal“ unsere Beobachtungen sind. Beobachtungen, die nicht in dieses Konfidenzintervall fallen, gelten als Anomalie.
Faktoren, die den Anomalie-Score beeinflussen
Sie denken jetzt vielleicht: „Das ist ja mal eine geradlinige Theorie.“ Aber wenn wir unerwartetes Verhalten beobachten, wie können wir quantifizieren, wie unnormal es ist?
Der anfängliche Anomalie-Score, den wir Datensätzen zuweisen, wird von drei Faktoren bestimmt:
- Einzel-Bucket-Einfluss
- Multi-Bucket-Einfluss
- Anomaliemerkmale-Einfluss
Kurz zur Erinnerung: Anomalieerkennungsjobs teilen die Zeitreihendaten in sogenannte Zeit-Buckets auf. Die Daten innerhalb eines Buckets werden mithilfe von Funktionen aggregiert. Die Bucket-Werte bilden die Grundlage für die Anomalieerkennung. Wenn Sie mehr über Buckets und darüber erfahren möchten, warum es so wichtig ist, die richtigen Buckets auszuwählen, lesen Sie diesen Blogpost.
Zunächst einmal schauen wir uns die Wahrscheinlichkeit des Ist-Wertes im Bucket im Kontext der Hypothesenmischung an. Diese Wahrscheinlichkeit hängt davon ab, wie viele ähnliche Werte wir in der Vergangenheit gesehen haben. Häufig bezieht sie sich auf den Unterschied zwischen dem Ist-Wert und dem typischen Wert. Als typischer Wert gilt der Medianwert der Wahrscheinlichkeitsdistribution für den Bucket. Diese Wahrscheinlichkeit führt zum Einzel-Bucket-Einfluss. Dieser dominiert in der Regel den anfänglichen Anomalie-Score eines plötzlichen kurzen Anstiegs oder Abfalls von Werten.
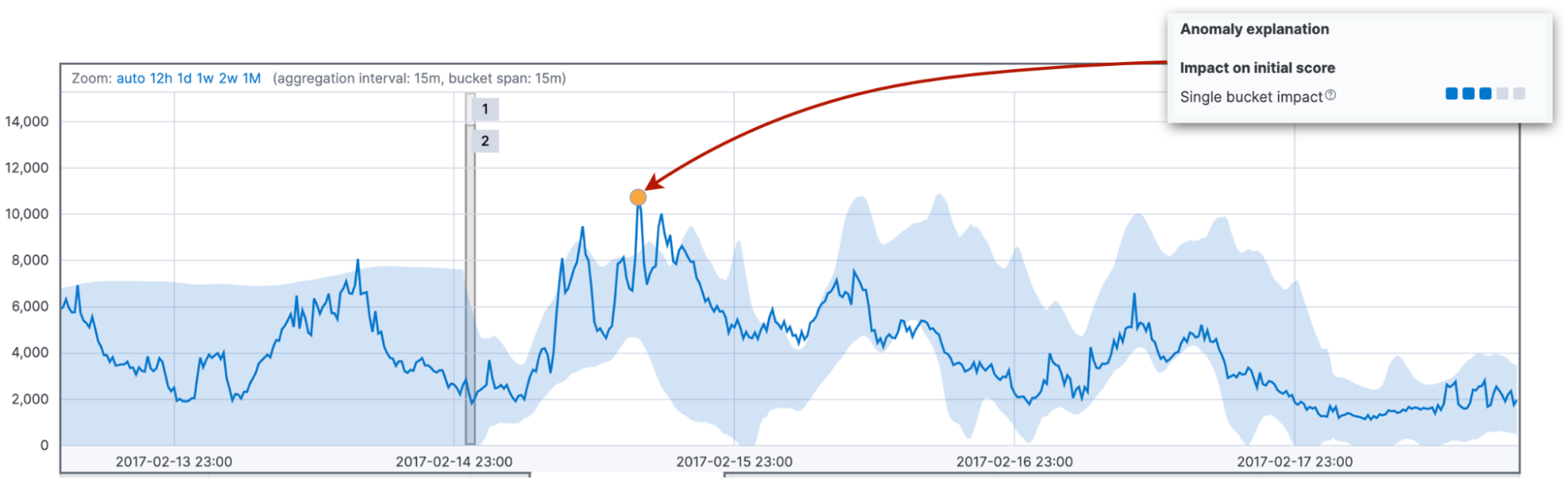
Als Zweites sehen wir uns die Wahrscheinlichkeiten der Beobachtung der Werte im aktuellen Bucket zusammen mit den 11 vorherigen Buckets an. Aus den zusammengefassten Differenzen zwischen Ist- und typischen Werten ergibt sich der Multi-Bucket-Einfluss auf den anfänglichen Anomalie-Score des aktuellen Buckets.
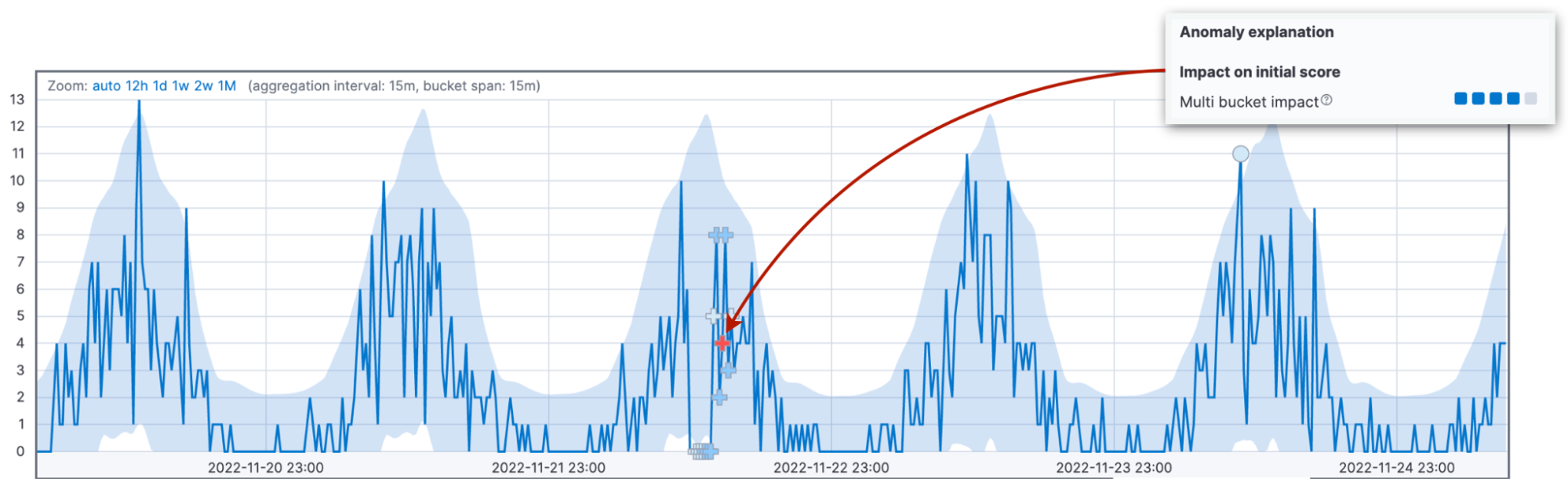
Lassen Sie uns auf diesen Gedanken etwas näher eingehen, denn der Multi-Bucket-Einfluss ist der zweithäufigste Grund für Unklarheiten beim Thema Anomalie-Scores. Wir sehen uns die kombinierten Abweichungen in 12 Buckets an und weisen dem aktuellen Bucket den Einfluss zu. Ein hoher Multi-Bucket-Einfluss weist auf ungewöhnliches Verhalten im dem aktuellen Intervall vorausgehenden Intervall hin, auch wenn der aktuelle Bucket-Wert möglicherweise wieder im 95‑%-Konfidenzintervall liegt.
Um diesen Unterschied hervorzuheben, nutzen wir sogar unterschiedliche Markierungen für Anomalien mit hohem Multi-Bucket-Einfluss. Wenn Sie sich die Multi-Bucket-Anomalie in der obigen Abbildung einmal genauer ansehen, werden Sie feststellen, dass die Anomalie nicht wie üblich mit einem Kreis, sondern mit einem Kreuz-Symbol (+) markiert wurde.
Zu guter Letzt sehen wir uns den Einfluss der Anomaliemerkmale wie Länge und Größe an. Dabei berücksichtigen wir diesmal nicht ein festes Intervall, sondern die Gesamtdauer der Anomalie bis zum jetzigen Zeitpunkt. Das kann ein einzelner Bucket sein oder dreißig. Der Vergleich der Länge und Größe der Anomalie mit den historischen Durchschnittswerten ermöglicht es uns, bei unserer Einschätzung die Besonderheiten des Kunden und der Muster in seinen Daten zu berücksichtigen.
Außerdem weist der Algorithmus standardmäßig längeren Anomalien einen höheren Score zu als kurzzeitigen Spitzen. In der Praxis sind kurze Anomalien häufig nichts anderes als kleinere Abweichungen in den Daten, während längere Anomalien Handlungsbedarf signalisieren.
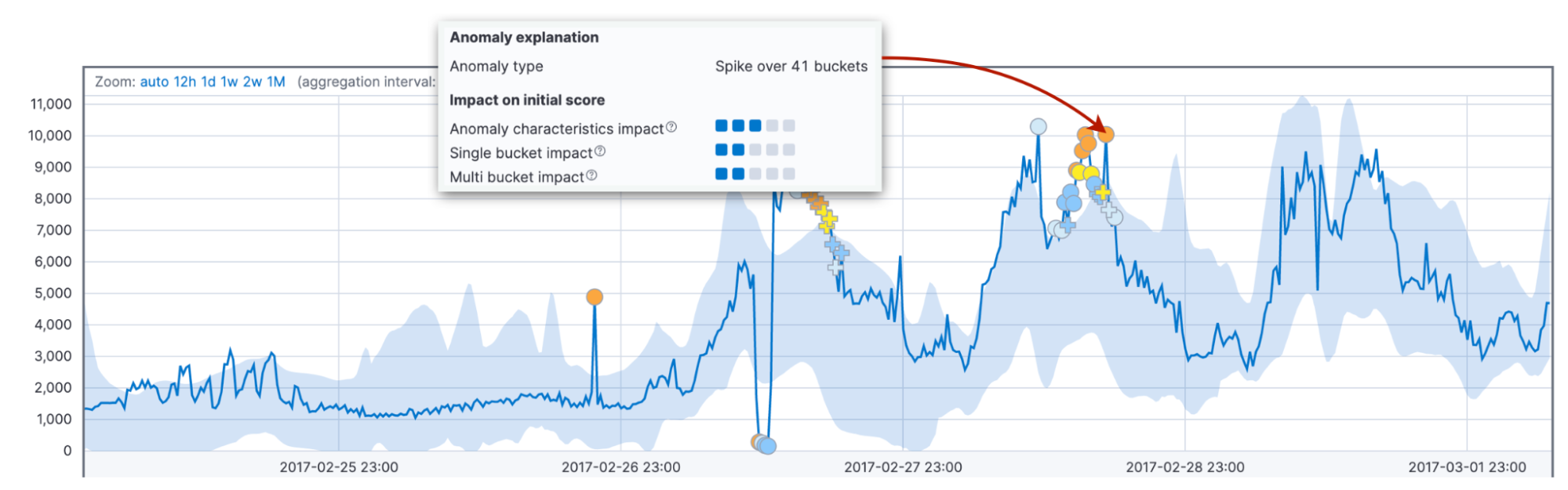
Warum benötigen wir beide Faktoren mit festen und variablen Intervallen? Die Kombination aus beiden macht die Erkennung von Verhaltensanomalien über verschiedene Bereiche hinweg zuverlässiger.
Reduzierung des Datensatz-Scores
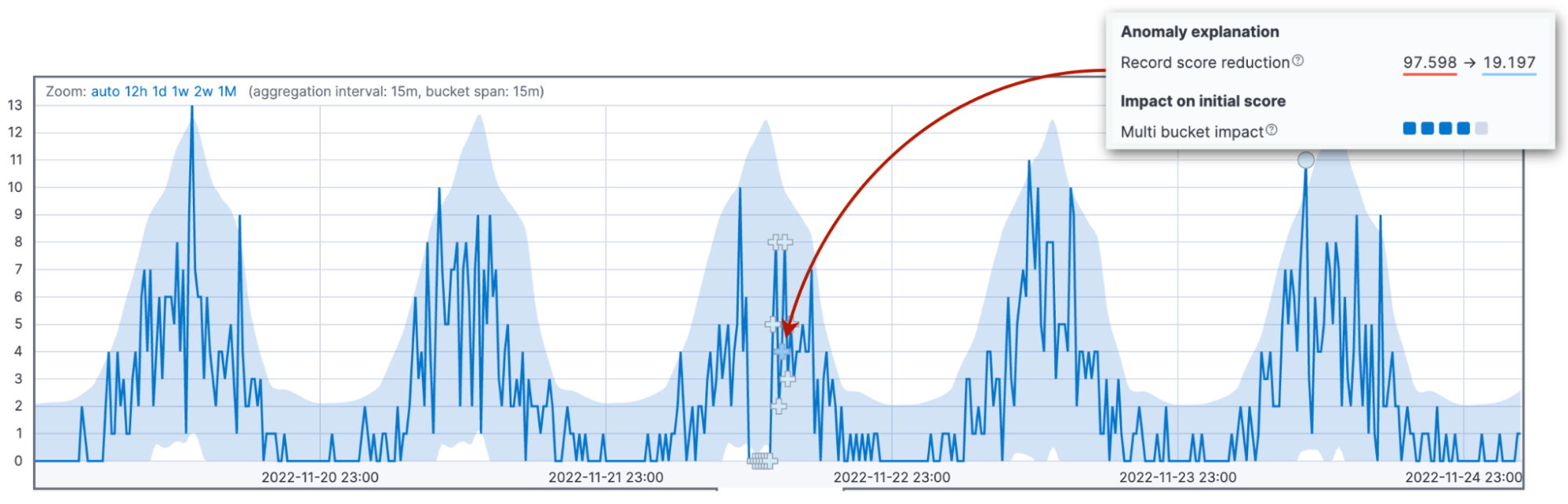
Jetzt ist es an der Zeit, über die häufigste Quelle von Unklarheiten beim Scoring zu sprechen: die Score-Renormalisierung. Anomalie-Scores werden auf einen Bereich von 0 bis 100 normalisiert. Werte in der Nähe der 100 stehen für die größten Anomalien, die der Job bis dato erlebt hat. Das heißt, dass wir beim Auftreten einer Anomalie, die größer ist als alles, was es bisher gab, die Scores der früheren Anomalien reduzieren müssen.
Die drei oben beschriebenen Faktoren wirken sich auf den Wert des anfänglichen Anomalie-Scores aus. Der anfängliche Score ist wichtig, weil er die Basis für die Ausgabe von Alerts bildet. Wenn neue Daten eintreffen, passt der Anomalieerkennungsalgorithmus die Anomalie-Scores der früheren Datensätze entsprechend an. Das Zeitintervall für diese Anpassung wird durch den Konfigurationsparameter renormalization_window_days angegeben. Wenn Sie sich also fragen, warum eine extreme Anomalie nur einen niedrigen Anomalie-Score erhält, kann dies daran liegen, dass der Job im weiteren Verlauf noch signifikantere Anomalien erlebt hat.
Die Ansicht „Single Metric Viewer“ in Kibana 8.6 hebt diese Änderung hervor.
Andere Faktoren für die Reduzierung des Scores
Es gibt auch noch zwei weitere Faktoren, die zu einer Reduzierung des anfänglichen Scores führen können: ein hohes Varianzintervall und ein unvollständiger Bucket.
Die Anomalieerkennung ist weniger zuverlässig, wenn der aktuelle Bucket Teil eines saisonalen Musters mit hoher Variabilität bei den Daten ist. Nehmen wir zum Beispiel an, dass Sie Serverwartungsjobs haben, die jede Nacht um 0:00 Uhr starten. Diese Jobs können zu einer hohen Variabilität in der Latenz der Anfrageverarbeitung führen.
Zudem steigt die Zuverlässigkeit, wenn es für den aktuellen Bucket eine ähnliche Zahl von Beobachtungen gibt wie die historischen Werte erwarten lassen.
Alles zusammengeführt
Anomalien in der realen Welt zeigen häufig die Einflüsse verschiedener Faktoren. Wenn man alles zusammennimmt, kann die neue detaillierte „Single Metric Viewer“-Ansicht wie folgt aussehen:
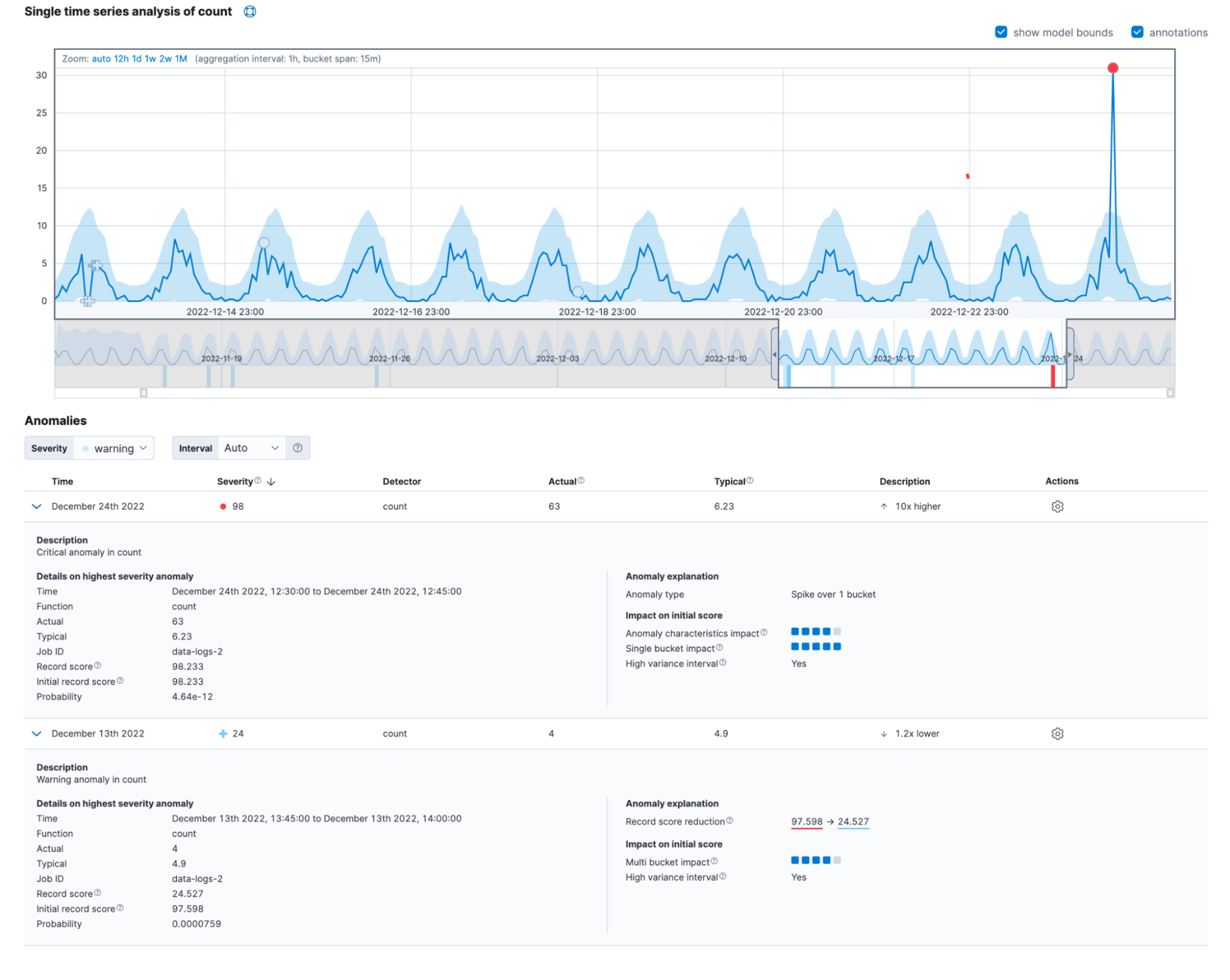
Sie finden diese Informationen auch im Feld anomaly_score_explanation der „get record“-API.
Fazit
Sie sollten die neueste Version von Elasticsearch Service von Elastic Cloud ausprobieren und sich die neue detaillierte Ansicht der Anomaliedatensätze ansehen. Wie wäre es, wenn Sie heute schon damit anfangen, Elastic Cloud kostenlos auszuprobieren und sich die Plattform mit eigenen Augen anzusehen? Viel Spaß beim Experimentieren!
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken