Elastic searchable snapshots or AWS UltraWarm: Making the right choice
Your logs, metrics, security, and trace data are all invaluable to you. They are mission critical for your observability and security needs. As your IT infrastructure grows and keeps generating more and more data, your data volumes and data storage needs go up accordingly. It can quickly become cost-prohibitive to indefinitely store all of it on your hottest machines. With index lifecycle management and data tiers in Elasticsearch and the associated cost-effective hardware profiles in Elastic Cloud, we’ve provided you with the tools to reduce your data storage costs by migrating less-frequently accessed data to more cost-effective storage tiers. With Elastic searchable snapshots, first introduced in the 7.10 release, we’ve now introduced even more flexible cost controls by letting you offload data to cheap storage tiers like S3, separating storage from compute for the ultimate flexibility in managing costs.
We’ve gotten some questions from our customers on Elastic Cloud, the only hosted/managed Elasticsearch-as-a-service from the company that built Elasticsearch, about how searchable snapshots compares to AWS’s UltraWarm feature. While there are some similarities on the surface, the details matter — it’s important to know the real trade-offs as you’re making your choice. UltraWarm lacks both the breadth and depth of functionality that searchable snapshots and the data tiers provided by Elastic offer, and the Amazon Elasticsearch Service lacks features essential to give you the best experience for querying across the cost/performance spectrum.
Total cost of ownership matters
It’s very easy to accumulate a large dataset by storing application logs in Elasticsearch. It’s also become very common to store all logs, from any machine, in Elasticsearch, and to enable use cases such as security analytics, where intruders in the system can be detected and traced. Any of these use cases can generate large amounts of data, and it's important to be able to balance performance and price to ensure long-term data visibility without breaking the budget.
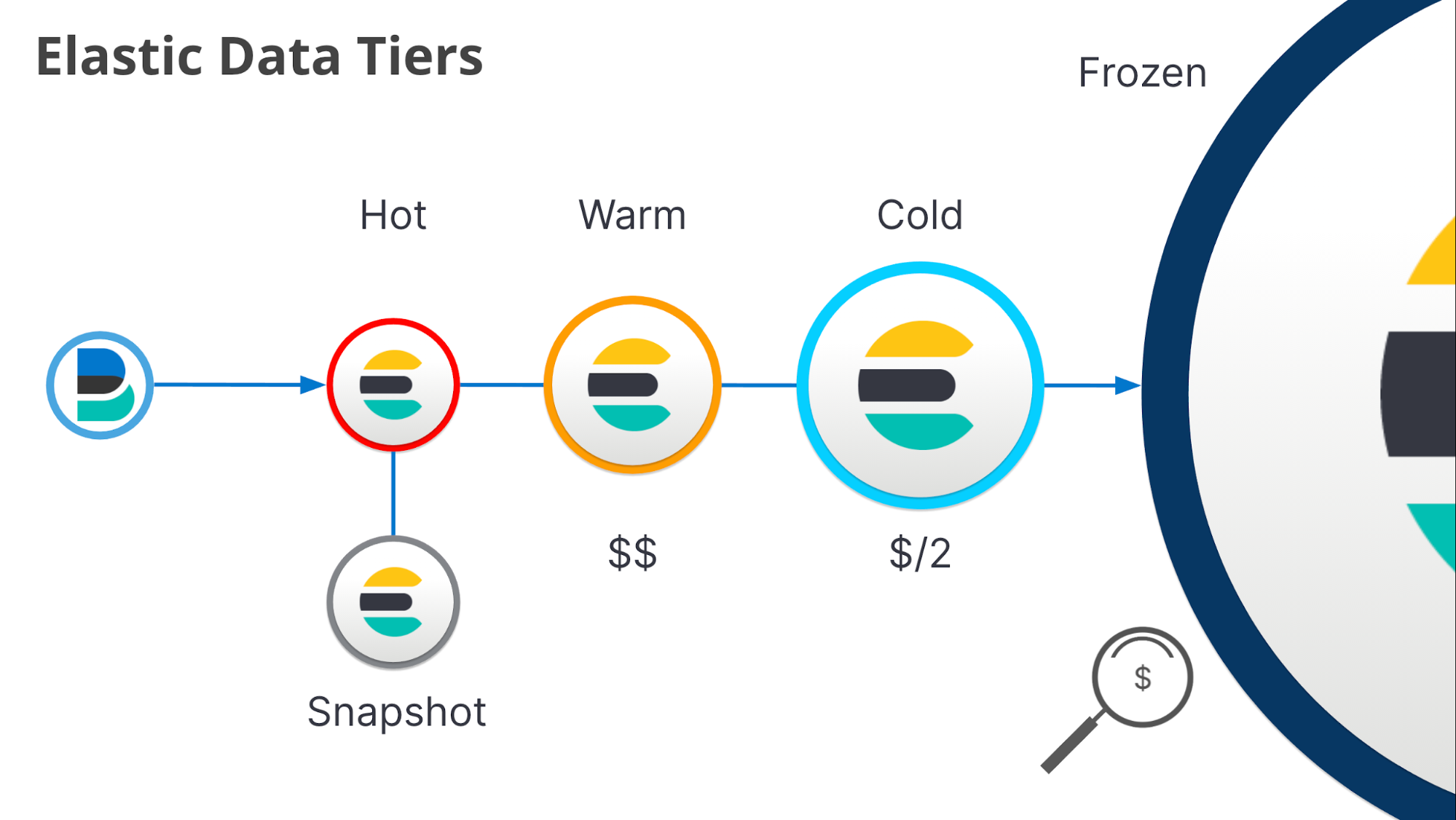
Introducing searchable snapshots and Elastic data tiers
The data tiering architecture in Elasticsearch provides you with all the tools you need to balance performance and price for your data. In addition to the hot and warm data tiers that we have supported in our products and in Elastic Cloud for years, we’ve now developed searchable snapshots to power two new data tiers: cold (already generally available) and frozen (in early access builds, soon to be available). Move data from hot to warm to keep data writable but at a lower cost. Move data when it’s ready to be read-only from the warm to the cold tier, resulting in a 50% cost reduction in storage. The cold tier still keeps your data local for fast, frequent searches and offloads redundancy to your low-cost snapshot repository. Finally, the frozen tier (coming soon) can be your long term, lowest-cost storage option for keeping your data online and searchable. It stores data directly on an object store such as S3, allowing you to separate storage from compute and query object stores directly at a substantially lower cost. It also offers a local cache for faster access to frequently searched data.
Here’s the list of Elastic data tiers:
- Hot tier nodes handle the indexing load for time series data such as logs or metrics and hold your most recent, most frequently accessed data.
- Warm tier nodes hold time series data that is less frequently accessed than your hot data but might still need to be updated.
- Cold tier nodes hold read-only time series data that is infrequently accessed but you want to retain interactive access (powered by searchable snapshots). Data stored in the cold tier will see a 50% savings in storage costs compared to the Warm tier.
- Frozen tier (coming soon) nodes hold read-only time series data that is rarely accessed but you want to retain online access (powered by searchable snapshots). Think of the frozen tier as a search box for your object store and retain petabytes of searchable data with only a small number of Elasticsearch nodes.
AWS UltraWarm
AWS has created a two-tiered storage system for data in their version of Elasticsearch: a hot tier and a lower-cost data storage option for read-only data called UltraWarm. The basic flow is as follows:
- Hot tier nodes handle the indexing load for time series data such as logs or metrics and hold your most recent, most frequently accessed data.
- All other data is moved to and kept in UltraWarm, where it’s read-only. There is a local cache for recently or frequently accessed data, but the full set of data is stored remotely in S3. Despite the name, it’s important to note that data stored in this tier is not actually warm, as warm implies the data is readily available and still writable. Data in UltraWarm is read-only and in remote storage.
Only two data tiers means higher costs and less control
Two sizes at opposite ends of the spectrum don’t end up fitting many Elasticsearch user needs. Where should data be stored, for example, when it’s just a few weeks or few months old, and still needs fast, frequent access? What about data that no longer needs to be hot but still needs to be regularly updated? Unfortunately, UltraWarm can’t solve either of these very common use cases. A better solution is to offer a gradient of storage options that users can pick and choose from to most effectively balance storage costs and search performance for their own needs: hot, warm, cold, and frozen. That’s exactly what we’ve done.
Portability across clouds and on-premises ensures flexibility for the future
Elastic: On-premises, with cloud orchestration tools, and across all major cloud providers
It’s important to have options. If a user is tied to a specific cloud vendor or cloud service, and there are price increases, service outages, or support issues, then the options to react and ensure continuous access can be limited. Searchable snapshots can be deployed wherever our users run Elasticsearch, on-premises or on any major cloud provider. UltraWarm, on the other hand, is available only on AWS.
Searchable snapshots and Elastic data tiers are available anywhere you need it:
- On-premises
- Elastic Cloud Enterprise (ECE)
- Elastic Cloud on Kubernetes (ECK)
- Elastic Cloud hosted on AWS, Google Cloud, and Microsoft Azure
Additionally, searchable snapshots and Elastic data tiers support the following object stores:
- Amazon S3 and systems implementing the S3 API (such as MinIO)
- Azure Blob Storage
- Google Cloud Storage (GCS)
We’re now in the process of creating a repository analyzer for storage vendors to self-assess the many S3-compatible APIs for known issues with Elasticsearch. S3 compatible APIs (such as MinIO) work today with searchable snapshots and we would like to give our partners the tools to ensure correctness with their S3-compatible repository of choice. We’re committed to supporting as many object stores as possible. Stay tuned for further updates and announcements in this area.
Limited options to use UltraWarm
Amazon has publicly stated that they will only allow UltraWarm functionality within AWS and will have no option for on-premises users or users of other cloud providers. Without that support, customers face increased AWS lock-in, making it harder for AWS customers to use alternative services (and alternatives to S3).
Elasticsearch expertise
Elastic: Get support from the development team behind Elasticsearch
Mission-critical applications require a high level of support. Finding bugs is inevitable with any software, but having support from the maker of the software can reduce risks to the user. Elastic develops, maintains, and supports Elasticsearch, and also employs a significant number of the top Apache Lucene committers. If there is a problem in Elasticsearch, customers can rely upon the deep expertise at Elastic to quickly and adroitly resolve the issue.
When it comes to AWS’s support for UltraWarm, it is important to keep in mind that Amazon Elasticsearch Service does not have a relationship with Elastic. When critical issues or bugs arise, AWS will need to find and resolve the root cause without the help of the Elasticsearch development team at Elastic.
Open development model
All Elasticsearch features and code are developed in the open, via the Elasticsearch GitHub repository. Any bug, issue, or feature request can be filed, and users can engage directly with the Elasticsearch engineering team. With closed-source features like UltraWarm, it means that the entire Amazon Elasticsearch Service is a black box, with no visibility of the source code nor direct engagement with the engineering team behind it.
AWS UltraWarm lacks the infrastructure for long-running queries
Elastic: Large infrastructure improvements to ensure a good user experience for long running queries
Elasticsearch is really, really fast
From the very beginning, Elasticsearch was designed to be really, really fast. Almost any query executed returns quickly and provides fast search results to users. Searchable snapshots allows you to draw trade offs between that fast query performance and other things such as data storage costs. While searchable snapshots is still fast, the data densities it supports means that you can search over vast amounts of data, which can lead to longer running queries. Think about searching over petabytes of data while handling a regulatory audit, or a threat hunting scenario where you need to search through years of data.
Because Elasticsearch was designed with the assumption that queries execute really, really fast, we’ve rearchitected certain aspects of the Elastic Stack to optimize the user experience when executing these long-running queries. AWS UltraWarm cannot leverage these optimizations, resulting in an inconsistent and even poor user experience when searching larger volumes of data stored in S3.
Asynchronous search
When a search executes on many shards allocated to less frequently accessed tiers, you do not expect search results to return in milliseconds. You do not want to synchronously wait for these long-running searches to return either. Asynchronous search allows you to separate submitting a search request from retrieving results. Kibana has been seamlessly and automatically using async search since version 7.7. Instead of waiting, you can monitor the progress of the search request in Kibana, and return later to retrieve the results. You can even obtain partial results of the search as they become available.
Search sessions in Kibana
When you adjust the timepicker on a Kibana dashboard to include a large range of your historical data in less frequently accessed tiers, you don't want to be forced to keep the browser window open until the search completes. You want the flexibility to navigate away from the page, and return after the search session for the dashboard has finished executing. With search sessions in Kibana, you can send the searches that back a dashboard to the background, and later return to the dashboard to see the results.
Asynchronous search and search sessions in Kibana are foundational to giving you a good experience when searching over large volumes of data in less frequently accessed tiers. These features were built by the experts in the search infrastructure inside of Elasticsearch and Kibana.
Efficiently searching extremely large data sets
We have built optimizations into Elasticsearch that are specifically designed to improve performance when searching over large historical datasets. We do this by only executing searches against shards that could possibly match the query being executed. In studying how effective these optimizations were against searchable snapshots, we discovered that we could optimize the layout of the low-level indexes to minimize the data fetched to determine if a shard could possibly match the query. Only those parts of the index that are actually needed to answer the request are pulled from the object store, thereby making much more efficient use of the local disk cache and increasing performance. We’ve relied on our deep expertise in Lucene to contribute several upstream changes to Lucene to ensure that searches with searchable snapshots are fast and minimize the amount of data they need to download to service the search.