APM-Korrelationen in Elastic Observability: automatische Ermittlung der wahrscheinlichen Ursachen für langsame oder fehlgeschlagene Transaktionen


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Als DevOps-Engineer oder SRE gehört es zu Ihren Aufgaben, komplexe Probleme zu untersuchen, wie rätselhafte Störungen der Anwendungs-Performance, die immer wieder, aber nicht regelmäßig oder nur bei einem bestimmten Teil Ihres Anwendungs-Traffics auftreten, weil sie negative Auswirkungen auf die Endnutzer:innen und potenziell auch auf das Erreichen der Finanzziele Ihres Unternehmens haben können. Das Durchsuchen Hunderter oder sogar Tausender Transaktionen und Spans ist oft mit viel ermüdender, manueller und zeitraubender Untersuchungsarbeit verbunden. Cloudnative oder verteilte Microservices-Deployments machen die Sache noch komplexer und bei ihnen dauert die Ursachenermittlung dann auch länger.
Wäre es da nicht toll, einfach ein häufiges Muster anklicken zu können, um eine Erklärung für dieses anscheinend komplexe Problem zu erhalten, und es so nicht nur weniger rätselhaft zu machen, sondern auch den Weg für eine schnellere Ursachenanalyse und ‑beseitigung zu ebnen?
Die magische Kraft von APM-Korrelationen in Elastic Observability
Die Elastic-Funktion „APM-Korrelation“ fördert automatisch Attribute der APM-Daten zutage, die mit hoher Latenz oder Fehlerträchtigkeit von Transaktionen in Zusammenhang stehen und damit die Gesamt-Performance Ihres Dienstes am meisten beeinträchtigen.
Untersuchungen von APM-Problemen beginnen in der Regel auf dem Tab „Transactions“ der APM-Ansicht. Ganz gleich, ob Sie sich für Transaktionen mit hoher Latenz oder dafür interessieren, welche Transaktionen fehlgeschlagen sind – Sie beginnen damit, im Latenzverteilungsdiagramm der jeweiligen Transaktionsgruppe die Ausreißer zu visualisieren. Transaktionen mit hoher Latenz werden auf der rechten Seite des Diagramms angezeigt und den Beschriftungen für Latenz und fehlgeschlagene Transaktionen können Sie die mit dem Problem verbundenen Auswirkungen entnehmen. Darüber hinaus hilft die Angabe des 95. Perzentils im Diagramm, die wahren Ausreißer optisch von den anderen Daten zu isolieren.
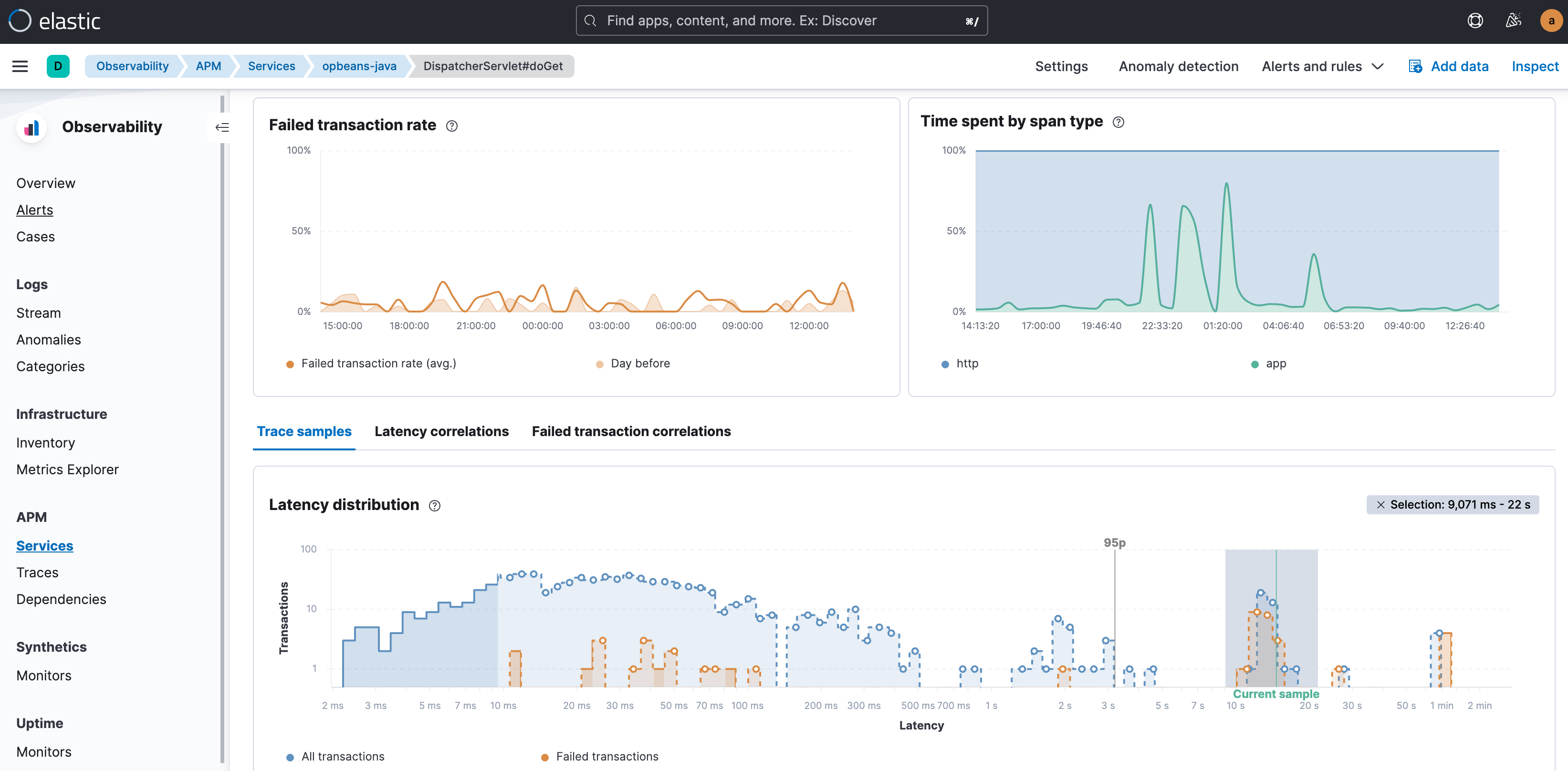
Ihr nächster Schritt sollte nun darin bestehen, nach Attributen und Faktoren in den Daten Ausschau zu halten, die diesen Ausreißern am ehesten entsprechen, und Ihre Untersuchung auf die betroffenen Untergruppen im gesamten Datenbestand einzugrenzen. Mit anderen Worten: Suchen Sie nach Attributen, die in langsamen oder fehlerhaften Transaktionen unverhältnismäßig häufig vertreten sind. Zu diesen Attributen können Labels, Tags, Trace-Attribute und Metadaten, wie Dienstversionen, Geodaten, Angaben zum Gerätetyp, Infrastrukturkennungen, cloudspezifische Label, wie Verfügbarkeitszone, Betriebssystem und Client-Typ bei Frontend-Diensten, sowie eine Reihe anderer Attribute gehören. Sinn und Zweck ist es, die Anomalien der Transaktionen anhand dieser Attribute erklären zu können, also z. B. sagen zu können: „beinahe alle Transaktionen mit hoher Latenz waren im Kubernetes-Pod x anzutreffen“ oder „Transaktionen mit dem Label shoppingCartVolumeHigh und der Dienstversion a.b schlagen fehl“.
Da möchte man sich nicht vorstellen, alle diese Attribute (die auch schon mal in die Hunderte gehen können) manuell durchforsten zu müssen, um herauszufinden, welche konkreten Attribute für die Performance-Ausreißer verantwortlich sein könnten!
Elastic Observability vergleicht die Attribute mit hohen Latenzen und Fehlern mit dem gesamten Satz von Transaktionsdaten und versucht die Tags und Metadaten herauszufinden, die in den suboptimalen Transaktionen „ungewöhnlich gewöhnlich“ sind. Anders ausgedrückt wird versucht, Elemente zu finden, die in suboptimalen Transaktionen deutlich häufiger auftreten als in allen Transaktionen zusammengenommen. Elastic Observability gibt dann nicht nur die Korrelationen an, sondern präsentiert auch die Attribute mit den höchsten Korrelationswerten als erste. Der Korrelationswert (Bereich von 0 bis 1,00, wobei 1,00 für eine perfekte Korrelation steht) gibt Auskunft über das Ausmaß der Übereinstimmung. Wenn Sie auf eines der Attribute klicken, werden in einem Wahrscheinlichkeitsdiagramm farbcodiert die Transaktionen angezeigt, für die dieses Attribut gilt, um die Überlappung zu visualisieren.
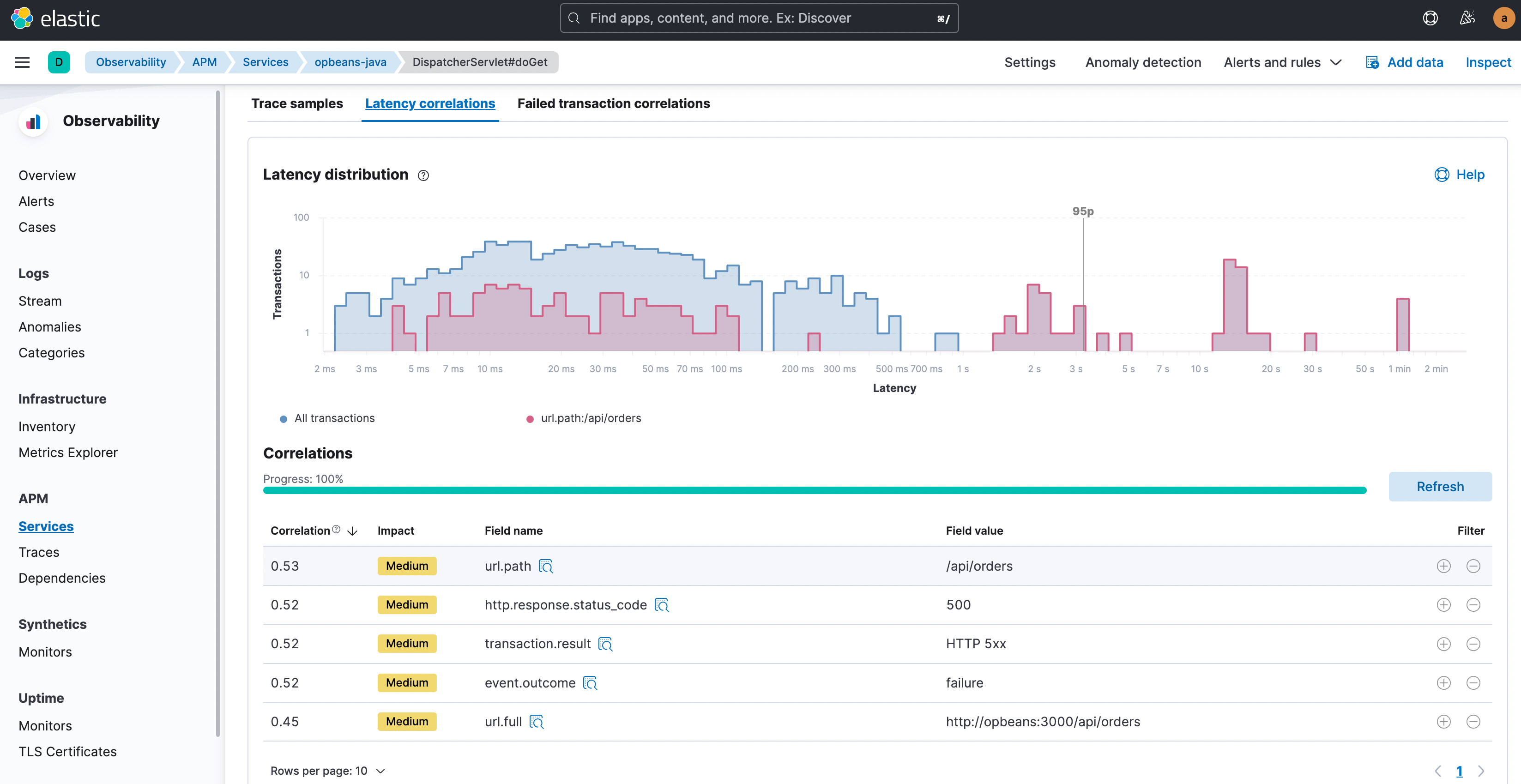
Nachdem Sie diese Korrelationsfaktoren identifiziert haben, können Sie sich jetzt voll und ganz auf diese Transaktionen konzentrieren. Klicken Sie auf die Filterschaltflächen „+“ oder „−“, um nur die Transaktionen auszuwählen, die diesen Attributwert haben, bzw. um ebendiese Transaktionen auszuschließen, und sehen Sie sich die Sie interessierenden Transaktionen genauer an. Ein typischer nächster Schritt in einer Latenzuntersuchung wäre die Prüfung von Trace-Proben nur für die Transaktionen mit hoher Latenz, die auch die zuvor ermittelten Korrelationsattribute aufweisen, und so daran zu arbeiten, zum Schuldigen vorzudringen: einem langsamen Funktionsaufruf in den Traces.
Sobald die Ursache ermittelt ist, können Sie mit dem Prozess der Bekämpfung und Wiederherstellung durch Mechanismen wie Rollbacks, Software-Patching oder Upgrades beginnen.
Lassen Sie uns als Nächstes einen Blick auf das Szenario fehlgeschlagener Transaktionen werfen. Im Beispiel unten wurde festgestellt, dass es bei der Transaktionsgruppe namens „/hipstershop.CheckoutService/PlaceOrder“ im Dienst „checkoutService“ eine hohe Quote fehlgeschlagener Transaktionen gibt.
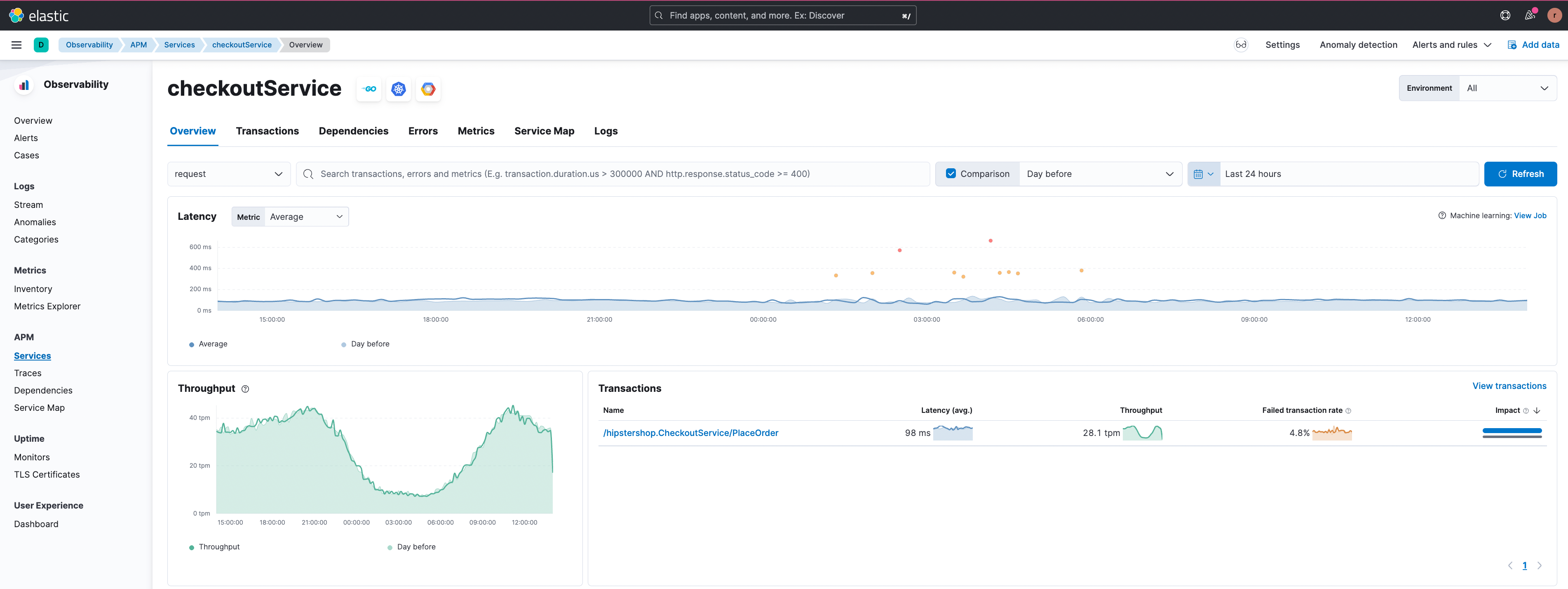
In der folgenden Abbildung zeigt die Korrelationsfunktion für fehlgeschlagene Transaktionen fehlschlagende Transaktionen bei Nutzer:innen aus Südamerika.
Durch Klicken auf die Filterschaltfläche „+“ können Sie sich auf diese Teilmenge von Transaktionen konzentrieren. Es wird eine Beispieltransaktion mit dem Fehler angezeigt.
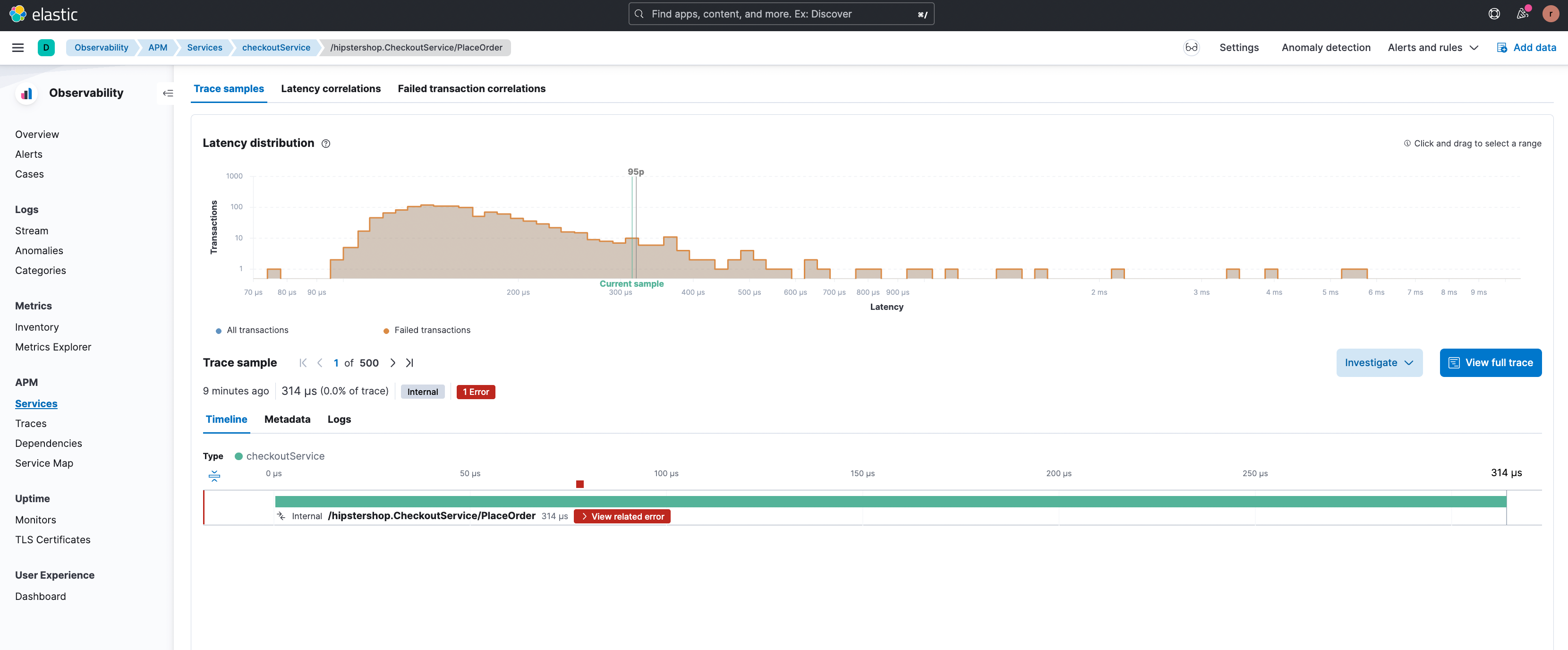
Die Option „View related error“ öffnet die relevante Fehlerdetailseite (unten dargestellt), wo die verschiedenen Fehlerarten hervorgehoben werden, die mit diesem Endpoint verknüpft sind. Außerdem wird die Stack-Trace für das jeweilige Fehlervorkommen gezeigt, der sich zusätzliche Debugging-Informationen entnehmen lassen.
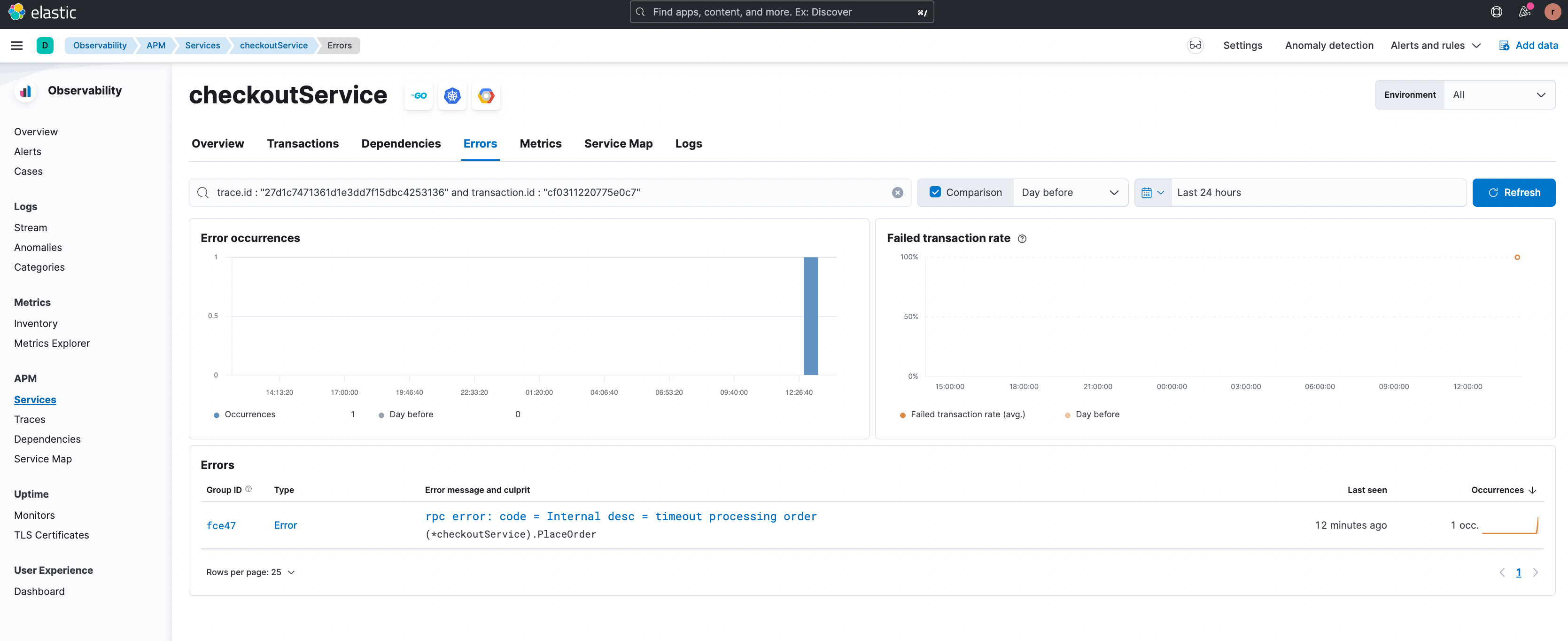
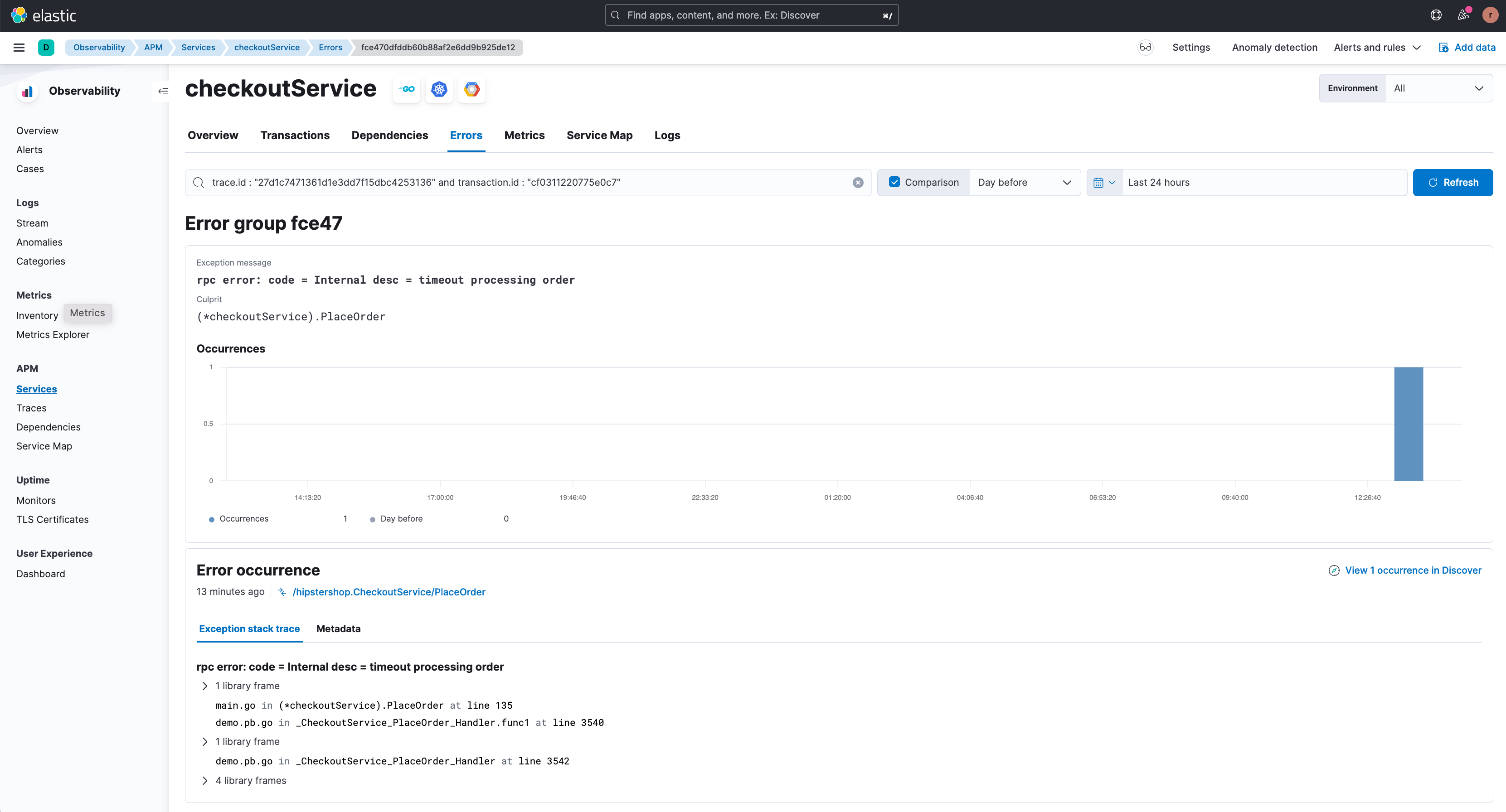
In den Beispielen oben ist zu sehen, dass die Funktion „APM-Korrelationen“ den Nutzer:innen die Arbeit abnimmt, die fehlerhafte(n) oder langsame(n) Transaktionsgruppe(n) einzugrenzen. Das Ergebnis ist eine deutliche Verkürzung der Zeit, die vergeht, bis Probleme erkannt und gelöst werden.
Eingaben und Daten, die für Korrelationen benötigt werden
„APM-Korrelationen“ kann bei Problemen, die nur einen Teilbereich der Gesamtmenge betreffen, die Ursachenanalyse deutlich beschleunigen. Je mehr Daten es gibt, um die Apps, Dienste, Transaktionen, Infrastruktur und Clients zu beschreiben, desto aussagekräftiger wird die Analyse und desto höher ist die Wahrscheinlichkeit, Attribute zu finden, die eine überzeugende Erklärung für suboptimale Transaktionen bieten. Die Korrelationen-Funktion nutzt alle in den Daten vorhandenen Felder und Labels.
Über den Workflow zum Hinzufügen von Integrationen auf der Seite „Overview“ können Sie Agent-Funktionen und/oder Dateningestionen für die verschiedenen Anwendungen, für die Infrastruktur und für die Abhängigkeiten in Ihrer Umgebung hinzufügen. Es sei darauf hingewiesen, dass es auch native Integrationen für verschiedene Technologien gibt, darunter für cloudnative Umgebungen wie das cloudbasierte Kubernetes und für Serverless-Technologien wie Lambda. Wenn Sie die verschiedenen Telemetriequellen identifiziert haben, lassen sich die eingehenden Daten mittels Logstash oder direkt über den APM-Agent weiter anreichern. Elastic bietet auch nahtlose Integration für und umfassende, native Unterstützung von OpenTelemetry-Daten (die wiederum auch die manuelle Instrumentierung unterstützen).
Clientseitige Informationen können über Real-User-Monitoring-Daten (RUM-Daten) herangezogen werden. Bei Nutzung des Elastic-eigenen RUM-Agents wird standardmäßig das verteilte Tracing aktiviert, und das Tracing für ursprungsübergreifende Anforderungen und die Verbreitung von Tracestate lässt sich mit der Konfigurationsoption distributedTracingOrigins ganz einfach konfigurieren. Die Kombination aus APM und RUM stellt ausführliche Client-Informationen bereit – von Angaben zu Browserversionen und Client-Betriebssystemen bis hin zum Nutzerkontext – und alle diese Daten werden automatisch in die Korrelationsermittlung einbezogen.
Nachdem diese Daten in Elastic angekommen sind, kann „APM-Korrelationen“ damit beginnen, überzeugende und klare Untersuchungsergebnisse zu produzieren. Da das in vielen Situationen maschinell schneller geht als manuell, können Ursacheninformationen schneller zur Verfügung gestellt werden.
Situationen, in denen „APM-Korrelationen“ die Ursachenermittlung deutlich beschleunigen kann
Fast schon per definitionem gibt es keine feste Gruppe komplexer Probleme, für die eine konkrete Funktion alle Antworten mit Gewissheit bereitstellen kann. Schließlich gelten viele APM-Probleme genau deshalb als komplex, weil deren Untersuchung viele Unbekannte beinhaltet. Gäbe es lediglich ein paar bekannte Probleme, wüssten wir, wonach wir suchen müssten, und das wären dann keine komplexen Probleme mehr!
Für viele komplexe Untersuchungen können APM-Korrelationen jedoch ein wichtiger Teil des Untersuchungsinstrumentariums werden, erlauben sie es doch, den Fokus schnell auf konkrete Bereiche des Deployments einzugrenzen und die Ursache zu ermitteln oder zu validieren. Dabei sollte vor Beginn der Untersuchung überlegt werden, ob das Problem das gesamte Deployment betrifft oder nur einzelne Unterbereiche. So können Sie sich beispielsweise fragen, ob die hohe Latenz alle Transaktionen betrifft oder nur einige wenige, während die anderen innerhalb des Erwartungshorizonts liegen. Wenn das Problem nicht das gesamte Deployment betrifft, sollten Sie darüber nachdenken, mithilfe von APM-Korrelationen zu prüfen, ob ein Teilsatz von Attributen helfen kann, die Sie interessierenden Transaktionen zu charakterisieren. Mit diesen Attributen erhalten Sie eine kleinere, besser verwaltbare Gruppe von Transaktionen, deren Traces Sie dann prüfen können, um Ursachen zu ermitteln, oder anhand derer Sie sich die Infrastrukturabhängigkeiten ansehen können, die zu Performance-Problemen bei Transaktionen beitragen.
Im Folgenden haben wir für Sie ein paar Beispiele für Situationen zusammengestellt, in denen APM-Korrelationen nach unseren Erfahrungen besonders effektiv sind:
Hardware-Performance-Probleme: Besonders in Fällen, in denen mit Lastausgleich gearbeitet wird und in denen für bestimmte Lasten bestimmte Hardware eingesetzt wird, kann es bei einem Rückgang der Hardware-Performance bei bestimmten Nutzergruppen oder bestimmten Teilen einer Anwendung zu höherer Latenz kommen. APM-Korrelationen können unter Zuhilfenahme von Labeln und Kennungen dabei helfen, die betreffenden Hardware-Instanzen schnell zu isolieren.
Verwendete Eingabedaten:
- Globale Label, die der APM-Agent in den verteilten Traces gesammelt hat
- Infrastrukturmetriken, erfasst durch Elastic Agent oder Metricbeat, um nach Nutzung der Funktion „APM-Korrelationen“ weiter Untersuchungen anstellen zu können
Probleme im Zusammenhang mit der Hyperscaler-Tenancy oder Multi-Cloud-Deployments: Die Nutzung von Hyperscalern machen Anwendungsbereitstellungen noch komplexer als sie eh schon sind. Multi-Cloud- und Hybrid-Cloud-Deployments werden immer beliebter. Bei der Suche nach und der Behebung von Fehlern, die nur einige Teile einer Anwendung betreffen, lässt sich mit Hyperscaler-Labels und ‑Tags (beispielsweise Cloud-Metadaten) herausfinden, welche Instanzen, Cloud-Anbieter, Regionen oder Verfügbarkeitszonen mit dem Problem verknüpft sind. Der Java-APM-Agent von Elastic kann anhand der Konfigurationsvariablen automatisch den verwendeten Cloud-Anbieter erkennen.
Verwendete Eingabedaten (vom APM-Agent automatisch erfasst):
- Cloud-Verfügbarkeitszone
- Cloud-Region
Regions- oder nutzergruppenspezifische Probleme: Mit APM-Korrelationen lassen sich Tags ermitteln, die spezifische Orte oder Nutzergruppen kennzeichnen, sodass Sie ganz konkrete Nutzersegmente isolieren und sich nur deren Transaktionen ansehen können. So unterstützt zum Beispiel der Java-APM-Agent von Elastic globale Labels, die von der Funktion genutzt werden, um zusätzlichen Kontext bereitzustellen und den Fokus auf einen Teilbereich der Gesamtdatenmenge einzugrenzen. Elastic-APM-Agents, wie der Java-APM-Agent, ermöglichen die Konfiguration globaler Label, mit deren Hilfe allen Ereignissen zusätzliche Metainformationen hinzugefügt werden können. Globale Label werden Transaktionen, Metriken und Fehlern hinzugefügt. Ähnlich auch die Java-APM-Agent-API: Mit ihr lassen sich Transaktionen manuell instrumentieren, um regions- oder nutzergruppenspezifische Informationen gewinnen zu können. Diese Label helfen dabei, sich auf neue Klassen/Methoden im Dienst zu beschränken, die die Ursachenanalyse, die Hypothesenprüfung usw. beschleunigen können.
Verwendete Eingabedaten:
- Cloud-Metadaten (vom APM-Agent automatisch gesammelt)
- Globale Label für das optionale Anreichern von Ereignisdaten mit Metainformationen
- Daten, die über die manuelle Instrumentierung hinzugefügt wurden
Probleme im Zusammenhang mit Canary-Rollouts oder anderen Teilbereitstellungen: Bei Enterprise-Anwendungs-Deployments, speziell bei Anwendungen, die als SaaS bereitgestellt werden, kommt es immer wieder einmal vor, dass mehrere Versionen der Software gleichzeitig laufen. Beispiele für solche gleichzeitigen Deployments mit mehreren Versionen sind Canary-Rollouts und A/B-Tests. Wenn sich eine bestimmte Version der Anwendung nicht erwartungsgemäß verhält, kann die Funktion „APM-Korrelationen“ dabei helfen, die fehlerhafte Version zu finden, das Problem einzugrenzen und so schneller die Ursache zu ermitteln. Die Dienstversion (Parameter „service_version“) kann per automatischer Erkennung oder über eine Umgebungsvariable, z. B. im Java-APM-Agent von Elastic, konfiguriert werden.
Verwendete Eingabedaten:
- Dienstversion, ermittelt durch automatische Erkennung oder einen APM-Agent
Clientseitige Probleme: Clientseitige Indikatoren, wie Angaben zur konkreten Browserversion oder zum Gerätetyp, helfen unmittelbar dabei, den Umfang der zu untersuchenden Daten und die Zahl der potenziellen Ursachen einzuschränken, und stellen wertvolle Ursacheninformationen für die weitere Problemanalyse, ‑lösung und ‑beseitigung bereit.
Verwendete Eingabedaten:
- Client-Daten, wie Browser- und Betriebssystemversion, Gerätedetails, Netzwerktyp usw., automatisch per Elastic-RUM-Agent ermittelt
Probleme bei externen Dienstanbietern: In Szenarien, in denen externe Anbieter, z. B. Authentifizierungsdienstanbieter, verwendet werden, können APM-Korrelationen dabei helfen, anbieterspezifische Probleme schnell zu identifizieren. Dies kann mit einem SDK (Elastic oder OTel) zum Hinzufügen individueller Label zur Identifizierung von Authentifizierungsanbietern erfolgen. Individuelle Label können auch in anderen ähnlichen Szenarien sinnvoll sein, in denen die automatische Instrumentierung allein nicht ausreicht, den für die Ursachenanalyse relevanten Kontext bereitzustellen.
Verwendete Eingabedaten:
- Individuelle Label, über Elastic- oder OTel-SDK hinzugefügt
- Globale Label
… und es gibt noch viele andere denkbare Situationen, aber Sie werden die Grundtendenz verstanden haben. Korrelationen funktionieren bei komplexen Problemen, die sich auf Teilbereiche Ihres Dienstes auswirken, während andere Bereiche problemlos zu laufen scheinen.
Auf der anderen Seite gibt es bestimmte Situationen, in denen die Funktion „APM-Korrelationen“ möglicherweise nicht das Mittel der Wahl ist. Dazu gehören das gesamte Deployment betreffende Probleme, die sich durch alle Dienste ziehen, statt nur in kleineren Teilbereichen oder Segmenten evident zu sein. In solchen Situationen können viele verschiedene Tags, Label oder Indikatoren alle hochgradig mit den suboptimalen Transaktionen korreliert sein, sodass sie für die weitere Untersuchung nicht viel bringen. Und schließlich gilt auch: Wenn die relevanten Daten nicht vorhanden sind oder es nicht ausreichend Deskriptoren und Label gibt, wird die Korrelation unter Umständen gar nicht erst erkannt. Informationen dazu, welche Eingaben und Daten korrelationsfördernd sind, finden Sie im vorherigen Abschnitt.
Dennoch erweist sich die Funktion „APM-Korrelationen“ für viele APM-Untersuchungen als leistungsfähiges Instrument, das dabei helfen kann, die Zahl der zu untersuchenden Objekte schnell auf bestimmte Transaktionsgruppen einzugrenzen. In vielen Fällen führen die so korrelierten Transaktionen in kürzester Zeit zur Ursache, was die Untersuchungszeit deutlich reduziert.
Happy Troubleshooting!
Weitere Ressourcen und Informationen
Die Funktion „APM-Korrelationen“ ist seit Version 7.15 allgemein verfügbar. Wenn Sie die Release Notes für diese Funktion lesen möchten, klicken Sie hier.
Das Nutzerhandbuch und die Dokumentation für „APM-Korrelationen“ finden Sie hier.
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken