7.7 版本中的新改进:显著降低 Elasticsearch 堆内存使用量
由于 Elasticsearch 用户不断突破在 Elasticsearch 节点上存储的数据量的极限,所以他们有时会在耗尽磁盘空间之前就将堆内存用完了。对于这些用户来说,这个问题难免让他们沮丧,因为每个节点拟合尽可能多的数据通常是降低成本的重要手段。
但为什么 Elasticsearch 需要堆内存来存储数据呢?为什么它不能只用磁盘空间呢?这其中有几个原因,但最主要的一个是,Lucene 需要在内存中存储一些信息,以便知道在磁盘的什么位置进行查找。例如,Lucene 的倒排索引由术语字典和术语索引组成,术语字典将术语按排序顺序归入磁盘上的区块,术语索引用于快速查找术语字典。该术语索引将术语前缀与磁盘上区块(包含具有该前缀的术语)起始位置的偏移量建立映射。术语字典在磁盘上,但是术语索引直到最近还在堆上。
索引需要多少内存?通常情况下,每 GB 索引需要几 MB 内存。这并不算多,但随着用户在节点上安装 TB 数越来越大的磁盘,索引很快就需要 10-20 GB 的堆内存来存储这些 TB 量级的索引。鉴于 Elastic 的建议,不要超过 30 GB,不然就没有给聚合等其他堆内存消耗者留下太多空间,而且,如果 JVM 没有为集群管理操作留出足够的空间,就会导致稳定性问题。
我们来看一些实实在在的数字。Elastic 在多个数据集上运行了夜间基准测试,并跟踪了不同时间的各种指标,特别是段的内存使用情况。Geonames 数据集很有趣,它清晰地显示了在 Elasticsearch 7.x 上发生的各种变化的影响:
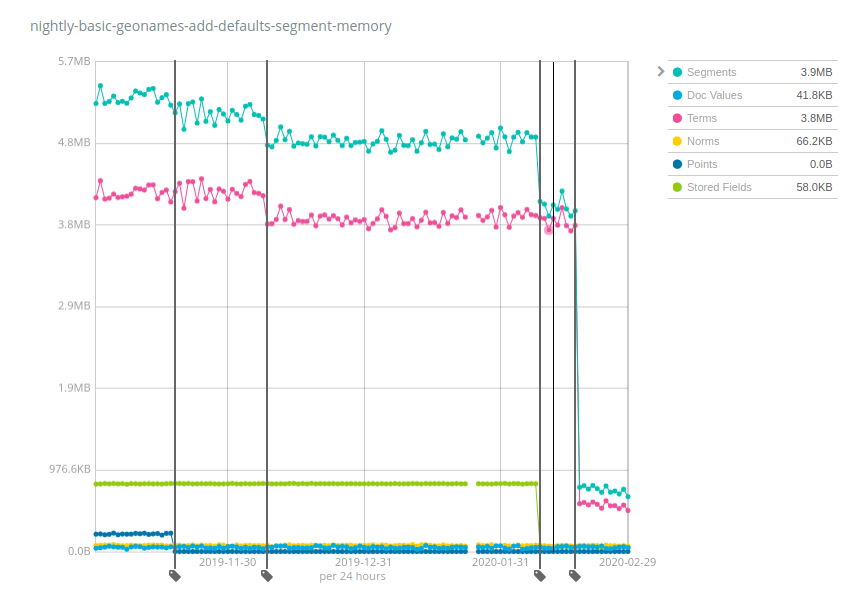
6 个月前,此索引在磁盘上占用大约 3 GB 空间,需要大约 5.2 MB 的内存,堆:存储比约为 1:600。按此比例,如果每个节点有 10 TB 数据,那么就需要 10 TB / 600 = 17 GB 的堆量,这还是仅够保持存储类似 geonames 数据的索引处于打开状态。但正如您所看到的,随着时间的推移,情况正在向好的方向发展:点(深蓝色)开始需要较少的内存,接着是术语(粉色),之后是存储字段(绿色),最后还是术语占比很大。堆:存储比现在约为 1:4000,与 6.x 和早期 7.x 版本相比,几乎提升了 7 倍。现在只需要 2.5 GB 堆内存就可以使 10 TB 索引保持打开状态。
这些数字在不同数据集间会有很大差异,不过让人欣慰的是,Geonames 是堆使用量减少程度最低的数据集之一:虽然在 Geonames 上,堆使用量减少了约 7 倍,但在 NYC taxis 和 HTTP logs 数据集上,减少量超过了 100 倍。同样,这一变化将有助于降低成本,因为在每个节点上存储的数据比以前版本的 Elasticsearch 要多得多。
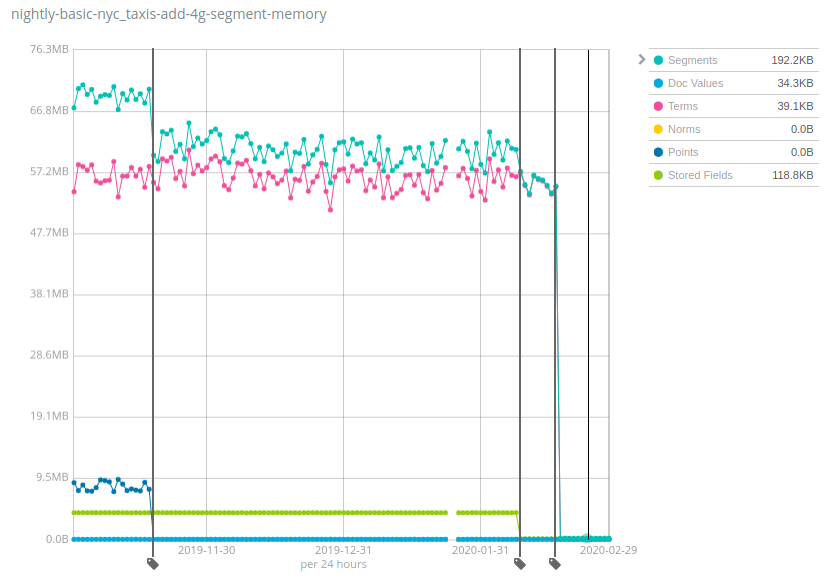
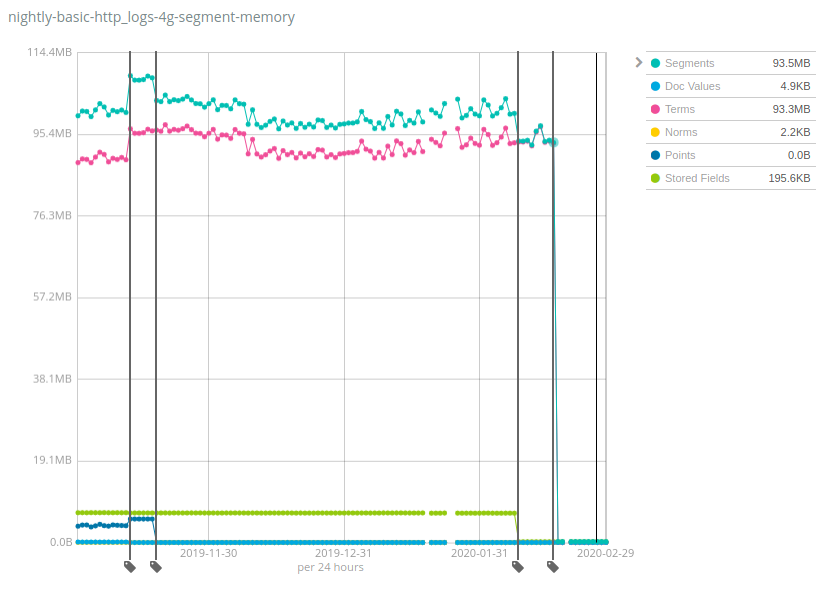
它是如何工作的,有什么缺陷?随着时间的推移,同样的方法已经应用到 Lucene 索引的多个组件中:将数据结构从 JVM 堆移动到磁盘,并依赖文件系统缓存(通常称为页面缓存或 OS 缓存)将热数据保存在内存中。这可能会被误以为这些内存仍然在使用,只不过是分配到了其他地方,但实际情况是,根据您的用例,很大一部分内存根本没有使用。例如,Terms 的最后一次删除操作是因为移动了磁盘上 _id 字段的术语索引,这只在使用 GET API 或使用显式 ID 索引文档时有用。那些绝大多数将日志和指标索引到 Elasticsearch 中的用户从来都不会执行此类操作,所以这只会让他们的资源出现净增长。
使用 7.7 减少 Elasticsearch 堆!
我们对 Elasticsearch 7.7 中的这些改进感到非常兴奋,也希望大家也有同感。请密切关注即将发布的公告,欢迎您亲自测试一下。在您现有的部署中尝试一下,或者在 Elastic Cloud 上轻松免费试用 Elasticsearch Service(始终有最新版本的 Elasticsearch)。我们期待听到您的反馈,请前往讨论区告知我们您的想法。