What is continuous profiling?
持续性能分析的定义
持续性能分析是指持续不断地从实时生产环境中运行的应用程序收集性能数据,旨在优化这些应用程序的性能并提升资源利用效率的过程。
与传统方法中临时或按需采样数据不同,持续性能分析能够实时捕获各项指标,从而提供更准确、更及时的应用程序性能和行为视图。它还特别关注生产环境,跟踪资源利用情况,并提供代码级别的深入见解。这一功能不仅有助于短期问题排查,还能够以极小的开销支持长期性能分析。
持续性能分析相较于传统的性能分析实践,在多个方面都取得了显著进步。这些进步包括从临时分析向连续数据收集的转变,通过 eBPF 创新大幅降低性能影响,以及与可观测性工具的集成。现代持续性能分析工具还融入了使用 AI 和机器学习的自动分析功能,可支持多种编程语言,并且专为与分布式系统和云原生系统良好协作而设计。
持续性能分析的重要性
性能瓶颈的识别与解决
持续性能分析可以实时检测和解决性能瓶颈。通过不断收集 CPU、内存、磁盘 I/O 等资源利用率数据,您可以详细了解系统的运行情况。这样,开发人员就能精确地定位代码中效率低下的部分,从而积极主动地解决性能问题,提升应用程序的整体性能。
开发团队的优势
持续性能分析还将会显著提高代码质量,因为开发人员能够更容易识别和解决在开发或测试环境中可能不会出现的性能问题。这会直接促使生产代码更稳健和高效。此外,通过实时数据分析,持续性能分析还加速了故障排查过程,使得开发团队能够更迅速地定位间歇性问题,从而减少了故障排查时间,提高了整体工作效率。同时,持续性能分析还可为 SRE 团队提供关于应用程序性能和行为的见解,有助于他们更好地进行可扩展性和可靠性规划,确保应用程序在高负载下仍能保持优异的性能表现。
业务优势
通过运用持续性能分析来优化资源使用,企业能够有效降低云资源消耗及其相关成本,从而实现成本节约。此外,这也有助于缩减数据中心的碳足迹,促进公司在科技行业中提升整体环境责任感。
同时,提升应用程序的性能还能间接为用户带来更佳的使用体验,进而增强客户满意度,并有可能提升客户忠诚度。
持续性能分析的工作原理
第 1 步:数据收集
持续性能分析的第一步是收集所需数据。这一过程通常使用低开销的采样技术来收集内存分配、CPU 使用率和 I/O 操作等指标。为了实现这一过程,通过会集成 eBPF、JProfiler 和 Elastic 的 Universal Profiling 等工具。
这些工具可通过代理、库或内核模块等方式集成到系统中,具体方法取决于所选技术和所需的访问权限级别。此外,不同的分析方法在影响和资源需求方面也存在差异:
- 轻量级持续性能分析器:这类分析器具有极低的开销,适合在生产环境中持续使用。
- 采样性能分析器:这类分析器会定期进行数据收集,其开销较低或适中。
- 代码插桩性能分析器:这类分析器能收集更详细的数据,但开销相对较高。通常用于开发、测试或预生产环境中。
- 跟踪工具:这类工具能够进行全面的数据收集,但开销较大通常用于特定的故障排查会话中。
第 2 步:分析
数据收集完成后,接下来是分析阶段,旨在识别性能瓶颈、资源使用模式以及潜在的优化空间。这一分析过程通常包括:跨时间维度汇总数据,将数据与应用程序事件进行交叉比对,以及运用统计方法来检测异常和发现趋势。这一阶段的目标是将数据转化为具有实际指导意义的见解。
此外,持续性能分析还可与应用性能监测 (APM) 数据(如痕迹)相关联,以便准确了解在特定痕迹记录发生时运行了哪些代码,从而通过增强上下文信息来加速确定根本原因的过程。
在这一阶段,经常会采用先进的技术手段来改进分析,包括使用 Machine Learning 和 AI 工具。这些工具在自动分类问题、预测未来性能以及提出优化建议方面尤其出色。
第 3 步:可视化
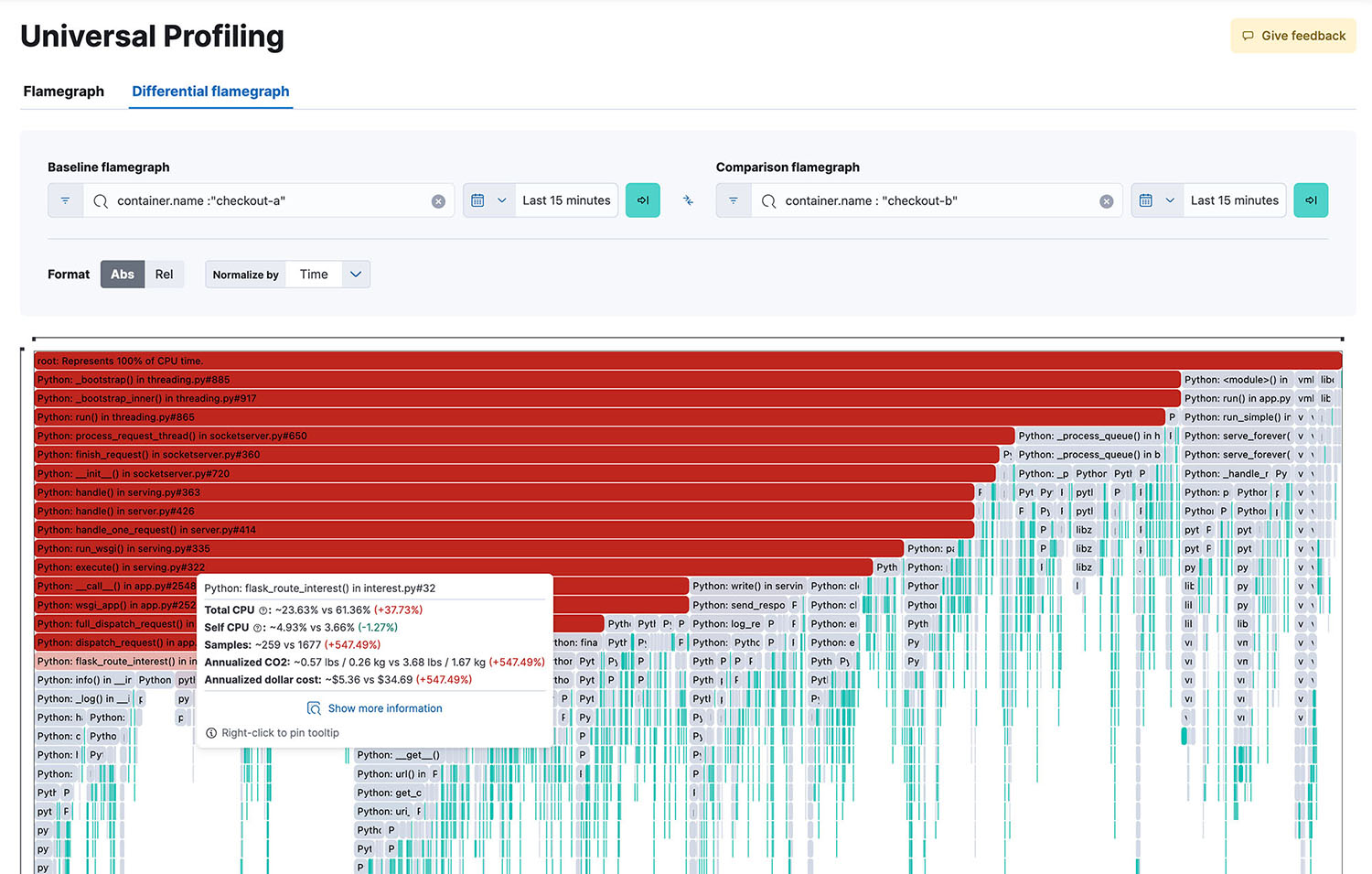
在可视化步骤中,复杂的性能数据会被转化为直观易懂的可视化图表。这一步骤旨在协助开发人员和运维团队迅速识别性能瓶颈、使用模式以及需要优化的领域。常用的技术包括火焰图和冰柱图。火焰图能够轻松凸显出代码中的热点路径,而冰柱图则展示了代码不同部分所花费的相对时间。
这些可视化步骤通常是交互式的,允许用户进行缩放、数据过滤,并深入探究特定的问题区域或功能。大多数性能分析工具都提供了仪表板,可用于将多种可视化数据和指标汇总到一个界面中,方便进行综合分析。
持续性能分析实践
用例
- 电子商务平台优化:使用持续性能分析来识别影响结账流程的缓慢数据库查询,并通过优化资源密集型功能来缩短页面加载时间。
- 微服务架构性能:精确识别服务间通信的具体瓶颈,并优化所有分布式系统的资源分配。云成本优化:识别导致内存和/或 CPU 使用率过高的低效代码,并通过优化资源使用降低云托管成本。
- 实时数据处理系统:检测并解决数据处理瓶颈,优化流处理管道以减少延迟。
- 事件管理和问题解决:快速确定导致性能问题的根本原因,从而缩短平均解决时间 (MTTR)。
最佳实践
- 在开发过程的早期阶段集成持续性能分析功能,并采用低开销的采样技术。
- 自动执行数据收集、分析和告警流程,以确保一致性和快速响应。
- 与现有的 APM 和可观测性工具关联,以获得全面的见解。
- 实施 CI/CD 管道集成,以便对单元测试运行进行持续性能分析。
- 为所有正在进行的优化工作建立定期审查程序和反馈循环。
- 保持所有性能分析工具更新并定期进行维护。
- 培训团队成员,让他们能够解读并有效分析性能分析数据。
持续性能分析的挑战和局限性
性能开销
即使使用了低开销的采样技术,每种持续性能分析也会对被监测的系统造成一定的性能负担。这种负担可能会影响应用程序的性能,尤其是在资源受限的环境中。为了最大限度地减少性能开销,您可以采取以下三个措施:
- 在可能的情况下,使用开销最小的基于 eBPF 的分析器
- 实施自适应分析,在高负载期间降低分析频率
- 只对关键组件进行分析,而非对整个系统进行分析
数据隐私问题
与任何涉及数据收集的流程一样,都存在所收集数据中包含敏感信息(特别是用户数据)的风险。为了应对这些问题,需要:
- 对所有性能分析数据实施严格的访问控制和加密措施
- 在存储、共享或显示敏感数据之前,先进行匿名化或混淆处理
- 严格遵守任何相关的数据保护法规
数据存储和管理
持续性能分析会生成大量数据,这些数据需要被高效地存储和管理。这可以通过以下策略来实现:
- 实施数据保留政策,以限制数据的存储时间
- 压缩数据
- 利用云存储,提高可扩展性
未来趋势:OpenTelemetry 的支持
技术始终在不断更迭和发展,这有助于提升持续性能分析的能力,但也会带来意想不到的新挑战。虽然我们无法提前预知所有变化,但重要的是要保持对新工具或新技术的了解,以便我们能够评估它们是否适合我们的业务需求。
例如,OpenTelemetry 最近宣布其目前可以支持性能分析,并正在基于开放标准开发性能分析数据模型。这样的行业变革对于在可观测性平台中采用持续性能分析技术,同时最大程度地减少供应商锁定,将产生深远的影响。
使用 Elastic 进行持续性能分析
Elastic 推出了 Universal Profiling,这项服务可为公司提供贯穿整个开发管道的全系统持续性能分析。它利用 eBPF 分析技术仅捕获必要的数据,并与 OpenTelemetry 集成,从而增强可观测性并揭示更深入的见解。借助 Elastic,团队能够实现:
- 全系统可见性:Elastic Universal Profiling 可捕获并分析来自内核、应用程序代码和第三方库的数据。
- 顺畅部署:该代理的部署无需进行侵入性操作或修改应用程序源代码,因此可以迅速开始接收性能分析数据。
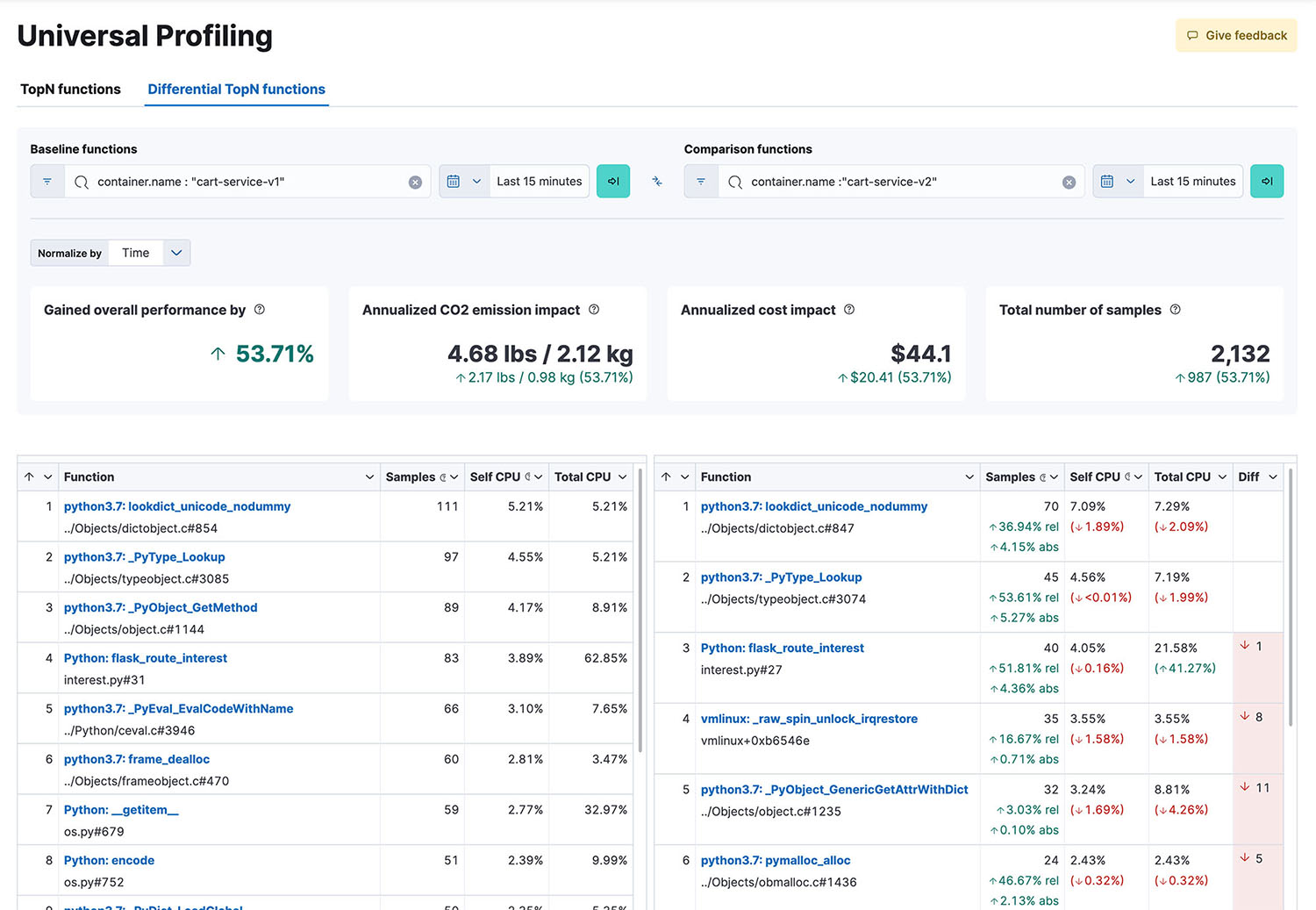
- 数据可视化:通过 Kibana 中的堆栈跟踪、火焰图和函数视图,可以检查性能分析数据,从而轻松过滤和比较随时间变化的数据,以帮助识别性能改进或检测性能下降。