如何部署自然语言处理 (NLP):命名实体识别 (NER) 示例


 Share on Twitter
Share on Twitter在 Twitter 上分享

 Share on LinkedIn
Share on LinkedIn在 LinkedIn 上分享

 Share on Facebook
Share on Facebook在 Facebook 上分享

 Share by Email
Share by Email通过邮件分享

 Print this page
Print this page打印
作为自然语言处理 (NLP) 系列博文的一部分,本篇博文将采用示例讲解的方式,介绍使用一个命名实体识别 (NER) NLP 模型来定位和提取非结构化文本字段中预定义类别的实体。我们将通过一个公开可用的模型向您展示如何完成以下几种操作:部署模型到 Elasticsearch 中,利用 new _infer API 查找文本中的命名实体,以及在 Ingest 管道中使用 NER 模型,在文档被采集到 Elasticsearch 中时提取实体。
在使用自然语言从全文本字段中提取人名、地名和组织机构名等实体的操作中,NER 模型可谓大有作为。
在本示例中,我们将以小说《悲惨世界》中的选段为运行对象,然后应用 NER 模型并使用该模型提取文本中的人物和地点,最后以可视化的方式展现两者之间的关系。
部署 NER 模型到 Elasticsearch 中
首先,我们需要选择一个 NER 模型,它可以从文本字段中提取人物名字和地点名称。幸运的是,我们可以从 Hugging Face 提供的几个 NER 模型中进行选择,然后在浏览 Elastic 文档的过程中,我们发现了 Elastic 中有仅包含小写的 NER 模型,可以用来试试看。
现在,我们选好了要应用的 NER 模型,可以开始使用 Eland 安装该模型了。在本示例中,我们将通过 Docker 镜像运行 Eland 命令,但是必须先克隆 Eland GitHub 存储库以构建 Docker 镜像,并在客户端系统上创建 Eland 的 Docker 镜像,如下所示:
git clone [email protected]:elastic/eland.git
cd eland
docker build -t elastic/eland .
此刻,Eland 的 Docker 客户端已经准备就绪,我们可以通过下方所示的命令在新的 Docker 镜像中执行 eland_import_hub_model 命令来安装 NER 模型:
docker run -it --rm elastic/eland \
eland_import_hub_model \
--url $ELASTICSEARCH_URL \
--hub-model-id elastic/distilbert-base-uncased-finetuned-conll03-english \
--task-type ner \
--start上方所示命令中的 ELASTICSEACH_URL 需要替换为您的 Elasticsearch 集群的 URL。为了进行身份验证,上述 URL 中需要包含管理员的用户名和密码,格式如下:https://username:password@host:port。
由于我们在 Eland 导入命令的最后一行选择使用 --start,因此 Elasticsearch 会将该模型部署到所有可用的 Machine Learning 节点中,并在内存中加载该模型。如果有多个模型且想要选择部署哪一模型,那么我们可以通过 Kibana 的“Machine Learning”>“Model Management(模型管理)”用户界面 (UI) 管理模型的启动和停止。
测试 NER 模型
已部署的模型可以通过新的 _infer API 加以评估。输入内容则是我们希望分析的字符串。在下方请求中,text_field 是字段名称,模型应该会按照自身配置在该字段中查找输入内容。默认情况下,如果模型是通过 Eland 上传,则输入字段为 text_field。
请在 Kibana 的开发工具控制台中,尝试运行以下示例:
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_infer
{
"docs": [
{
"text_field": "Hi my name is Josh and I live in Berlin"
}
]
}
模型找到了两个实体:人名“Josh”和地名“Berlin”。
{
"predicted_value" : "Hi my name is [Josh](PER&Josh) and I live in [Berlin](LOC&Berlin)",
"entities" : {
"entity" : "Josh",
"class_name" : "PER",
"class_probability" : 0.9977303419824,
"start_pos" : 14,
"end_pos" : 18
},
{
"entity" : "Berlin",
"class_name" : "LOC",
"class_probability" : 0.9992474323902818,
"start_pos" : 33,
"end_pos" : 39
}
]
}
predicted_value 是注释文本格式的输入字符串,class_name 是预测类别,而 class_probability 则表示预测的置信水平。start_pos 和 end_pos 分别为已识别实体的开头字符和结尾字符的位置。
添加 NER 模型到 Ingest 推理管道
_infer API 是一种简单而有趣的入门方法,但是它只接受单个输入,并且检测出的实体不会存储在 Elasticsearch 中。另一种方法则是借助推理处理器,在 Ingest 管道采集文档时对其执行批量推理。
您可以在“Stack Management(堆栈管理)”UI 中定义 Ingest 管道,也可以在 Kibana 控制台中进行配置;以下示例中包含多个 Ingest 处理器:
PUT _ingest/pipeline/ner
{
"description": "NER pipeline",
"processors": [
{
"inference": {
"model_id": "elastic__distilbert-base-uncased-finetuned-conll03-english",
"target_field": "ml.ner",
"field_map": {
"paragraph": "text_field"
}
}
},
{
"script": {
"lang": "painless",
"if": "return ctx['ml']['ner'].containsKey('entities')",
"source": "Map tags = new HashMap(); for (item in ctx['ml']['ner']['entities']) { if (!tags.containsKey(item.class_name)) tags[item.class_name] = new HashSet(); tags[item.class_name].add(item.entity);} ctx['tags'] = tags;"
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{ _index }}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
以 inference 处理器开始作业,field_map 的目的是将 paragraph(源文档中要分析的字段)映射到 text_field(配置模型时要使用的字段名称)。target_field 是要写入推理结果的字段名称。
script 处理器会提取实体并按类型将其分组。最终结果会列出在输入文本中所检测出的人名、地名和组织机构名。我们要添加该 painless 脚本,以便我们可以在创建的字段中构建可视化。
此处的 on_failure 语句用于捕捉错误。它定义了两种操作。第一种,将 _index 元字段设为新值,并且文档届时会存储于此。第二种,将错误消息写入新字段:ingest.failure。导致推理失败的原因中有很多都可以轻松避免。例如,可能是因为还没有部署模型,或是某些源文档中缺失了输入字段。将推理失败的文档重定向到另一个索引并设置错误消息,而那些失败的推理也并未丢失,还可以稍后进行审查。修复错误后,在推理失败的索引中进行重新索引,以便恢复未成功的请求。
选择用于推理的文本字段
NER 可以应用于许多数据集。在此,我们以维克多·雨果 (Victor Hugo) 1862 年发表的经典小说《悲惨世界》为例。您可以使用 Kibana 的文件上传功能,上传《悲惨世界》选段的 JSON 文件样例。该文本被拆分为 14,021 个 JSON 文档,每个文档均包含一个段落。随机选取一个段落为例:
{
"paragraph": "Father Gillenormand did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"line": 12700
}
通过 NER 管道采集段落后,存储在 Elasticsearch 中的结果文档会由一个已识别的人名进行标注。
{
"paragraph": "Father Gillenormand did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"@timestamp": "2020-01-01T17:38:25",
"line": 12700,
"ml": {
"ner": {
"predicted_value": "Father [Gillenormand](PER&Gillenormand) did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"entities": [{
"entity": "Gillenormand",
"class_name": "PER",
"class_probability": 0.9806354093873283,
"start_pos": 7,
"end_pos": 19
}],
"model_id": "elastic__distilbert-base-cased-finetuned-conll03-english"
}
},
"tags": {
"PER": [
"Gillenormand"
]
}
}
标签云图是一种可视化方法,它会根据单词出现的频率对单词进行加权,对查看在《悲惨世界》中找到的实体而言,是再理想不过的信息图。打开 Kibana,创建新的基于聚合的可视化,然后选取标签云图。选择包含 NER 结果的索引,在 tags.PER.keyword 字段添加术语聚合。
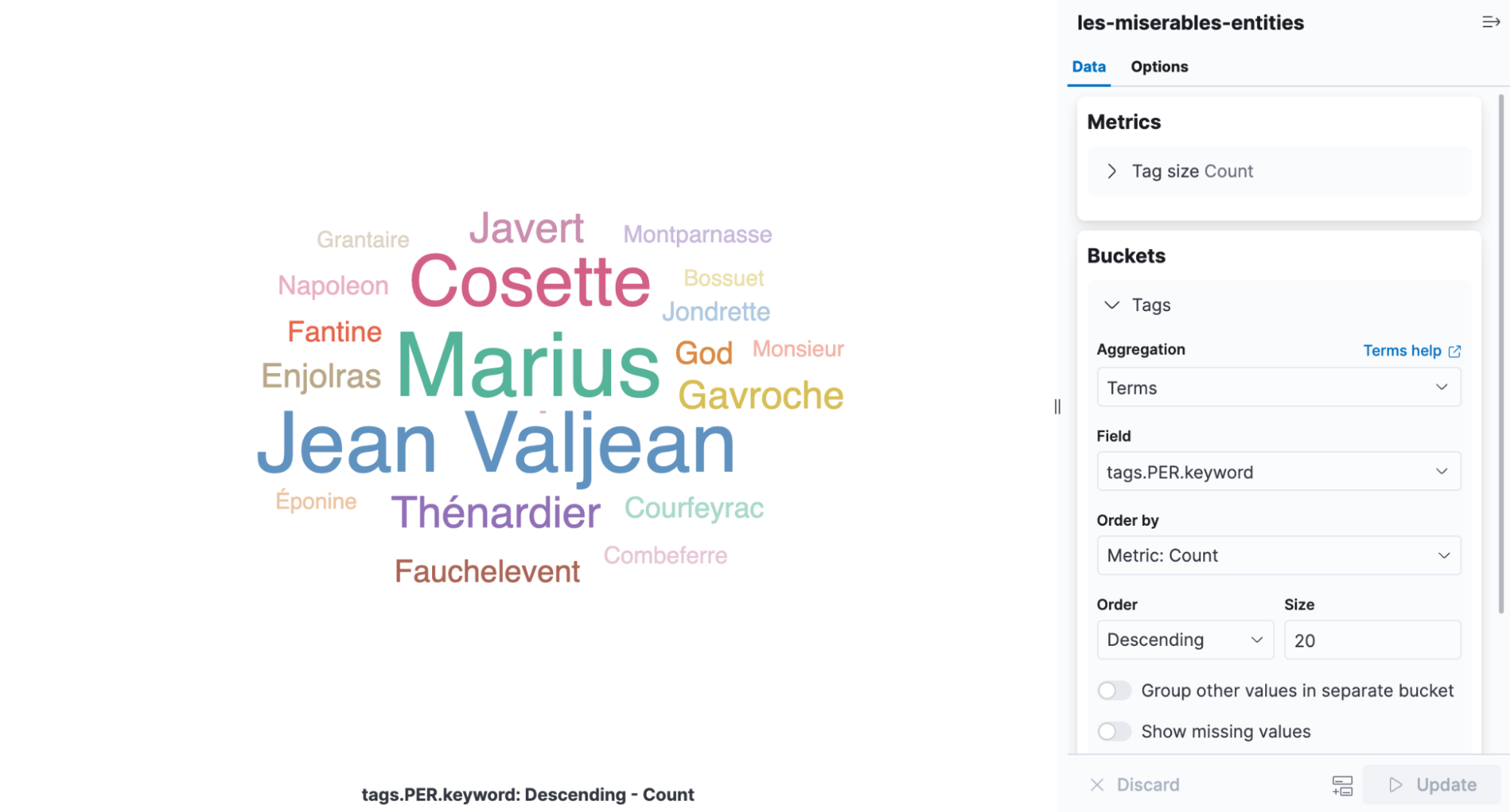
从可视化结果中可以轻松看出,Cosette、Marius、和 Jean Valjean 是这部小说中出现频率最高的人物。
调整部署
返回到“Model Management(模型管理)”UI,在“Deployment(部署)”统计下,您将找到“Avg Inference Time(平均推理时间)”。这是原生进程对单个请求进行推理所测得的时间。开始部署时,有两个控制着 CPU 资源使用方式的参数:inference_threads 和 model_threads。
inference_threads 代表每个请求中用于运行模型的线程个数。增加 inference_threads 将直接缩短平均推理时间。并行评估的请求个数则由 model_threads 控制。该设置不会缩短平均推理时间,但是会提高吞吐量。
因而一般情况下,我们会通过增加 inference_threads 的个数来调整延迟,通过增加 model_threads 的个数来提高吞吐量。两个参数的默认设置均为一个线程,修改这些设置便可大幅提升性能。我们可以使用 NER 模型,证明这种性能影响。
要更改其中一个线程设置,必须停止然后重启部署。运行 ?force=true 参数传递这一操作是为了停止 API,原因在于该部署是由 Ingest 管道引用,通常会阻止停止。
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_stop?force=true
然后,使用四个推理线程进行重启。平均推理时间会在部署重启后重置。
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_start?inference_threads=4在处理《悲惨世界》选段时,相较于一个线程的 173.86 毫秒,现在每个请求的平均推理时间缩短为 55.84 毫秒。
分享
- Share on Twitter
在 Twitter 上分享
- Share on LinkedIn
在 LinkedIn 上分享
- Share on Facebook
在 Facebook 上分享
- Share by Email
通过邮件分享
- Print this page
打印

