Simplify stream processing for generative AI applications with Confluent Cloud for Apache Flink® and Elasticsearch®


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
We’re thrilled to be partnered with Confluent today as it announces the general availability of the industry’s only cloud-native, serverless Apache Flink® service. Available directly within Confluent’s data streaming platform alongside a cloud-native service for Apache Kafka®, the new Flink offering is now ready for use on AWS, Azure, and Google Cloud.
Directly integrated with Elasticsearch®, Confluent provides a simple solution for accessing and processing data streams from across the entire business to build a real-time, contextual, and trustworthy knowledge base to fuel AI applications. Elasticsearch can cost-effectively and securely leverage these data streams to link your proprietary data with large language models (LLMs) for application output that’s up-to-date, accurate, relevant, and business specific. Use the power of Elasticsearch and its vector database with your own transformer models or integrate with generative AI to build new customer and employee experiences.
Real-time generative AI applications require real-time data processing
Successfully deploying generative AI use cases will require retrieval augmented generation (RAG) pipelines that provide relevant, real-time data streams sourced from every corner of the business. However, preparing pipelines of this sort is no easy task — especially when accounting for an ever-increasing amount of diverse data sources spanning across both legacy and modern data environments.
Ensuring applications have access to real-time pipelines with processed, prepared data will often require allocation of valuable engineering resources to manage open source tooling in-house rather than focusing on business-impacting innovation. Alternatively, securely processing data streams in multiple downstream systems (or across multiple distributed systems) is complex and inhibits data (re)usability, requiring redundant and expensive processing.
Without a reliable, cost-effective means of processing, preparing and searching real-time data streams from private data sources, the benefits of generative AI will stay out of reach for most.
Without a dependable method for processing, organizing, and searching real-time data streams from private sources, the advantages of generative AI will remain inaccessible to the majority.
Easily build high-quality, reusable data streams with the industry’s only cloud-native, serverless Flink service
Apache Flink is a unified stream and batch processing framework that has been a top-five Apache project for many years. Flink has a strong, diverse contributor community backed by companies like Alibaba and Apple. It powers stream processing platforms at many companies, including digital natives like Uber, Netflix, and Linkedin, as well as successful enterprises like ING, Goldman Sachs, and Comcast.
Fully integrated with Apache Kafka® on Confluent Cloud, Confluent’s new Flink service allows businesses to:
Effortlessly filter, join, and enrich Confluent data streams with Flink, the de facto standard for stream processing
Enable high-performance and efficient stream processing at any scale, without the complexities of infrastructure management
Experience Kafka and Flink as a unified platform, with fully integrated monitoring, security, and governance
By leveraging Kafka and Flink as a unified platform, teams can connect to data sources across any environment, clean and enrich data streams on the fly, and deliver them in real-time to Elasticsearch. This ensures that their generative AI apps have the most up-to-date view of their business.
Confluent’s fully managed Flink service is now generally available across all three major cloud service providers, providing customers with a true multi cloud solution and the flexibility to seamlessly deploy stream processing workloads everywhere their data and applications reside. Backed by a 99.99% uptime SLA, Confluent helps ensure reliable stream processing with support and services from the leading Kafka and Flink experts.
Together, Elasticsearch and Confluent enable simple development of generative AI applications
Our Confluent integration enables your teams to tap into a continuously enriched real-time knowledge base, so they can quickly scale and build AI applications using trusted data streams.
Discover how easy it is to make data flow into Elasticsearch with our walkthrough on the Elasticsearch Service Sink connector or extend your Confluent’s data collection capabilities via the new available Elastic Agent output to Kafka.
Once the data is collected, you’ll start using Elastic® as your private data search platform for — and not only — generative AI use cases, leveraging advanced and ready-to-use features from embedding creation with built-in or user-provided ML models to vector and hybrid search, on both structured and unstructured data.
System architecture
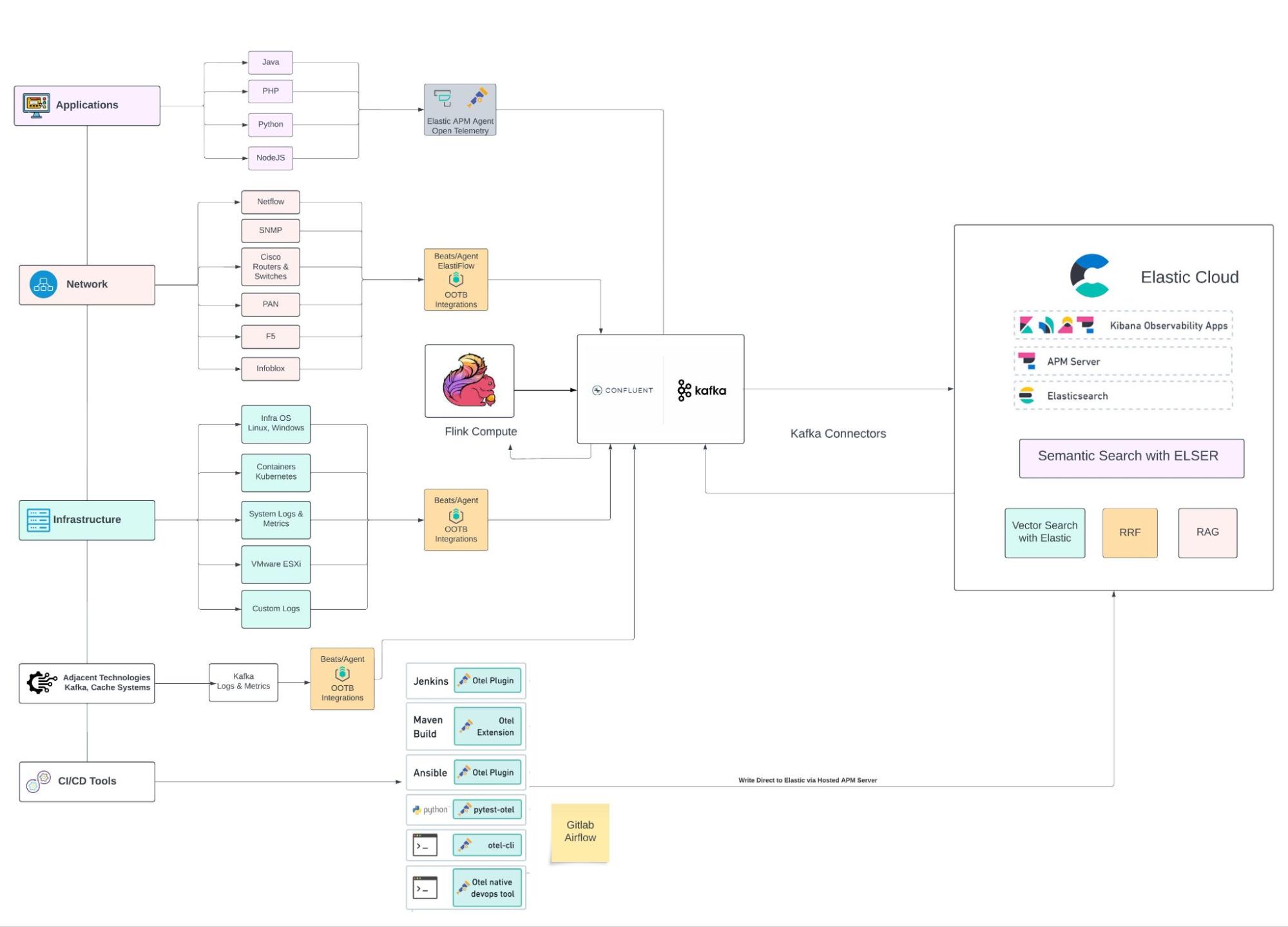
Developers are tasked with building search and generative AI applications that are relevant, performant, and cost-effective. Quite simply, you need to be able to retrieve data from all your proprietary data sources to build RAG to deliver the best, most pertinent results. Elasticsearch fulfills this need, minimizing LLM usage costs, improving token utilization, and providing private enterprise domain-specific knowledge.
Architecture of vector search
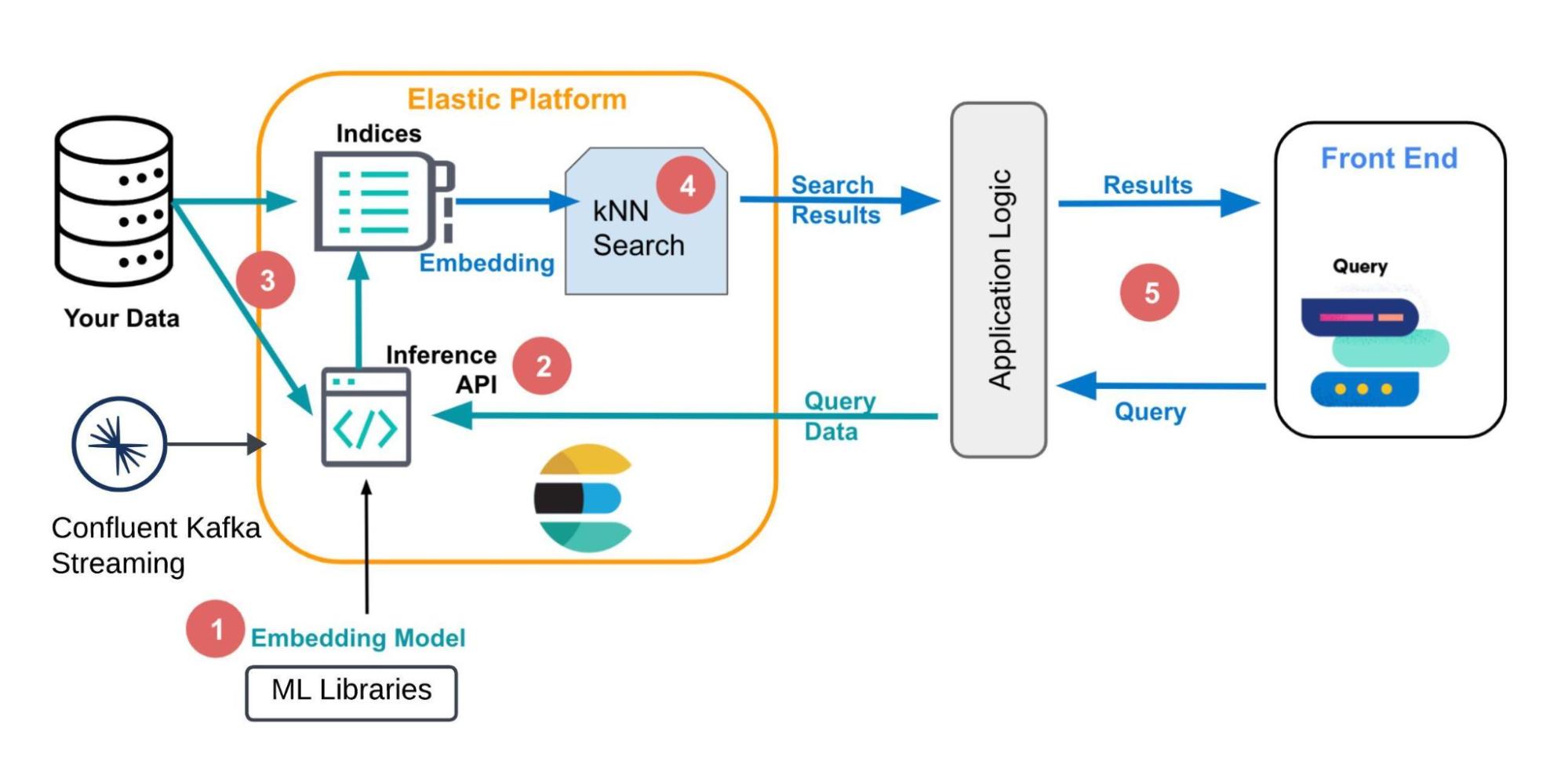
Real-time data management in generative AI-powered search use cases encompass various stages — from preprocessing data through ingestion, filtering, and aggregation, either before augmentation or upon retrieval to inform models and adapt results promptly. This process also includes the implementation of dynamic feedback loops to maintain states, such as conversation histories, and incorporate user reactions into models. Here’s where Confluent’s Flink offering will tremendously help streamline the process. Flink supports stream-stream and stream-database joins, allowing for the enrichment of data streams with information from knowledge bases, documents, policies, or regulatory standards.This enables contextual validation of responses against a wealth of information.
Some key use cases where Elastic has been focusing its generative AI efforts include:
Natural language processing (NLP): Elastic has been leveraging AI to enhance its NLP capabilities, making it easier for users to perform complex searches using natural language queries. This means users can ask questions or make requests in plain English (or other supported languages) without needing to use complex query syntax.
Enhanced observability: In the context of observability (monitoring and managing application and system performance), Elastic's AI features can automate anomaly detection and provide predictive analytics. This helps IT and DevOps teams preemptively address issues before they impact performance or user experience.
Personalized search experiences: By leveraging AI, Elastic can offer more personalized search experiences for users. This includes understanding user intent more accurately, providing more relevant search results, and even customizing search result rankings based on user behavior and preferences.
Automated code and content generation: For developers and administrators, generative AI features within Elastic like the Elastic AI Assistant (for both Observability and Security use cases) can suggest code snippets, configuration settings, and dashboards or even automate routine tasks based on the context of the work and the data within the user’s Elastic environment by allowing them to leverage human centered language queries.
To speed up adoption, Elastic introduced the Elastic Learned Sparse EncodeR (ELSER) in mid 2023, a sparse vector based project that aims to enhance Elasticsearch by incorporating advanced machine learning and AI capabilities. ELSER involves aspects such as semantic search, improving search results by understanding the context and the meaning behind the search queries, not just matching keywords. This leads to more relevant and precise search outcomes and AI-driven data analysis, utilizing AI to provide deeper insights into data patterns, trends, and anomalies to help users make informed decisions based on their data.
Getting started
Try this out yourself! One of the easiest ways to get started and explore our joint capabilities is by starting your own free Elastic Cloud trial or subscribing through your favorite cloud provider’s marketplace.
Not yet a Confluent customer? Start your free trial of Confluent Cloud today. New signups receive $400 to spend during their first 30 days — no credit card required.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print