Elastic Common Schema 简介
Elastic Common Schema (ECS) 简介:ECS 是一种新规格,可让用户以一致、可定制的方式整理 Elasticsearch 中数据的结构,协助分析来自不同来源的数据。通过 ECS,用户可以更加广泛地应用诸如仪表板和 Machine Learning 作业等分析内容,可以更加具有针对性地创建搜索,还能更轻松地记住字段名称。
为何使用通用架构 (Common Schema)?
无论要执行交互式分析(例如搜索、向下钻取和透视,以及可视化),还是要执行自动分析(例如警报、Machine Learning 驱动的异常检测),您都需要能够对数据进行统一研究。但是,除非您的数据全部来自同一个数据源,否则由于下列原因,您的数据在格式方面将会存在不一致之处:
- 不同的数据类型(例如日志、指标、APM、数据流、上下文数据)
- 采用各种各样供应商标准的各异环境
- 相似但不完全相同的数据源(例如端点数据的多个来源,譬如 Auditbeat、Cylance 和 Tanium)
假设我们要在来自多个来源的数据中查找一名特定用户。虽然仅搜索这一个字段,但您需要考虑多个字段名称,例如 user、username、nginx.access.user_name 和 login。如需对这些数据进行向下钻取和透视分析,我们会面临一个更加巨大的难题。现在假设我们正在开发分析内容(例如可视化、警报或 Machine Learning 作业),每新增一个数据源都会加大复杂程度或产生重复数据。
Elastic Common Schema 是什么?
ECS 是一种开源规格,可以针对要采集到 Elasticsearch 中的数据定义一个通用的文档字段集。ECS 设计用于支持统一数据建模,让您通过交互式和自动化技术集中分析来自多个数据源的数据。
ECS 采用专门构建的分类学,具有很好的可预测性,同时还包括可适应定制用例的包罗万象的规格,具有很好的通用性。ECS 的分类学会将数据元素划分为以下三个级别的字段:
| 级别 | 描述 | 推荐使用场景 |
| ECS 核心字段 | 已完全定义的字段集名称,位于已定义的 ECS 顶级对象集之下 | 这些是大部分用例中的常见字段,所以应该从这里开始着手 |
| ECS 延展字段 | 已部分定义的字段集名称,位于同一个 ECS 顶级对象集之下 | 延展字段可能适用于较小范围的用例,或者可根据用例更加开放地进行诠释 |
| 定制字段 | 未定义亦未命名的字段集,位于用户提供的非 ECS 顶级对象集之下,不得与 ECS 字段或对象冲突 | 如果某字段在 ECS 中没有对应的字段,您可以将其添加到这里;您也可以在这里保存一份原始事件字段的副本,例如将您的数据迁移至 ECS 时,便可如此做 |
Elastic Common Schema 的实际应用
示例 1:解析
让我们使用 ECS 对下列 Apache 日志进行解析:
10.42.42.42 - - [07/Dec/2018:11:05:07 +0100] "GET /blog HTTP/1.1" 200 2571 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36"
如将此消息映射到 ECS,日志字段将会按照下列方式进行整理:
| 字段名称 | 值 | 备注 |
| @timestamp | 2018-12-07T11:05:07.000Z | |
| ecs.version | 1.0.0 | |
| event.dataset | apache.access | |
| event.original | 10.42.42.42 - - [07/Dec ... | 未修改的完整日志,供审计用 |
| http.request.method | get | |
| http.response.body.bytes | 2571 | |
| http.response.status_code | 200 | |
| http.version | 1.1 | |
| host.hostname | webserver-blog-prod | |
| message | "GET /blog HTTP/1.1" 200 2571 | 事件中重要信息的文本表达,用于在日志查看器上简要显示 |
| service.name | Company blog | 您为此服务定制的名称 |
| service.type | apache | |
| source.geo.* | 地理位置字段 | |
| source.ip | 10.42.42.42 | |
| url.original | /blog | |
| user.name | - | |
| user_agent.* | 描述用户代理的字段 |
如上所示,原始日志已保存在 ECS 的 event.original 字段中,以支持审计用例。还有一点需要注意,为简单起见,我们在这个例子中省去了有关监测代理的详细信息(位于 agent.* 下面),也省去了有关主机的一些详细信息(在 host.* 下面),以及其他几个字段。如需查看更加完整的表达,请参阅这个 JSON 格式的示例事件。
示例 2:搜索
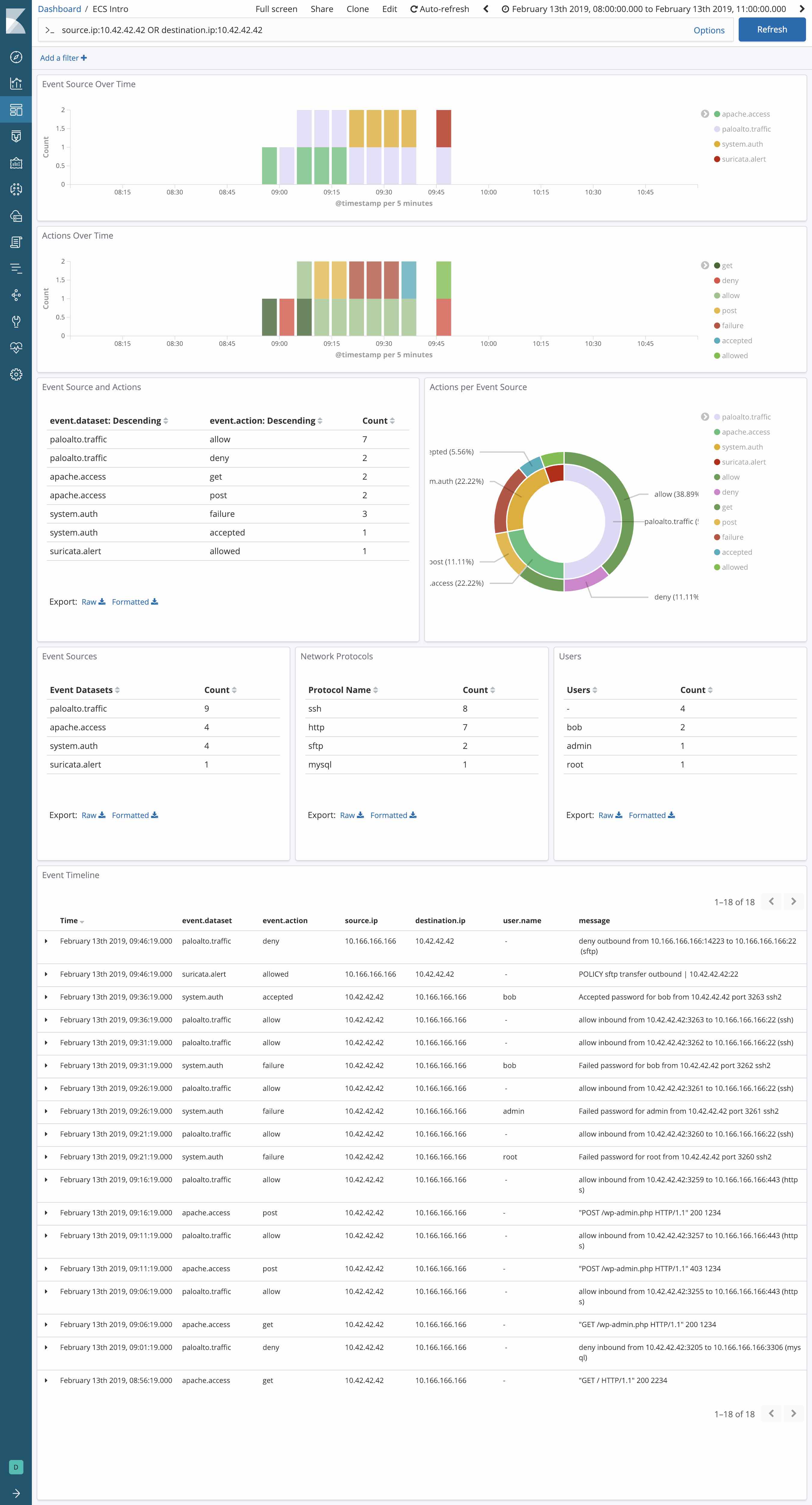
假设要在完整网络堆栈中调查某个具体 IP 的活动,这些堆栈分别是:Palo Alto Networks 防火墙、HAProxy(由 Logstash 处理)、Apache(使用 Beats 模块)、Elastic APM,此外还有 Suricata IDS(定制型,采用 Suricata 的 EVE JSON 格式)。
在使用 ECS 之前,您可能要通过类似下面的代码搜索此 IP:
src:10.42.42.42 OR client_ip:10.42.42.42 OR apache2.access.remote_ip:10.42.42.42 OR context.user.ip:10.42.42.42 OR src_ip:10.42.42.42
但是如果您已将所有来源均映射到 ECS,查询表达式则要简单得多:
source.ip:10.42.42.42
示例 3:可视化
通过查看如何将 ECS 应用于来自多个不同数据源的统一标准化数据,我们可以更加轻松地为您揭示 ECS 的强大功能。可能您正在使用多个网络数据源来监测网络堆栈中的威胁:在外围使用 Palo Alto 新一代防火墙,同时使用 Suricata IDS 来生成事件和警报。您如何从每个消息中提取 source.ip 和 network.direction 字段,从而支持在 Kibana 中实现集中可视化以及不区分供应商的向下钻取和透视呢?当然喽,使用 ECS,您可以比之前更加轻松地执行集中监测。
Elastic Common Schema 的优势
通过实施 ECS,用户可以将 Elastic Stack 中可用的所有分析模式整合在一起,包括搜索、向下钻取和透视、数据可视化、基于 Machine Learning 的异常监测,以及警报。完全采用之后,用户可以利用非结构化和结构化查询参数的强大功能进行搜索。通过 ECS,您能够更加轻松地自动将来自不同数据源的数据进行关联,无论是来自同一供应商但不同设备的数据,还是完全不同的数据源类型,ECS 均能胜任。
ECS 同时还可以减少您的团队开发分析内容所用的时间。您无需在贵公司每次添加新数据源时便要创建新搜索和仪表板,相反,可以继续利用已有搜索和仪表板。通过采用 ECS,您的环境还可以无比轻松地直接采用来自使用 ECS 的其他方(无论是Elastic、合作伙伴,还是开源项目)的分析内容。
进行交互式分析时,如果使用 ECS,由于只有一个集合,而不是每个数据源都有一个不同的集合,所以您能够更加轻松地记住常用字段的名称。如果忘记了字段名称,通过 ECS 您还可以更加轻松地推理出正确的字段名,这是因为此规格遵照一套简单的标准命名规格(仅有少数几种例外情况)。
暂时还不想采用 ECS?完全没问题。只要有需要,您可以随时采用;如您无此需求,我们也不强制要求使用。
Elastic Common Schema 入门
ECS 已在公开 GitHub 存储库中推出。此规格的现行版本是 Beta2,预计不久即会发布正式版本。ECS 是采用 Apache 2.0 开源许可证发布的,可以支持更广泛的 Elastic 社区普遍采用。
听起来已经实现自动化,有点不可思议,是不是?好吧,其实和其他任何架构一样,实施 ECS 并不是一项简单的工作。但是如果您已经配置了 Elasticsearch 索引模板,并且使用 Logstash 或者 Elasticsearch 采集节点编写了几个转换函数,那么您基本可以知道需要如何完成这一过程。Elastic Beats 模块的未来版本会默认生成 ECS 格式的事件,从而简化迁移过程中的这一部分工作。我们新推出了适用于 Auditbeat 的系统模块,这是首个此类模块,预计未来会推出更多。
如需了解 ECS 的详细信息,请观看我们的 Elastic Common Schema (ECS) 网络研讨会。在之后的博文中,我们将会讲解如何将您的数据映射至 ECS(包括此架构中尚未定义的字段),也会讲解迁移至 ECS 的策略。