了解 Elasticsearch 如何使用 PyTorch 进行现代自然语言处理


 Share on Twitter
Share on Twitter在 Twitter 上分享

 Share on LinkedIn
Share on LinkedIn在 LinkedIn 上分享

 Share on Facebook
Share on Facebook在 Facebook 上分享

 Share by Email
Share by Email通过邮件分享

 Print this page
Print this page打印
随着 8.0 版的发布,Elastic 很高兴能够将 PyTorch Machine Learning 模型上传到 Elasticsearch,从而在 Elastic Stack 中实现现代自然语言处理 (NLP)。现在,Elasticsearch 用户能够集成用于构建 NLP 模型的最热门格式之一,并将这些模型作为 NLP 数据管道的一部分通过我们的推理处理器整合到 Elasticsearch 中。支持添加 PyTorch 模型且新增 ANN 搜索 API,这为 Elastic Enterprise Search 带来一个全新矢量(此处有双关语意)。
什么是 NLP?
NLP 是指我们可以使用软件来处理和理解口语或书面文本(即自然语言)的方式。 2018 年,Google 开放了一种用于 NLP 预训练的新技术的源代码,这种技术称为基于 Transformer 的双向编码器表示 (BERT)。 BERT 采用迁移学习的方式,对互联网上的大规模数据集(例如所有维基网页和所有电子书)进行训练,无需任何人工参与。
迁移学习允许对 BERT 模型进行预训练,以了解通用语言。模型只要被预先训练过一次,就可以重复使用,还可以针对更加具体的任务进行微调,以便了解语言的使用方式。
为支持类似于 BERT 的模型(也就是使用与 BERT 相同的分词器的模型),Elasticsearch 会先通过 PyTorch 模型支持功能来支持大多数最常见的 NLP 任务。PyTorch 是最受欢迎的现代 Machine Learning 库之一,拥有大量活跃用户。这个库支持深度神经网络,如 BERT 使用的 Transformer 架构。
以下是一些 NLP 任务示例:
- 情感分析:二分类,用于识别肯定和否定陈述
- 命名实体识别 (NER): 基于非结构化文本构建结构,旨在提取名称、地点或组织等详细信息
- 文本分类:零样本分类允许根据所选类别对文本进行分类,且无需预先训练。
- 文本嵌入:用于 k 最近邻 (kNN) 搜索

NLP 在 Elasticsearch 中的使用
在将 NLP 模型集成到 Elastic Platform 时,我们的初衷是在上传和管理模型方面为用户提供出色的体验。 通过使用 Eland 客户端上传 PyTorch 模型,并将 Kibana 的 Machine Learning 模型管理用户界面用于管理 Elasticsearch 集群上的模型,用户可以试用不同模型,以便切实了解这些模型处理数据的效果如何。 我们还希望跨集群的多个可用节点实现扩展,并提供可观的推理吞吐量。
为使这一切成为可能,我们需要借助一个 Machine Learning 库来执行推理。要在 Elasticsearch 中添加对 PyTorch 的支持,需要使用原生库 libtorch 来支持 PyTorch,且此操作仅支持已经导出或保存为 TorchScript 表示形式的 PyTorch 模型。这是 libtorch 所需模型的表示形式,且无需 Elasticsearch 运行 Python 解释器。
通过在 PyTorch 模型中集成用于构建 NLP 模型的最热门格式之一,Elasticsearch 可以提供适用于各种 NLP 任务和用例的平台。 由于有许多优秀的库可用于训练 NLP 模型,因此我们现在将其留给其他工具搞定。 无论您是否使用 PyTorch NLP、Hugging Face Transformer、Facebook 的 fairseq 等库来训练模型,您都可以将模型导入 Elasticsearch 并对这些模型执行推理。Elasticsearch 推理最初只在采集时进行,将来还可以扩展以便在查询时引入推理。
到目前为止,已经有多种方法可以通过调用 API、插件和其他选项来集成 NLP 模型,以便将数据流式传入和传出 Elasticsearch。但在 Elasticsearch 数据管道中集成 NLP 模型有以下优点:
- 基于 NLP 模型构建更好的基础架构
- 扩展 NLP 模型推理范围
- 确保数据安全和隐私
可以在 Kibana 集中管理 NLP 模型,跨多个 Machine Learning 节点分发查询来优化负载平衡
对 PyTorch 模型的推理调用可以分布在集群周围,并允许用户在未来根据负载进行扩展。不移动数据并优化云虚拟机以进行基于 CPU 的推理,从而提高性能。通过在 Elasticsearch 中集成 NLP 模型,我们可以将数据保存在一个整体集中管理、安全的网络中,同时确保数据隐私与合规性。通过将 NLP 模型集成到 Elasticsearch 中,公用基础架构、查询性能和数据隐私都可以得到增强。
实施 PyTorch NLP 模型的工作流
使用 PyTorch 实施 NLP 模型的步骤简单直接。我们需要做的第一步是将模型上传到 Elasticsearch。执行此操作的一种方法是使用可以从任一 Elasticsearch 客户端使用的 REST API,但我们想要添加更简单的工具来帮助完成此过程。 在 Eland 客户端(这是我们用于 Elastic Stack 的 Python 数据科学库)中,我们会公布一些非常简单的方法和脚本,以便您从本地磁盘上传模型,或者从 Hugging Face 模型中心拉取模型,后者是最流行的训练模型共享方式之一。无论使用哪种方法,我们都提供有工具来帮助将 PyTorch 模型转换为其 TorchScript 表示形式,并最终将模型上传到集群中。
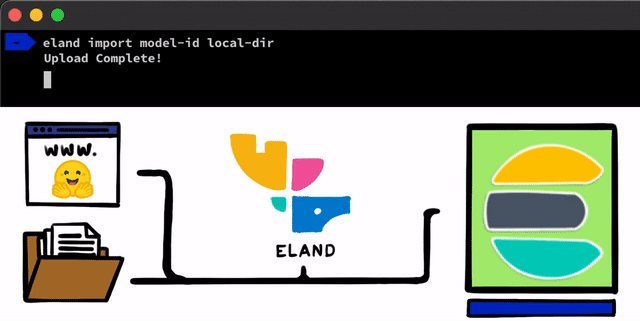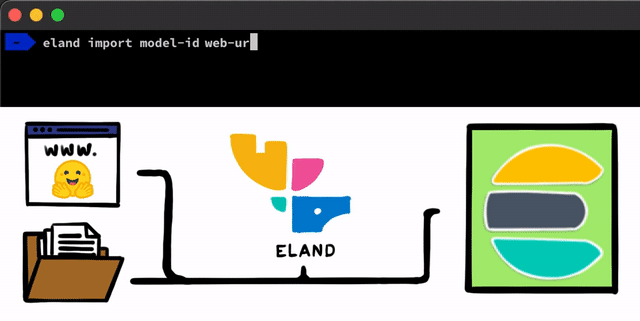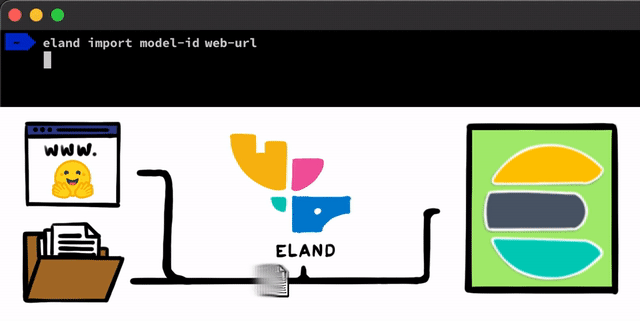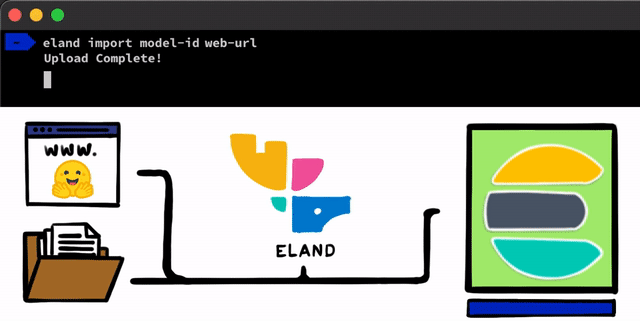
在将 PyTorch 模型上传到集群之后,您就可以将这些模型分配给特定的 Machine Learning 节点。这个过程会将模型加载到内存中并启动 libtorch 原生进程,从而做好推理准备。
最后,一旦模型分配完成,我们就可以进行推理了。采集时会出现一个用于推理的处理器,您可以在其中设置任何类型的采集数据处理管道,以便在推理前后对文档进行预处理或后处理。例如,在执行情感分析任务时,我们可以将文档字段的文字作为输入,返回根据该输入预测的正面或负面类别标签,并将该预测添加到文档中的输出字段。然后,生成的新文档可以由其他采集处理器进一步处理,或按原样建立索引。
未来发展
我们会在未来的博客更新和网络研讨会中带来更多具体模型和 NLP 任务的示例,敬请期待。如果您想在 Elasticsearch 中试用模型,则可以立即开始,并通过我们的 Machine Learning 讨论论坛或 社区 Slack 告诉我们您的体验如何。对于生产用例,您需要白金级或企业级许可才能在 Elasticsearch 中上传 NLP 模型并使用推理处理器,但您可以通过免费试用许可立即试用。或者,您也可以构建一个 Elastic Cloud 集群,然后使用我们的 Eland 客户端将模型上传到新集群以开始体验。 您现在就可以开始免费试用 14 天 Elastic Cloud。
还有一件事...如果您有兴趣了解有关 NLP 模型的更多信息以及如何将其集成到 Elasticsearch 中,可以参加我们的网络研讨会 NLP 模型和矢量搜索介绍。
其他相关链接:
- 与 Josh Devins 探讨 ElasticON
- 与 Ben Trent 和 Jay Miller 讨论 Elastic 社区 NLP
- Julie Tibshirani 发布的 ANN 搜索博客
- 8.0 版 NLP 文档
分享
- Share on Twitter
在 Twitter 上分享
- Share on LinkedIn
在 LinkedIn 上分享
- Share on Facebook
在 Facebook 上分享
- Share by Email
通过邮件分享
- Print this page
打印