O que é machine learning supervisionado?
Definição de machine learning supervisionado
O machine learning supervisionado, ou aprendizado supervisionado, é um tipo de machine learning (ML) usado em aplicativos de inteligência artificial (IA) para treinar algoritmos usando conjuntos de dados rotulados. Ao alimentar um algoritmo com grandes conjuntos de dados rotulados, o machine learning supervisionado "ensina" o algoritmo a prever resultados com precisão. É o tipo de machine learning mais comumente usado.
O machine learning supervisionado, como todo machine learning, funciona por meio do reconhecimento de padrões. Ao analisar um conjunto específico de dados rotulados, um algoritmo pode detectar padrões e gerar previsões com base nesses padrões derivados quando forem consultados. Para chegar a um estágio de previsão preciso, o processo de machine learning supervisionado requer coleta de dados e, em seguida, rotulagem. Em seguida, o algoritmo é treinado nesses dados rotulados para classificar dados ou prever resultados com precisão. A qualidade do resultado está diretamente relacionada à qualidade dos dados: melhores dados significam melhores previsões.
Os exemplos de machine learning supervisionado variam do reconhecimento de imagens e objetos à análise de sentimento do cliente, detecção de spam e análise preditiva. Como resultado, o machine learning supervisionado é usado em vários setores, como saúde, finanças e comércio eletrônico, para ajudar a otimizar a tomada de decisões e impulsionar a inovação.
Como funciona o machine learning supervisionado?
O machine learning supervisionado funciona coletando e rotulando dados, treinando modelos e iterando o processo com novos conjuntos de dados. É um processo de duas etapas: definir o problema que o modelo pretende resolver, seguido pela coleta de dados:
- Etapa 1: definir o problema que o modelo pretende resolver. O modelo está sendo usado para fazer previsões relacionadas aos negócios, automatizar a detecção de spam, analisar o sentimento do cliente ou identificar imagens? Isso determina quais dados serão necessários, levando à próxima etapa do fluxo de trabalho
- Etapa 2: coleta de dados. Depois que os dados são rotulados, eles são enviados ao algoritmo em treinamento. O modelo é então testado, refinado e implantado para realizar tarefas de classificação ou regressão.
Coleta de dados e rotulagem
A coleta de dados é a primeira etapa do machine learning supervisionado. Os dados podem vir de várias fontes, como bancos de dados, sensores ou interações do usuário. Eles são pré-processados para garantir consistência e relevância. Depois de coletado, esse grande conjunto de dados recebe rótulos. Cada elemento dos dados de entrada recebe um rótulo correspondente. Embora a classificação de dados possa ser demorada e cara, é necessário ensinar os padrões do modelo para que ele possa fazer previsões. A qualidade e a precisão desses rótulos afetam diretamente a capacidade do modelo de aprender e fazer previsões relevantes. O resultado será tão bom quanto a entrada.
Treinamento de modelo
Durante o treinamento, o algoritmo analisa os dados de entrada e aprende a mapeá-los para os rótulos de saída corretos. Esse processo envolve ajustar os parâmetros do modelo para minimizar a diferença entre os resultados previstos e os rótulos reais. O modelo melhora a precisão aprendendo com os erros cometidos durante o treinamento. Depois que o modelo é treinado, ele é submetido à avaliação. Os dados de validação são usados para determinar a precisão de um modelo. Dependendo dos resultados, ele é ajustado conforme necessário.
Quanto mais dados um modelo absorve, mais padrões ele aprende e, em tese, mais precisas se tornam as previsões. O aprendizado contínuo é a base do machine learning: o desempenho do modelo melhora à medida que ele continua aprendendo com conjuntos de dados rotulados.
Depois de implantado, o machine learning supervisionado pode realizar dois tipos de tarefas: classificação e regressão.
A classificação se baseia em um algoritmo para atribuir uma classe a um determinado ponto ou conjunto de dados discretos. Em outras palavras, ele distingue categorias de dados. Em problemas de classificação, o limite de decisão define classes.
A regressão depende de um algoritmo para entender a relação entre variáveis de dados dependentes e independentes contínuas. Em problemas de regressão, o limite de decisão define a linha de melhor ajuste ou proximidade probabilística.
Algoritmos de machine learning supervisionado
Diferentes algoritmos e técnicas são usados no machine learning supervisionado para tarefas de classificação e regressão, desde classificação de texto até previsões estatísticas.
Árvore de decisão
Um algoritmo de árvore de decisão é um algoritmo de aprendizado supervisionado não paramétrico, composto por um nó raiz, ramos, nós internos e nós folha. A entrada vai do nó raiz, passando pelas ramificações, até os nós internos, onde o algoritmo processa a entrada e toma uma decisão, gerando nós folha. As árvores de decisão podem ser usadas tanto para tarefas de classificação quanto de regressão. Elas são ferramentas úteis de mineração de dados e descoberta de conhecimento: elas permitem que o usuário acompanhe por que uma saída foi produzida ou por que uma decisão foi tomada. No entanto, as árvores de decisão são propensas a sobreajuste; elas têm dificuldade em lidar com mais complexidade. Por esse motivo, árvores de decisão menores são mais eficazes.
Regressão linear
Os algoritmos de regressão linear predizem o valor de uma variável, a variável dependente, com base no valor de outra variável, a variável independente. As previsões são baseadas no princípio de uma relação linear entre variáveis, ou de que existe uma conexão “linear” entre variáveis contínuas, como salário, preço ou idade. Modelos de regressão linear são usados para fazer previsões nas áreas de biologia, ciências sociais, ambientais e comportamentais e negócios.
Redes neurais
As redes neurais usam nós compostos de entradas, pesos, limites (às vezes chamados de polarização) e saídas. Esses nós são dispostos em camadas em uma estrutura de camadas de entrada, ocultas e de saída que se assemelham ao cérebro humano, daí o nome neural. As redes neurais, consideradas algoritmos de aprendizado profundo, constroem uma base de conhecimento a partir de dados de treinamento rotulados. Portanto, elas podem identificar padrões e relacionamentos complexos nos dados. Elas são um sistema adaptativo e são capazes de “aprender” com os erros para melhorar continuamente. As redes neurais podem ser usadas em aplicações de reconhecimento de imagem e processamento de linguagem.
Floresta aleatória
Os algoritmos de floresta aleatória são uma coleção (ou floresta) de algoritmos de árvore de decisão não correlacionados programados para produzir um único resultado a partir de várias saídas. Os parâmetros do algoritmo de floresta aleatória incluem o tamanho do nó, o número de árvores e o número de recursos. Esses hiperparâmetros são definidos antes do treinamento. A dependência de métodos de ensacamento e aleatoriedade de recursos garante a variabilidade dos dados no processo de decisão e produz previsões mais precisas. Essa é a principal diferença entre árvores de decisão e florestas aleatórias. Como resultado, os algoritmos de floresta aleatória permitem mais flexibilidade, o ensacamento de recursos ajuda a estimar os valores ausentes, o que garante a precisão quando determinados pontos de dados estão ausentes.
Máquina de vetor de suporte (SVM)
As máquinas de vetores de suporte (SVM) são mais comumente usadas para classificação de dados e, eventualmente, para regressão de dados. Para aplicações de classificação, uma SVM constrói um limite de decisão que ajuda a distinguir ou classificar pontos de dados, como frutas versus vegetais ou mamíferos versus répteis. A SVM pode ser usada para reconhecimento de imagem ou classificação de texto.
Naïve Bayes
Naïve Bayes é um algoritmo de classificação probabilística baseado no teorema de Bayes. Ele pressupõe que os recursos em um conjunto de dados são independentes e que cada recurso, ou preditor, tem um peso uniforme no resultado. Essa suposição é chamada de "ingênua" (naïve) porque, muitas vezes, pode ser contrariada em um cenário do mundo real. Por exemplo, a próxima palavra em uma frase depende da que vem antes dela. Apesar disso, a probabilidade única de cada variável torna os algoritmos Naïve Bayes computacionalmente eficientes, especialmente para tarefas de classificação de texto e filtragem de spam.
K vizinhos mais próximos
O K vizinho mais próximo, também conhecido como KNN, é um algoritmo de aprendizado supervisionado que usa a proximidade de variáveis para prever resultados. Em outras palavras, ele parte do pressuposto de que pontos de dados semelhantes existem próximos uns dos outros. Depois de treinado com dados rotulados, o algoritmo calcula a distância entre uma consulta e os dados que ela memorizou, a base de conhecimento, e formula uma previsão. O KNN pode usar vários métodos de cálculo de distância (Manhattan, Euclidean, Minkowski, Hamming) para estabelecer o limite de decisão no qual a previsão se baseia. O KNN é usado para tarefas de classificação e regressão, incluindo classificação de relevância, pesquisa por similaridade, reconhecimento de padrões e mecanismos de recomendação de produtos.
Desafios e limitações do machine learning supervisionado
Embora o machine learning supervisionado permita um alto nível de precisão nas previsões, é uma técnica de machine learning que consome muitos recursos. Depende de processos caros de rotulagem de dados, exigindo grandes conjuntos de dados e, como resultado, é vulnerável a sobreajustes.
- O custo de rotular dados: um dos principais desafios do aprendizado supervisionado é a necessidade de conjuntos de dados grandes e rotulados com precisão. A precisão desses rótulos é diretamente proporcional à precisão de um modelo, portanto, a qualidade é fundamental. É um esforço demorado, às vezes exigindo conhecimento especializado (dependendo dos dados e do uso pretendido do modelo), o que, por sua vez, pode ser muito caro. Em áreas como saúde ou finanças, onde os dados são confidenciais e complexos, a obtenção de conjuntos de dados rotulados de alta qualidade pode ser desafiadora.
- Necessidade de grandes conjuntos de dados: a dependência de um modelo de aprendizado supervisionado de grandes conjuntos de dados pode ser um desafio significativo por dois motivos: coletar e rotular grandes quantidades de dados de qualidade exige muitos recursos, e é difícil encontrar o equilíbrio certo entre muitos dados e dados bons o bastante. Conjuntos de dados grandes são necessários para um treinamento eficaz, mas conjuntos de dados muito amplos levam a um ajuste excessivo.
- Sobreajuste: é uma preocupação comum no aprendizado supervisionado. Isso ocorre quando um modelo é exposto a muitos dados de treinamento e captura ruídos ou detalhes irrelevantes, pois existem muitos dados. Isso afeta a qualidade das previsões e leva a um desempenho ruim em dados novos e não vistos. Para combater ou evitar o sobreajuste, os engenheiros confiam em técnicas de validação cruzada, regularização ou poda.
O pré-processamento de dados está no centro desses desafios. Pode ser demorado e caro, mas, com as ferramentas certas, você pode atenuar os desafios de custo, qualidade e sobreajuste.
Machine learning supervisionado versus não supervisionado
O machine learning pode ser supervisionado, não supervisionado e semis-supervisionado. Cada método de treinamento de dados tem resultados diferentes e é usado em contextos diferentes. O machine learning supervisionado requer conjuntos de dados rotulados para treinar dados, mas melhora a precisão graças a conjuntos de dados grandes e de alta qualidade.
Em contrapartida, o machine learning não supervisionado usa conjuntos de dados não rotulados para treinar um modelo para previsões. O modelo identifica padrões entre pontos de dados não rotulados sozinho, às vezes resultando em menos precisão. O aprendizado não supervisionado é normalmente usado para tarefas de agrupamento, associação ou redução de dimensionalidade.
Machine learning semi-supervisionado
O machine learning semi-supervisionado é uma combinação de técnicas de aprendizado supervisionado e não supervisionado. Os algoritmos de aprendizagem semi-supervisionada são treinados em pequenas quantidades de dados rotulados e grandes quantidades de dados não rotulados. Isso alcança melhores resultados do que os modelos de aprendizado não supervisionado com menos exemplos rotulados. O aprendizado semi-supervisionado é um método híbrido que pode ser especialmente útil nos casos em que rotular grandes conjuntos de dados é impraticável ou caro.
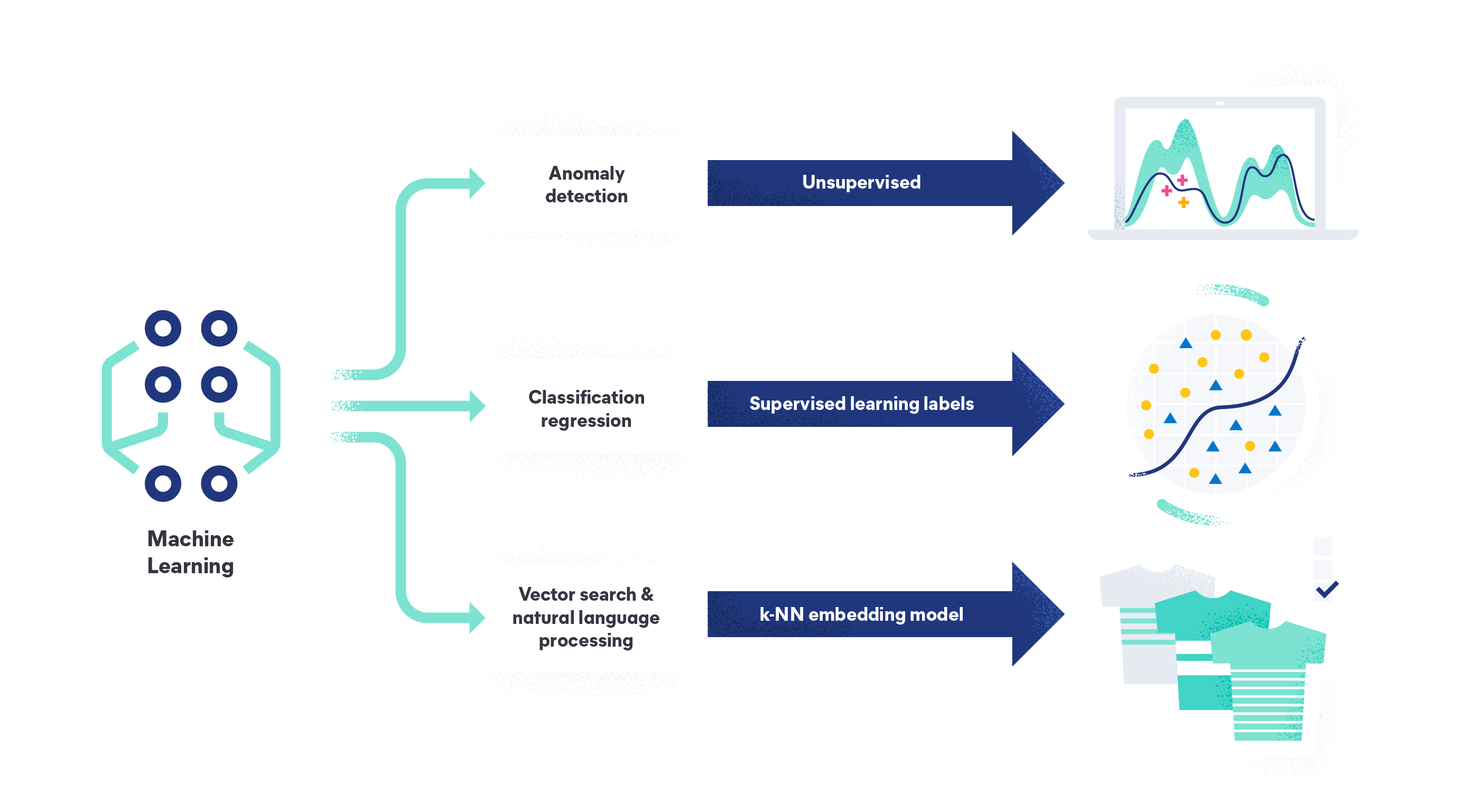
Entender a diferença entre esses métodos de machine learning é fundamental para que você escolha a solução certa para a tarefa em questão.
Machine learning facilitado com a Elastic
O machine learning começa com dados é aí que entra a Elastic.
Com o machine learning da Elastic, você pode analisar seus dados para encontrar anomalias, realizar análises de data frame e analisar dados em linguagem natural. O machine learning elástico elimina a necessidade de uma equipe de ciência de dados, projetando uma arquitetura de sistema do zero ou movendo dados para uma estrutura de terceiros para treinamento de modelos. Como plataforma de IA de pesquisa, nossos recursos permitem que você ingira, compreenda e crie modelos com seus dados, ou confie em nosso modelo não supervisionado pronto para uso para detecção de anomalias e valores atípicos.
Saiba mais sobre como a Elastic pode ajudar você a enfrentar os desafios de dados com o machine learning.