Signalerkennung mit Elastic SIEM
Im Rahmen von Elastic Security 7.6 haben wir auch eine moderne Erkennungs-Engine eingeführt, die SOC-Teams dabei hilft, über eine zentrale Benutzeroberfläche SIEM-Regeln für die Signalerkennung anzuwenden. Die Erkennungs-Engine beruht auf einem eigens dafür konzipierten Satz von Elasticsearch-Analytics-Engines und wird auf einer neuen verteilten Ausführungsplattform in Kibana ausgeführt. In diesem Blogpost geben wir Ihnen einen kurzen Überblick darüber, wie Erkennungen in Elastic SIEM ablaufen, und wir gehen auf die neuen UI- und Backend-Features ein, die dazu beitragen, dass diese Erkennungen für unsere Nutzer reibungslos funktionieren.
Bevor wir uns dem Thema Erkennungen zuwenden, möchten wir alle, die vorhaben, die Elastic SIEM auszuprobieren, noch kurz auf unsere Blogposts zu SIEM für Kleinunternehmen und private Nutzer hinweisen. In diesen Blogposts wird beschrieben, wie Sie mit unserer kostenlosen Elasticsearch Service-Probeversion eine Cloud-Bereitstellung einrichten können, wie Beats Ihnen dabei hilft, die für SIEM gedachten Daten sicher aus Ihren Systemen zu extrahieren und zu streamen, und vieles andere mehr. (Das geht alles wesentlich einfacher als Sie vielleicht denken!) Wir bieten auch einen Einführungsleitfaden für Hybrid-Bereitstellungen.
UI-Workflow für die Signalverwaltung
Erkennungen in Elastic SIEM beruhen auf sogenannten „Signalen“. Das sind Elasticsearch-Dokumente, die erstellt werden, sobald die Bedingungen einer Regel für die Signalerkennung erfüllt sind. Im einfachsten Fall wird für jedes Ereignis, das der in der Regel definierten Abfrage entspricht, genau ein Signaldokument erzeugt. Das Signaldokument enthält eine Kopie der Felder aus dem übereinstimmenden Dokument und wird in einem separaten Signale-Index aufbewahrt. Die ursprünglichen Ereignisse bleiben dabei unverändert.
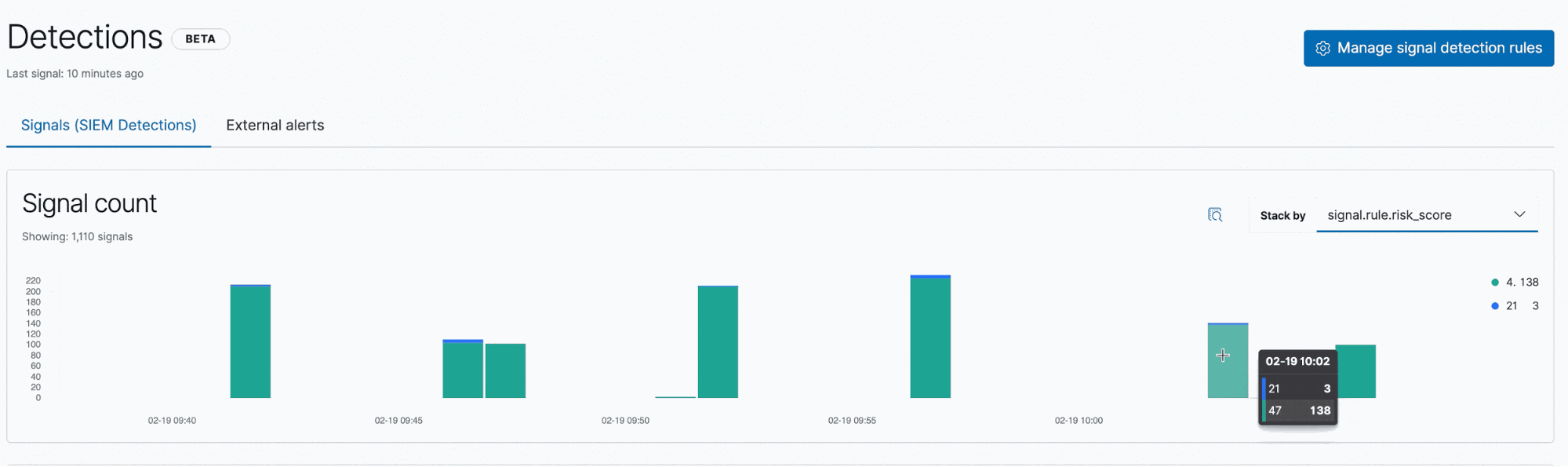
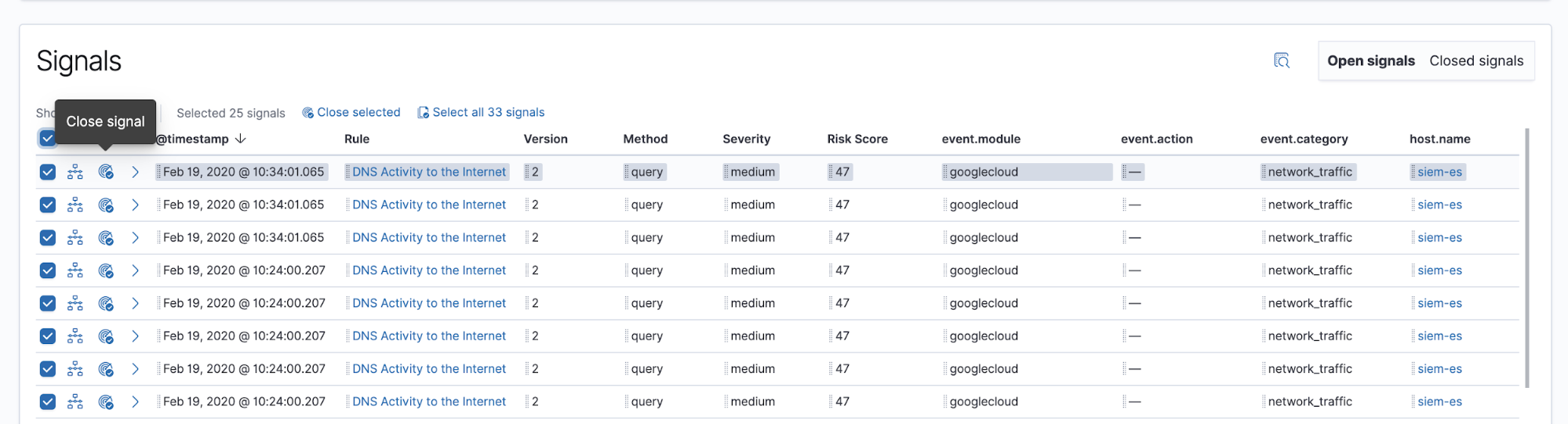
Die Signale werden in der App Elastic SIEM angezeigt. Wenn ein Data Practitioner ein neues Signal zum ersten Mal sieht, ist dieses zunächst offen. Nach der Analyse und der Festlegung der nächsten Schritte wird das Signal vom Practitioner geschlossen. Alle diese Änderungen können über die Elastic SIEM-Ansicht „Detections“ vorgenommen werden.
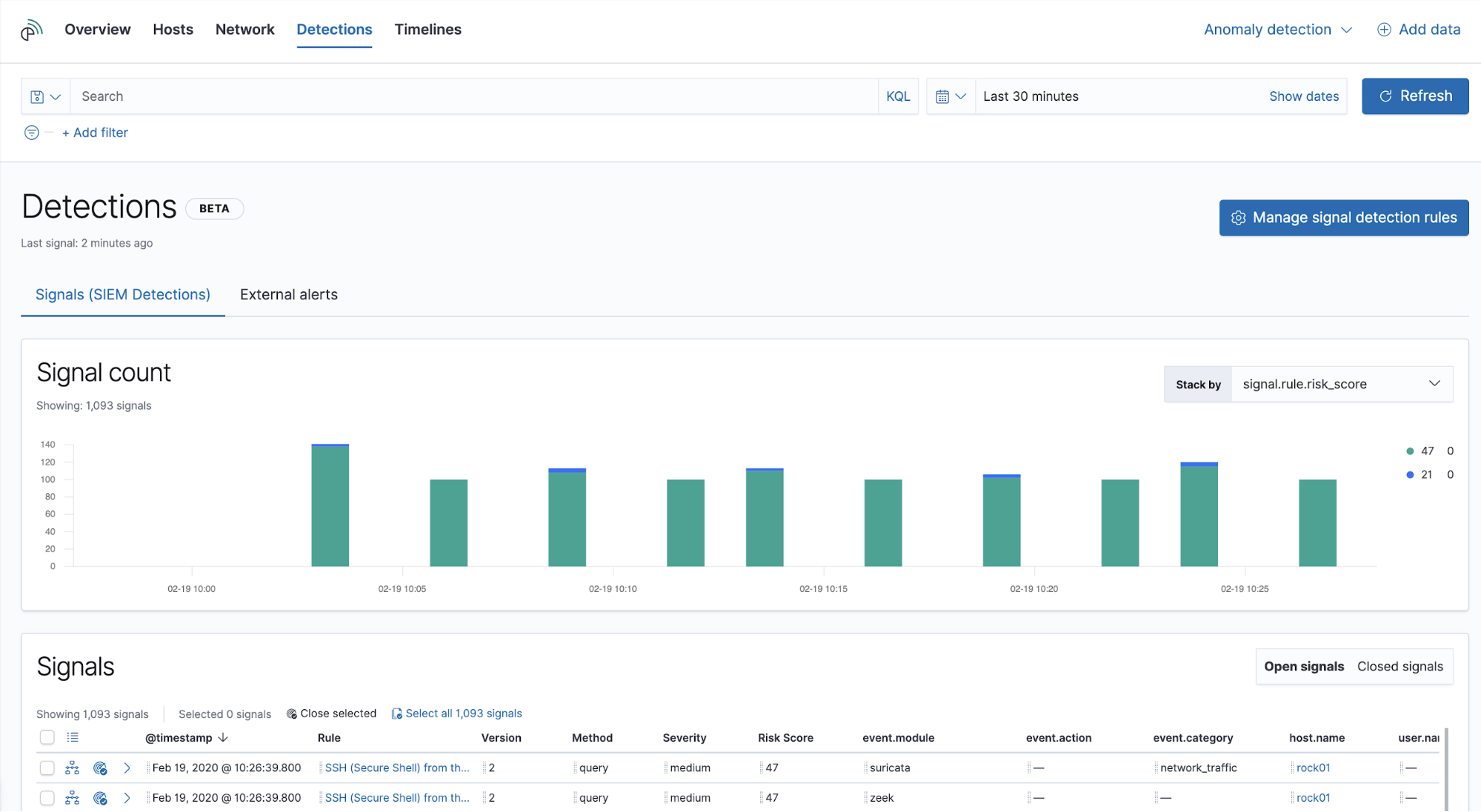
Das Histogramm zur Zahl der Signale zeigt, wie viele Signale offen sind, und ermöglicht schnelle Vergleiche der verschiedenen Schlüsselattribute:
- Score, Schweregrad, Typ, Name oder Name der MITRE ATT&CK™-Taktik
- Ausgangs- oder Ziel-IP-Adresse
- Ereignis-Maßnahmen oder Ereignis‑Kategorie
- Host- oder Nutzername
Als Nächstes sind Signale in der Zeitleiste zu untersuchen:
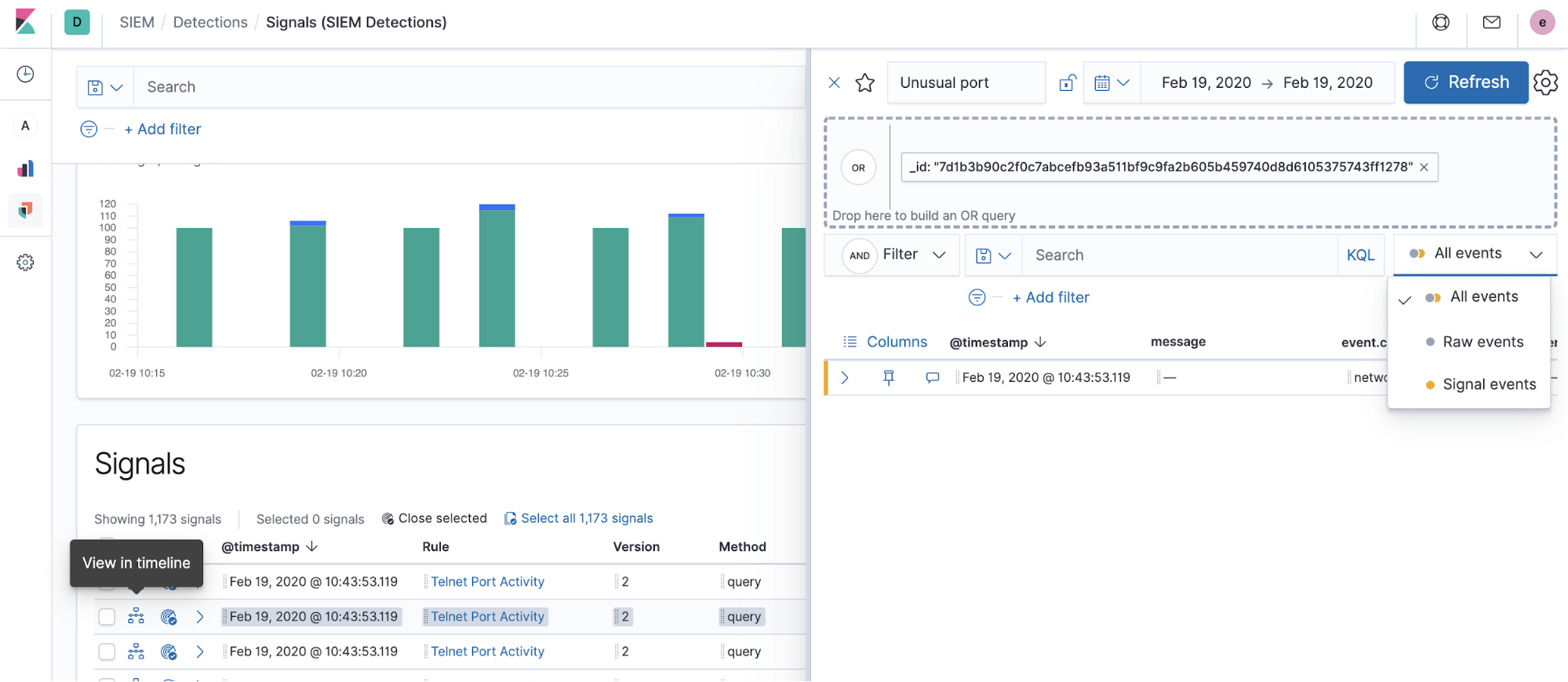
Wenn Sie beim Erstellen einer Regel keine Zeitleistenvorlage angegeben haben, wird in der Zeitleiste ein Signaldokument angezeigt. Wurde jedoch eine Zeitleistenvorlage angegeben, wird in der Zeitleiste das angezeigt, was der Nutzer gespeichert hat. So lassen sich bei bestimmten Regelarten die Untersuchungszeiten verkürzen.
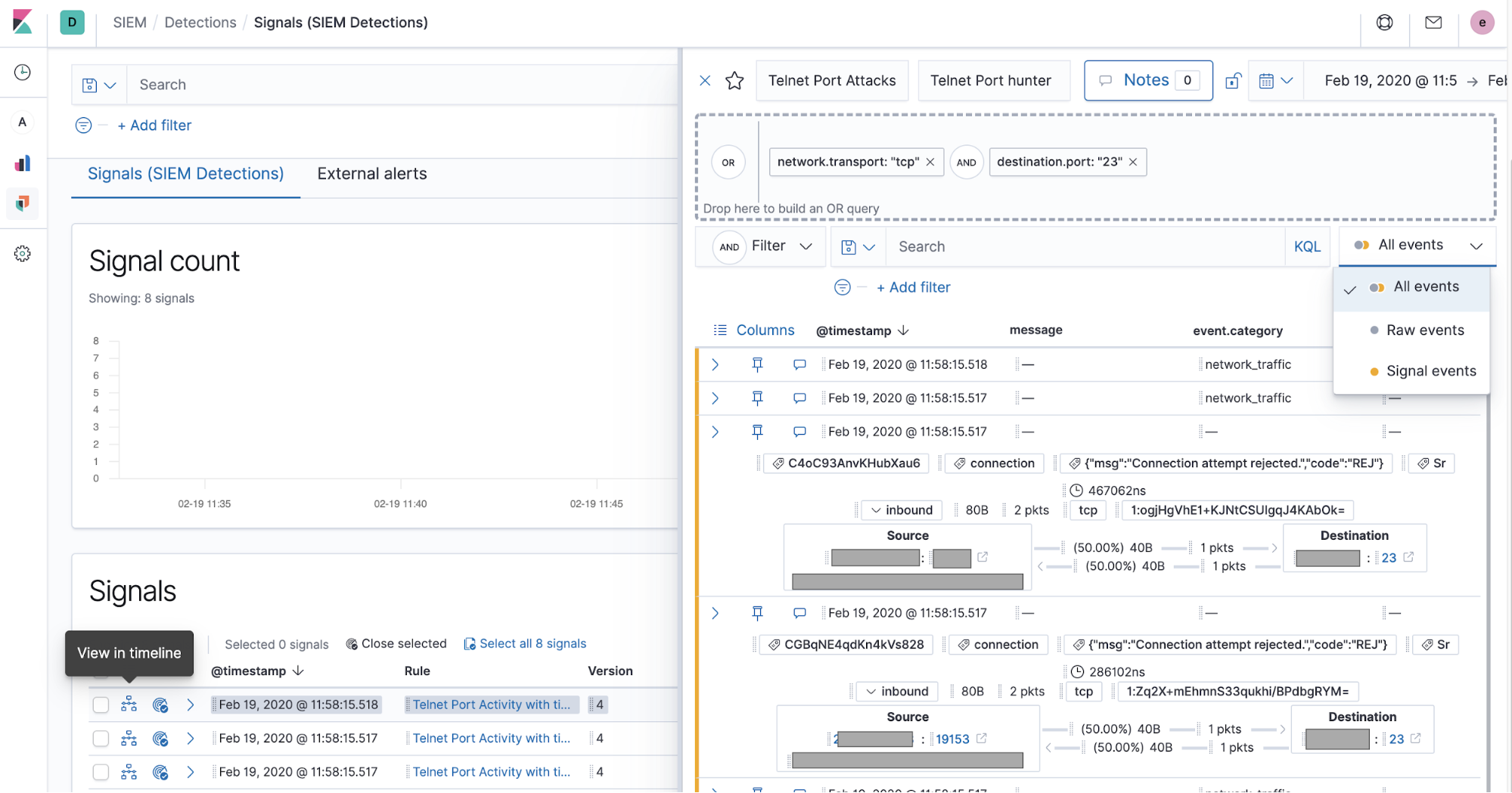
Auf dem Tab `External alerts` können sich Practitioner auch Alerts aus externen Alerting-Systemen, wie Elastic Endpoint Security, Suricata oder Zeek, ansehen. In vielen Unternehmen werden auch Regeln zur Erzeugung von Signalen bei wichtigen externen Alerts implementiert, sodass die Nutzer zusätzliche Untersuchungsmöglichkeiten für Signale erhalten.
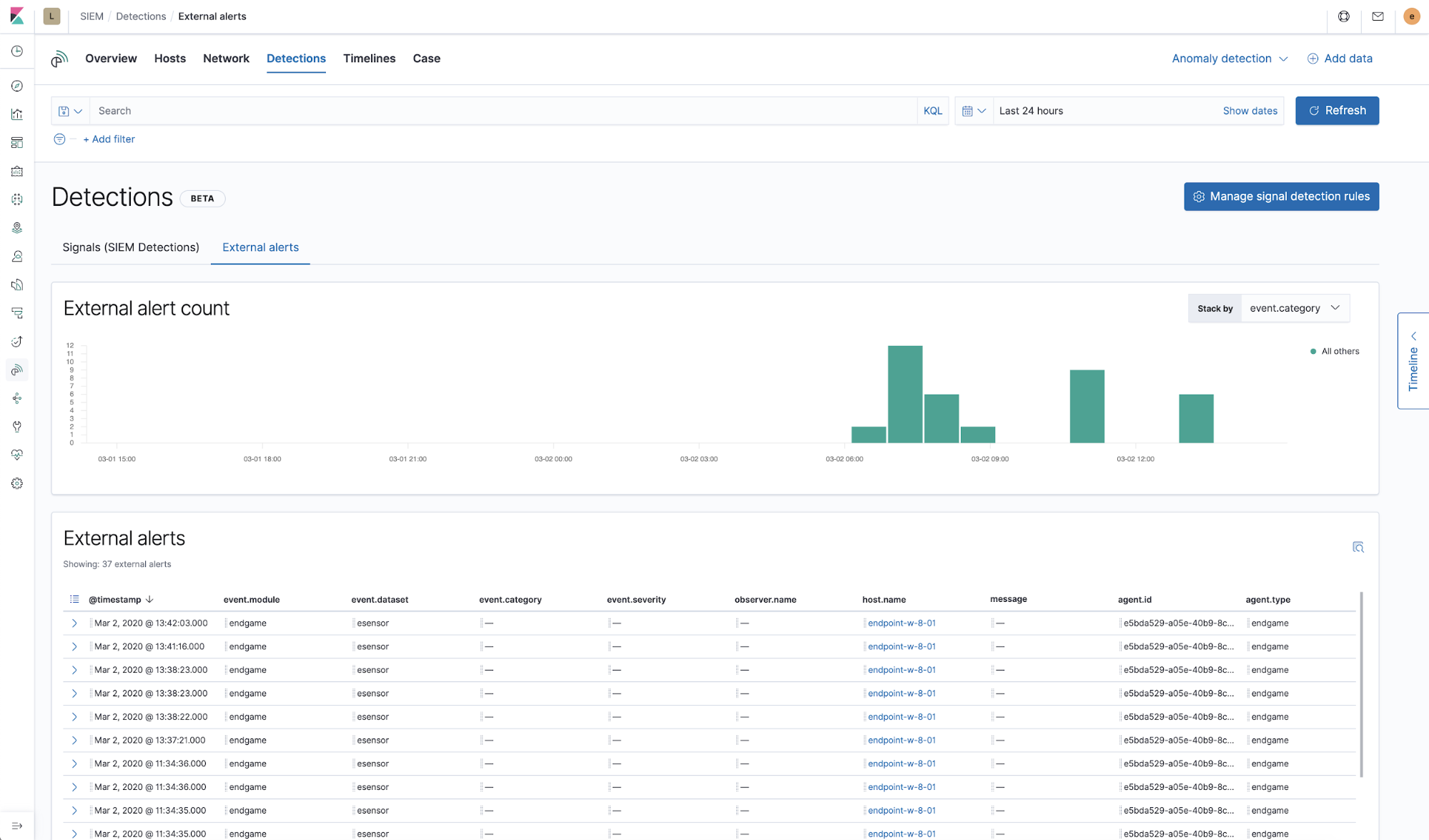
Der Practitioner kann das Signal oder die Gruppe von Signalen nach Abschluss der Untersuchung entweder einzeln oder alle zusammen schließen. Falls erforderlich, können einmal geschlossene Signale auch wieder geöffnet werden. Wir arbeiten daran, das Schließen von Signalen künftig zu automatisieren.
UI-Workflow für die Regelerstellung
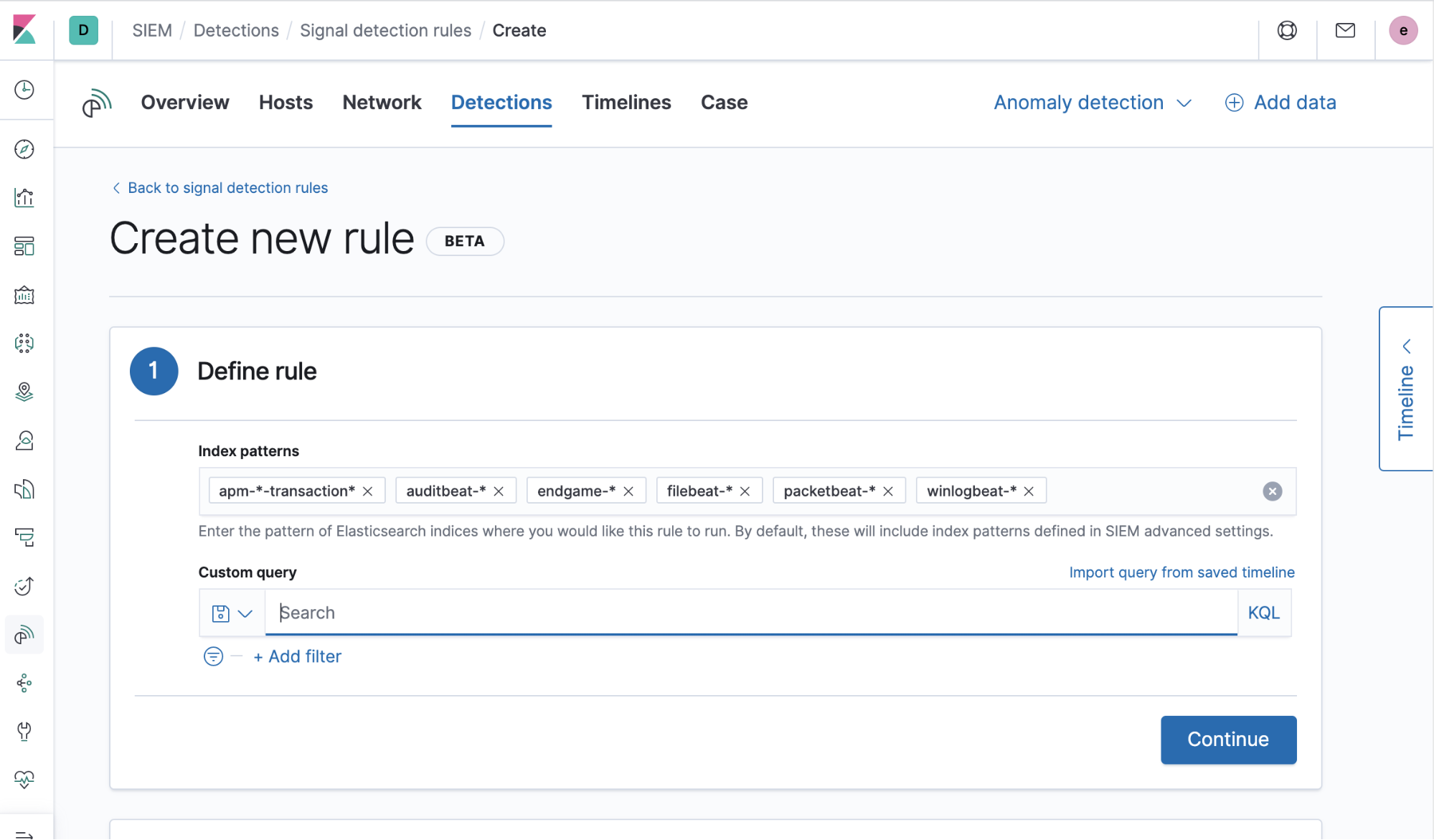
Damit Signale angezeigt werden können, müssen entsprechende Erkennungsregeln erstellt werden. Das Erstellen einer Regel für SIEM-Erkennungen ist ganz einfach. Im Grunde genommen besteht der Vorgang aus drei Schritten:
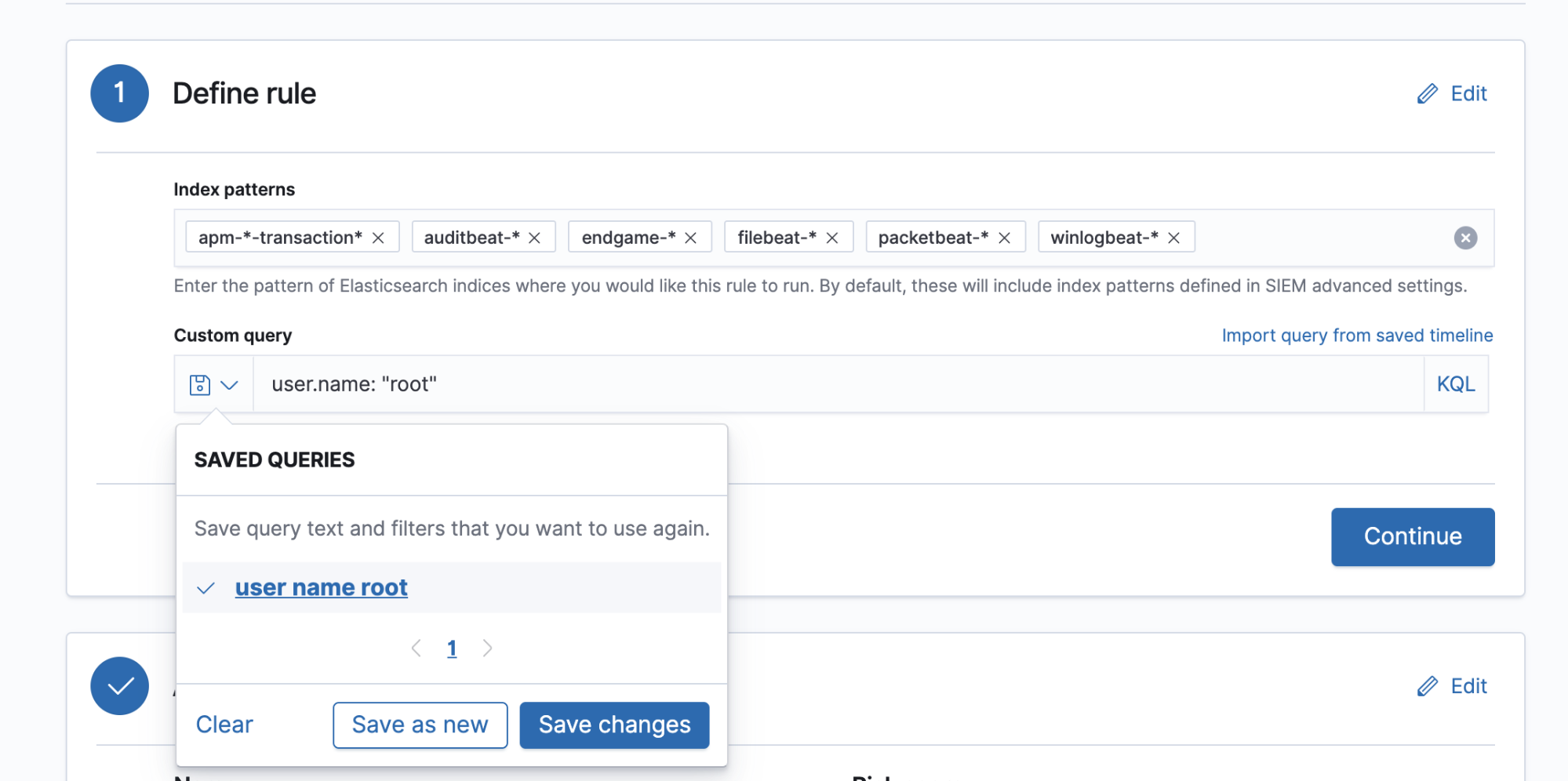
1) Erstellen der Abfrage, die bei jeder Regelausführung verwendet werden soll. Diese Abfrage kann in Form von Lucene-Syntax, einer KQL-Abfrage oder einer gespeicherten Suche vorliegen oder die Abfrage kann aus einer gespeicherten Zeitleiste importiert werden (in zukünftigen Versionen wird es etliche weitere Optionen für Regelabfragen geben):
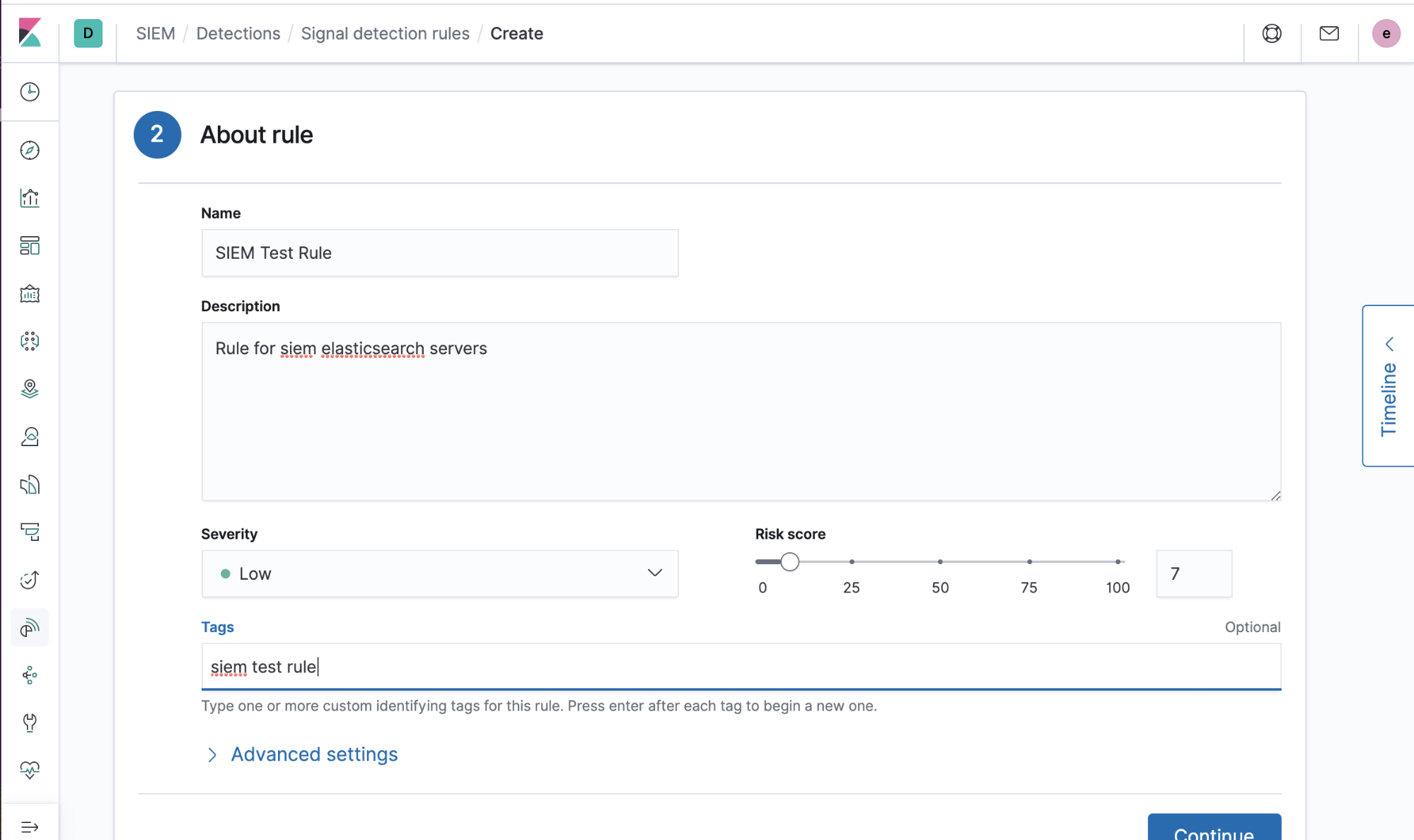
2) Hinzufügen von Informationen zur Beschreibung der Regel (Name, Beschreibung und so weiter):
3) Festlegen des Intervalls, in dem die Regel ausgeführt werden soll, und optional einer zusätzlichen Rückschauzeit, damit keine Signale verpasst werden. Wir empfehlen prinzipiell die Festlegung einer Rückschauzeit (Option „Additional look-back time“), um eventuelle Verzögerungen in der Ingestion-Pipeline des Nutzers aufzufangen. Außerdem wird die Festlegung einer Rückschauzeit empfohlen, weil die genaue Einhaltung des angegebenen Intervalls nicht garantiert werden kann, sodass zwischen den Ausführungen Verzögerungen möglich sind. Solche Verzögerungen können bei Überlastung der Task-Manager-Worker-Warteschlange oder bei unzureichenden Ressourcen für Rechenoperationen entstehen.
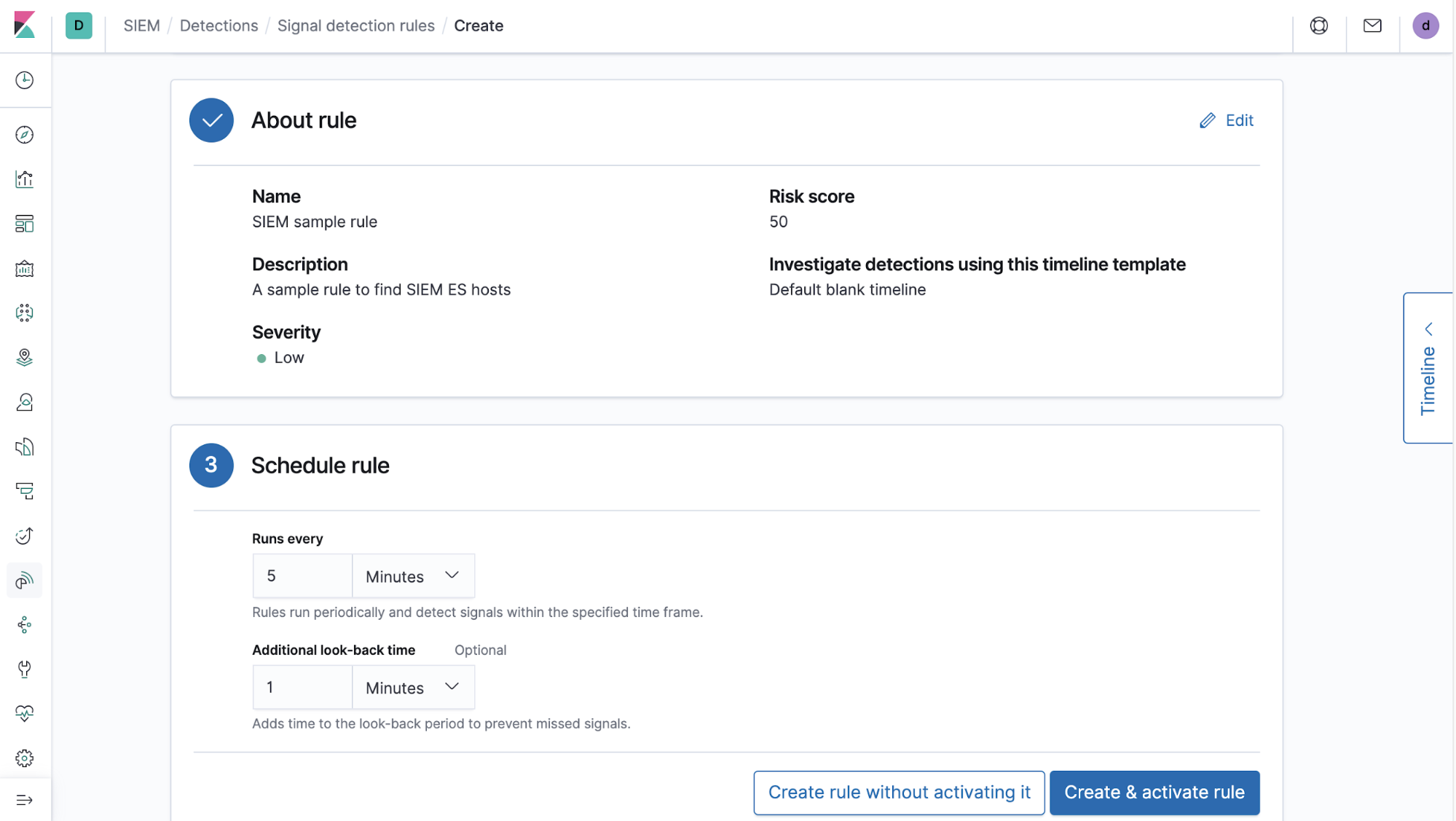
Diese drei Dinge bilden die Grundkomponenten, aus denen eine Erkennungsregel besteht. Darüber hinaus stellen wir Einstellungen zur Klassifizierung der Regel gemäß den MITRE ATT&CK-Taktiken und ‑Verfahren sowie Links zu zusätzlichen Referenzquellen bereit.
![]()
Nutzer können zudem bestehende Regeln verwalten, indem sie sie – einzeln oder alle zusammen – duplizieren (um sie individuell anzupassen), deaktivieren, exportieren oder löschen. Wenn Sie mehr erfahren möchten, sehen Sie sich unseren Leitfaden zur allgemeinen Verwaltung von Regeln an.
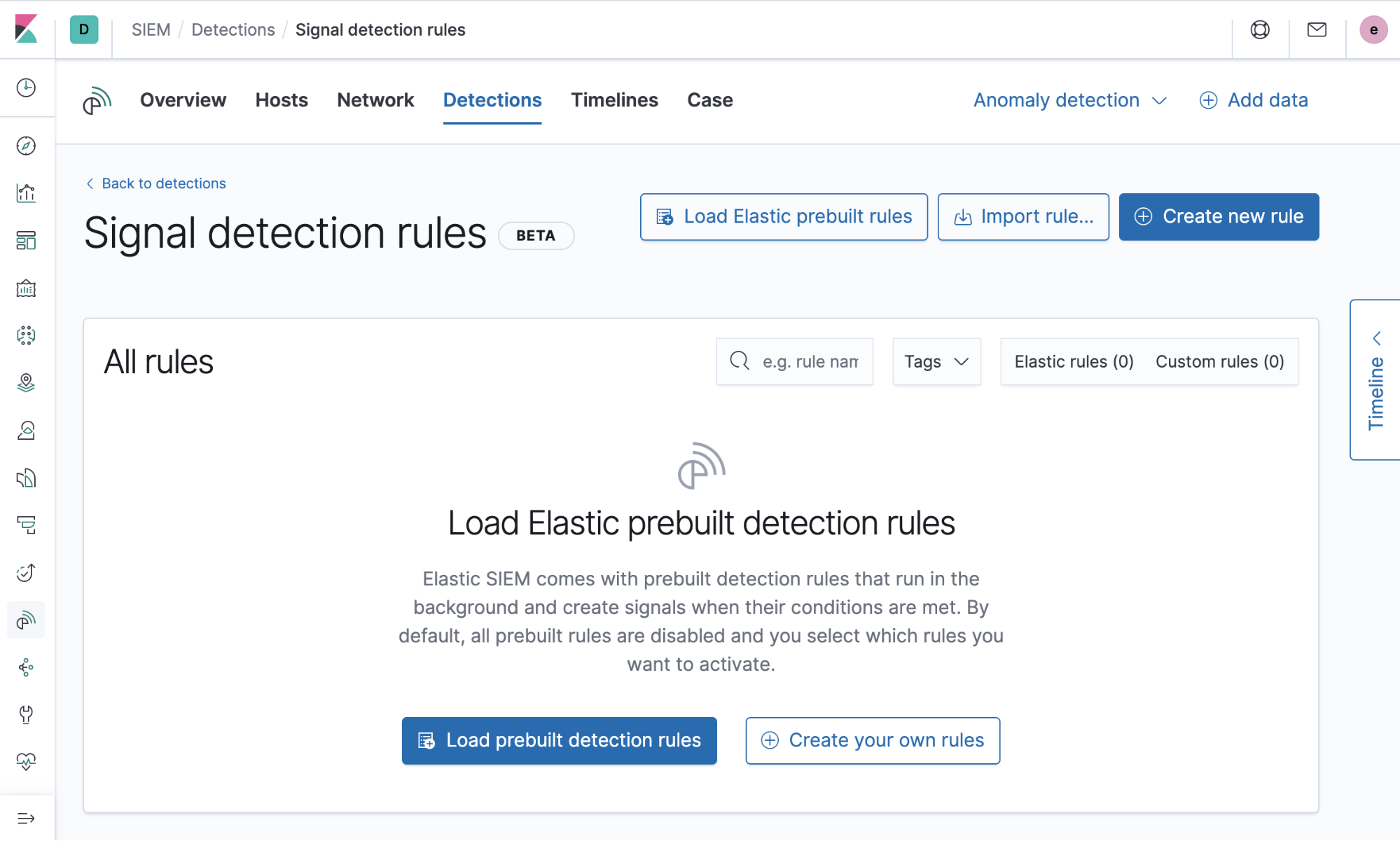
Vordefinierte Regeln
Das Entwickeln von Regeln ist oftmals nicht ganz ohne und das Testen dieser Regeln erfordert viel Zeit. Aus diesem Grund stellen wir 92 vordefinierte Regeln zur Verfügung, die vom „Intelligence & Analytics“-Team bei Elastic Security entwickelt worden sind und ausführlich in einer Produktionsumgebung bei Elastic getestet wurden. Wir arbeiten ständig an der Entwicklung neuer Regeln, um auf die neuesten kritischen Bedrohungen reagieren zu können. Diese lassen sich mit einem einfachen Klick laden und zur Ausführung bereitstellen. Mehr dazu, wie Sie die vordefinierten Regeln nutzen und feinjustieren können, erfahren Sie hier.
Details zur Implementierung von Erkennungsregeln
Kurz nachdem Alerting im Elastic Stack Einzug in Kibana gehalten hat, um dort Alerts als Entities erster Klasse zu unterstützen, wurde auch in Elastic SIEM das Alerting als Fundament für die Signalerkennung („Detections“) eingeführt. Hinter der Benutzeroberfläche arbeitet dabei eine API, die auf die Alerting-API aufsetzt. Die SIEM-Detections-API bietet Komfort, Workflows (wie das Öffnen und Schließen von Signalen), Domain-spezifische Security-Funktionen (wie MITRE ATT&CK-Identifizierung) und Unterstützung für KQL.
Regeln werden im Hintergrund ausgeführt, wobei zunächst ein API-Schlüssel erstellt wird, mit dem dann im Namen des Nutzers Anfragen gestellt werden. Zum Finden passender Ereignisse im Namen des Nutzers wird dabei der Parameter `search_after` verwendet, während zum Kopieren der Informationen aus dem Ereignis in ein Signaldokument im Signale-Index die Bulk API-Aktion „create“ zum Einsatz kommt. Ein Signal besteht aus den Details der Regel und dem ursprünglichen Ereignisdokument, das die Regelbedingungen erfüllt.
Wenn bei einer der Regelausführungen mehr als 100 Treffer gefunden werden, werden nur die letzten 100 Treffer (bei absteigender Sortierung nach dem `@timestamp`-Wert) in den Signale-Index kopiert. Der Signale-Index wird für jeden Kibana-Space automatisch erstellt, wenn Sie zum ersten Mal die Seite mit den Signalerkennungsregeln besuchen. Der Indexname hat das Format `.siem-signals-
Das Mapping des SIEM-Signale-Index ist eine Kombination aus Elastic Common Schema (ECS)-Mapping und einem benutzerdefinierten Mapping unserer Definition dessen, was ein Signal ist. Wenn eine Regelabfrage ein passendes Dokument findet, kopiert es die Felder aus den Ausgangsindizes herüber. Die sich dabei ergebenden Signalfelder sind durchsuchbar, sofern die Felder im Quelldokument ECS-konform sind. Sind die Felder aus den Ausgangsindizes nicht Teil des ECS, werden diese dennoch am `_source`-Speicherort des Signals gespeichert und können dann in der Zeitleiste und anderen Teilen der Anwendung aufgerufen werden. Sie sind aber nicht durchsuchbar.
Skalierbarkeit
Die Benutzeroberfläche für die Signalerkennung beruht auf dem neu entwickelten Kibana-Alerting-Framework und dem Kibana-Task-Manager. Beide stellen Funktionen zum horizontalen und vertikalen Skalieren zur Verfügung und bieten so die Flexibilität, die Hardware zu verwenden, die jeweils gerade verfügbar ist. Die Zahl der Kibana-Task-Manager-Worker kann für vertikales Skalieren erhöht werden, oder die Worker können auf andere Kibana-Instanzen repliziert werden, was horizontales Skalieren möglich macht.
Wenn mehrere Kibana-Instanzen ausgeführt werden, stimmen sich die Task-Manager untereinander ab, sodass die Last gleichmäßig auf die Instanzen verteilt wird. Wenn Sie vertikal skalieren möchten, um eine effizientere Ressourcenzuweisung für die einzelnen Kibana-Knoten sicherzustellen, können Sie einfach in der Datei kibana.yml den `max_workers`-Wert ändern. Der Standardwert lautet 10, aber Sie können auch einen höheren oder niedrigeren Wert angeben.
Eliminieren redundanter Signale (Signaldeduplikation)
Wenn eine Regel ausgeführt wird, generiert sie Signale gemäß den Ereignissen, die die Bedingungen der Regelabfrage erfüllen. Dabei kann es passieren, dass Signale doppelt erzeugt werden, weil sich die Abfragen in zwei verschiedenen Regeln überschneiden oder weil eine Regel aufgrund einer langen Rückschauzeit bei zwei aufeinanderfolgenden Ausführungen das Signal zweimal erkennt. Um zu verhindern, dass Signale doppelt in der Signale-Tabelle auftauchen, identifizieren wir Signale anhand des Index, aus dem das Ausgangsereignis stammt, der Kennnummer des Dokuments der Ausgangsquelle, der Versionsnummer des Ausgangsereignisses und der Kennnummer der ausgeführten Regel. Durch eine Hash-Operation mit diesen Eigenschaften können wir sicherstellen, dass nur eindeutige Signale in den Signale-Index aufgenommen werden.
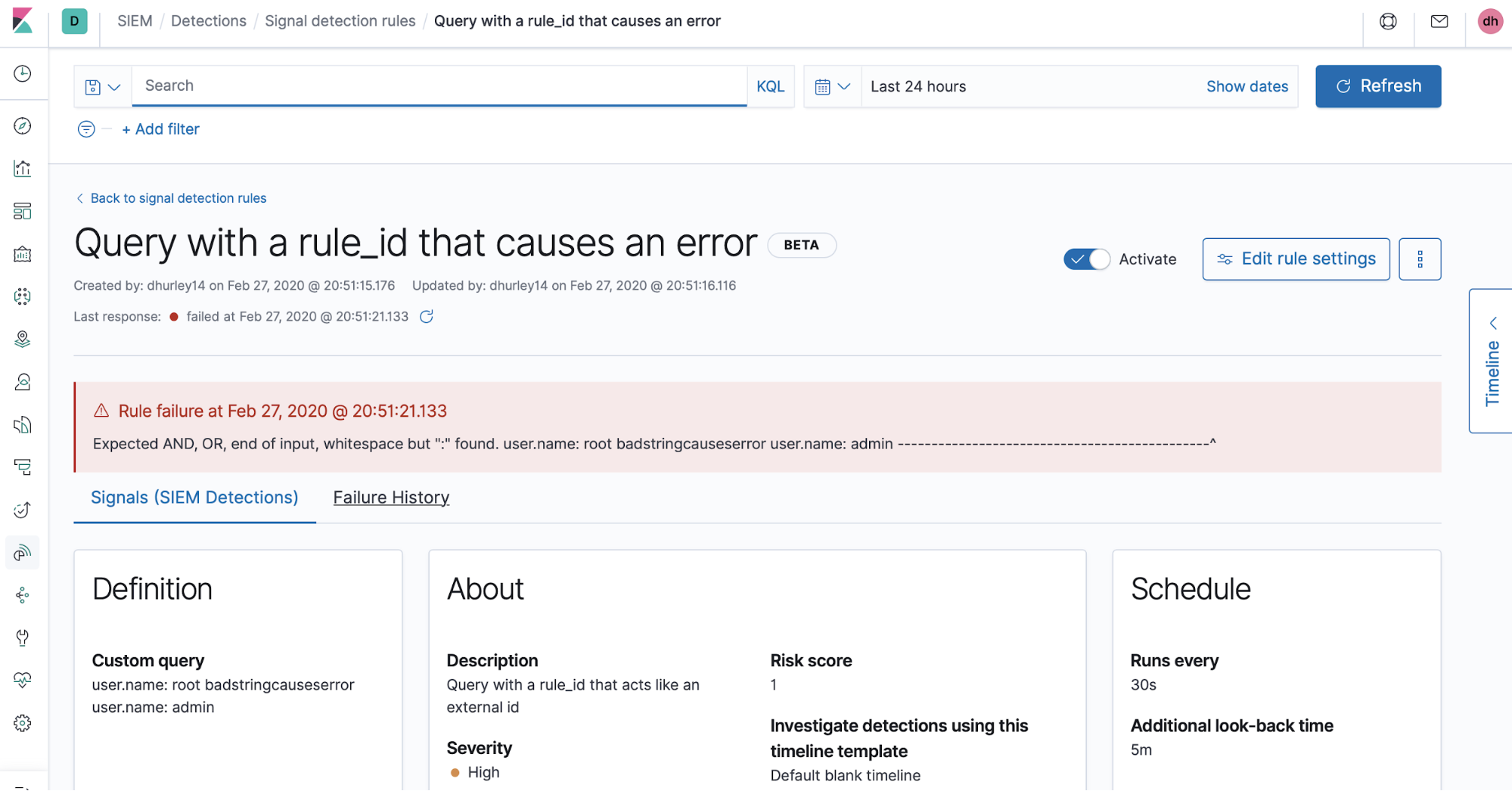
Fehlermeldungen
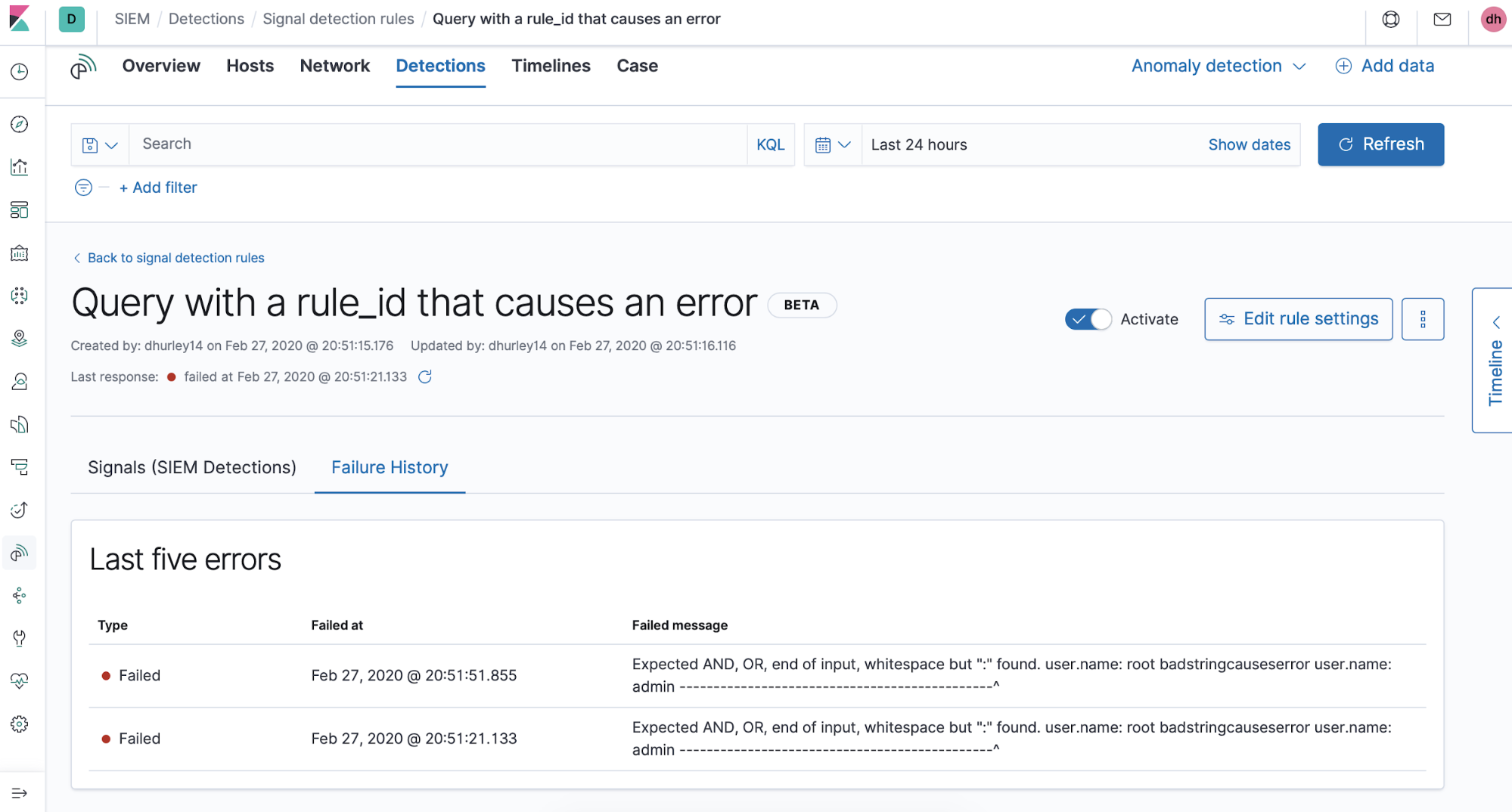
Es kann vorkommen, dass es aufgrund eines Syntaxfehlers in einer Regelabfrage oder eines anderen Problems während der Ausführung einer Regel zu Fehlermeldungen kommt. Diese Fehlermeldungen werden auf dem Tab „Failure history“ der Seite mit den Regeldetails angezeigt. Für die Zukunft ist geplant, die Sichtbarkeit von Informationen zur Regelausführung und das allgemeine Regel-Monitoring zu erweitern.
Und hier sehen wir Informationen zu gemeldeten Fehlern. Angezeigt werden die letzten fünf bei der Regelausführung aufgetretenen Fehlermeldungen:
Ausblick in die Zukunft der SIEM-Erkennung
Zu den spannendsten Aspekten der Arbeit an dieser Betaversion der Elastic SIEM-Funktion zur Erkennung von Signalen gehört das frühzeitige und kontinuierliche Community-Feedback im Elastic SIEM-Diskussionsforum und über unsere Liste offener Features.
Wir haben große Pläne, die Erkennungsfunktion noch leistungsfähiger zu machen. So arbeiten wir zum Beispiel an der Erweiterung der Regelabfragen auf Aggregationen, Machine-Learning-Jobs und EQL. Wenn Sie einen guten Security-Anwendungsfall kennen oder Fragen haben, die Sie gern beantwortet haben möchten, machen Sie doch einfach bei uns mit!