Neu in Elasticsearch: durchsuchbare Snapshots
Zu den spannendsten Neuerungen in 7.10 gehört die Beta-Version der Funktion „Durchsuchbare Snapshots“, mit der Sie den Objektspeicher Ihrer Wahl (z. B. AWS S3, Microsoft Azure Storage oder Google Cloud Storage) auf ganz neue Art und Weise nutzen und für sich das richtige Verhältnis zwischen einer drastischen Reduzierung der Speicherkosten, dem Ingestieren und Aufbewahren größerer Datenmengen im Elastic Stack und der Möglichkeit finden können, Daten mit der vom Elastic Stack bekannten Blitzgeschwindigkeit zu durchsuchen. Die Unterstützung für das Sichern von Daten in kostengünstigen Objektspeichern ist an sich nichts Neues, aber mit der Einführung durchsuchbarer Snapshots stehen die so archivierten Daten auch für Suchabfragen zur Verfügung.
Die durchsuchbaren Snapshots werden die Grundlage für zwei neue erstklassige Daten-Tiers bilden: eine Tier für „kalte“ Daten, die in 7.10 bereits als Beta bereitsteht, und eine künftige Tier für „eingefrorene“ Daten. Zur Vereinfachung des Daten-Lifecycle-Managements unterstützen wir schon seit Langem das Daten-Tiering mit einer Tier für „heiße“ Daten für die Hochgeschwindigkeitssuche und einer Tier für „warme“ Daten mit geringeren Kosten und geringerer Performance. Die neue Tier für „kalte“ Daten, die durch die Einführung durchsuchbarer Snapshots möglich gemacht wird, kann die Speicherkosten um bis zu 50 % reduzieren. Dazu wird die lokale Speicherdichte Ihrer „Read-only“-Daten erhöht, indem die redundanten Kopien der Daten auf einen kostengünstigen Objektspeicher verlagert werden. Bei der Tier für „eingefrorene“ Daten, die sich derzeit noch in der Entwicklung befindet, wird das Ganze noch ein wenig weitergetrieben, indem Daten komplett in den kostengünstigen Objektspeicher verschoben werden, wo sie aber vollständig durchsuchbar bleiben. Um die Abfragegeschwindigkeit zu beschleunigen, werden Daten, auf die häufig zugegriffen wird, in einem lokalen Cache zwischengespeichert werden. Wie bei allen Features, die Sie von uns kennen, gibt es APIs, mit denen sich direkt steuern lässt, wie durchsuchbare Snapshots Daten aus Ihrem Objektspeicher laden, verwalten und durchsuchen. Diese neuen Funktionen machen es einfacher und billiger, die wachsenden Datenmengen in Elastic zu verwalten, und bieten einen kostengünstigen Weg, die Anforderungen an die Datenaufbewahrung zu erfüllen. Gleichzeitig ebnen sie den Weg für neue Anwendungsfälle. So können Sie zum Beispiel Ihr Security-Team in die Lage versetzen, unbegrenzt zurückzuschauen oder selbst die Black-Friday-Performances der letzten Jahre miteinander zu vergleichen.
Die Entwicklung geht immer weiter
Zeitreihendaten finden sich heute überall, ob Logdaten, Metriken, Traces oder Sicherheitsereignisse. Sie bilden das Rückgrat für eine Vielzahl von Anwendungsfällen, von der Security bis zur Observability. Wir arbeiten ständig daran, die Verwaltung und Skalierung dieser Daten einfacher, schneller und effizienter zu machen. Das ist auch wichtig, denn die Datenmengen wachsen rasant. Wenn zum Beispiel pro Tag ein Terabyte an Daten anfällt, sind das sieben Terabyte pro Woche, und wenn man diese Daten über mehrere Jahre aufbewahrt, gelangt man sehr schnell in Petabyte-Bereiche. Nutzer brauchen eine Möglichkeit, dieses exponentielle Speicherplatzwachstum in den Griff zu bekommen, ohne dabei die Fähigkeit zu verlieren, diese Daten durchsuchen zu können.
Um eine Lösung für dieses Problem finden zu können, haben wir uns den Lebenszyklus von Daten angesehen. Bei frisch ingestierten Daten besteht eine hohe Wahrscheinlichkeit, dass sie viel gesucht werden. So braucht man zum Beispiel zur Untersuchung eines Vorfalls schnellen Zugriff auf alle relevanten Daten, um das Problem eingrenzen und lösen zu können. Kommt es zu einem Angriff auf einen Host oder eine Anwendung, hängt das Ausmaß des angerichteten Schadens häufig davon ab, wie schnell Sie reagieren können. Aber Daten können auch in verschiedene Nutzungsebenen eingeteilt werden, abhängig von der Quelle oder vom Typ der Daten. Einige Daten müssen lediglich aus rechtlichen oder Compliance-Gründen aufbewahrt werden, andere werden für gelegentliche Rückblicke zu Vergleichszwecken benötigt. Nutzer benötigen daher für diese unterschiedlichen Anforderungsniveaus auf Basis des Alters, der Datenquelle oder anderer Kriterien unterschiedliche Stufen von Speicher- und Verarbeitungsleistung.
Wir haben es uns zur Aufgabe gemacht, Sie in die Lage zu versetzen, Kosten, Geschwindigkeit und Funktionalität in ein Verhältnis zu bringen, das Ihren individuellen Anforderungen gerecht wird. Das bedeutet Investitionen auf allen Ebenen unseres Stacks, aber eine der Hauptsäulen unserer Herangehensweise sind Daten-Tiers – die Verwaltung des Lebenszyklus von Daten. Dieses Konzept ist keineswegs neu; es kam schon in den frühesten Versionen von Elasticsearch zum Einsatz. Das Index-Lifecycle-Management (ILM) stellt eine Reihe von Konventionen bereit, die es einfach machen, Daten auf Knoten für „heiße“ Daten (schnelle Maschinen mit SSDs) und Knoten für „warme“ Daten (kostengünstigere Maschinen, zumeist mit Festplatten) zu verwalten – das wird in Elastic Cloud schon seit Jahren unterstützt. Beim Snapshot-Lifecycle-Management (SLM) können die Daten auch in kostengünstigen Objektspeichern von AWS, Google und Azure sowie von Anbietern von On-Premises-Speichern gesichert und gespeichert werden. Diese Snapshots werden zwar in vielen Deployments angelegt, waren aber bisher kein aktiver Bestandteil des Data-Tiering. Warum? Ganz einfach, weil Snapshots nicht durchsuchbar waren. Mit der Einführung der durchsuchbaren Snapshots ist das jedoch hinfällig geworden. Sie ermöglichen es uns, neue, günstigere Daten-Tiers zu schaffen, die die kostengünstigeren Objektspeicher nutzen, und so Ihre Backups zum Leben zu erwecken.
Wir stellen vor: durchsuchbare Snapshots
Die Einführung von durchsuchbaren Snapshots ist für uns eine superspannende Sache, erlaubt sie doch ganz neue Nutzungsmöglichkeiten für Objektspeicher wie S3. Mit durchsuchbaren Snapshots können Sie Ihre Daten wie bisher auch als Snapshots in einem beliebigen Objektspeicher sichern, gleichzeitig aber den Objektspeicher zum Leben erwecken, weil Ihre Snapshots von Elasticsearch durchsucht werden können. Da lohnt es sich tatsächlich, den Objektspeicher ständig online und verfügbar zu lassen. Um dies zu ermöglichen und den Nutzern ein gutes Nutzungserlebnis zu bieten, haben wir auf allen Ebenen unserer Produkte, von Kibana über Elasticsearch bis hinunter zu Lucene, entsprechende Veränderungen an unseren Produkten vorgenommen. So haben wir zum Beispiel unsere Lucene-Expertise genutzt, um den Suchmechanismus so zu optimieren, dass nur die zur Beantwortung der konkreten Abfrage oder zum Laden des jeweiligen Dashboards tatsächlich benötigten Teile des Snapshot-Index abgerufen werden. Durchsuchbare Snapshots sorgen für eine reibungslose und schnelle Wiederherstellung der Daten aus Ihren in Snapshots festgehaltenen Indizes in S3 oder anderen Objektspeichern und haben es uns ermöglicht, neue Daten-Tiers zu entwickeln, die mehr Leistung zu niedrigeren Kosten bieten.
Die Tier für „kalte“ Daten
Die neue Tier für „kalte“ Daten, die in 7.10 als Beta veröffentlicht wird, reduziert den benötigten Cluster-Speicherplatz im Vergleich zur Tier für „warme“ Daten um bis zu 50 % – mit derselben Zuverlässigkeit und Redundanz wie bei den Tiers für „heiße“ und für „warme“ Daten. Sollte es auf einem Ihrer Knoten zu einem Hardware-Ausfall kommen, werden die Daten ohne Einschränkungen automatisch wiederhergestellt. Damit werden Datenabfragen wie „Wie lässt sich diese Spitze mit dem letzten Monat vergleichen?“ oder „Hat sich dieser Nutzer in den letzten sechs Monaten in ein zugangsbeschränktes System eingeloggt?“ wesentlich kostengünstiger.
Wie haben wir das gemacht? Bei den Tiers für „heiße“ und für „warme“ Daten wird die Hälfte des Speicherplatzes für die Speicherung von Replikat-Shards genutzt. Diese redundanten Kopien ermöglichen eine schnelle und gleichbleibende Abfrage-Performance und sorgen für das nötige Maß an Resilienz, falls es einmal zum Ausfall einer Maschine kommt. In einem solchen Fall übernimmt ein Replikat nahtlos die Aufgaben der Primärmaschine, sodass das Indexieren und die Suchen ungehindert fortgesetzt werden können.
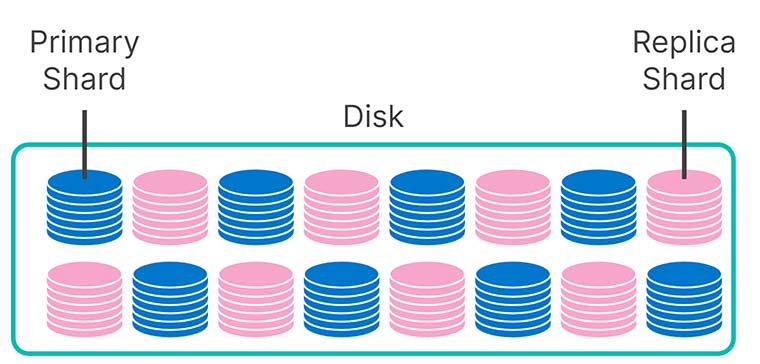
Aber sobald die Daten „read-only“ werden, kann auf die Redundanz ganz einfach verzichtet werden. Ihr Snapshot-Speicher eignet sich hervorragend dafür, da es wesentlich günstiger ist, Daten in S3 aufzubewahren, als sie auf lokalen SSDs oder Festplatten zu speichern. Ihre Replikat-Shards werden also in der Tier für „kalte“ Daten als Snapshots in S3 gespeichert. So können wir die nutzbare Kapazität Ihrer Knoten für „kalte“ Daten bei gleichbleibenden Kosten verdoppeln, ohne allzu große Einbußen bei der Abfrage-Performance hinnehmen zu müssen.
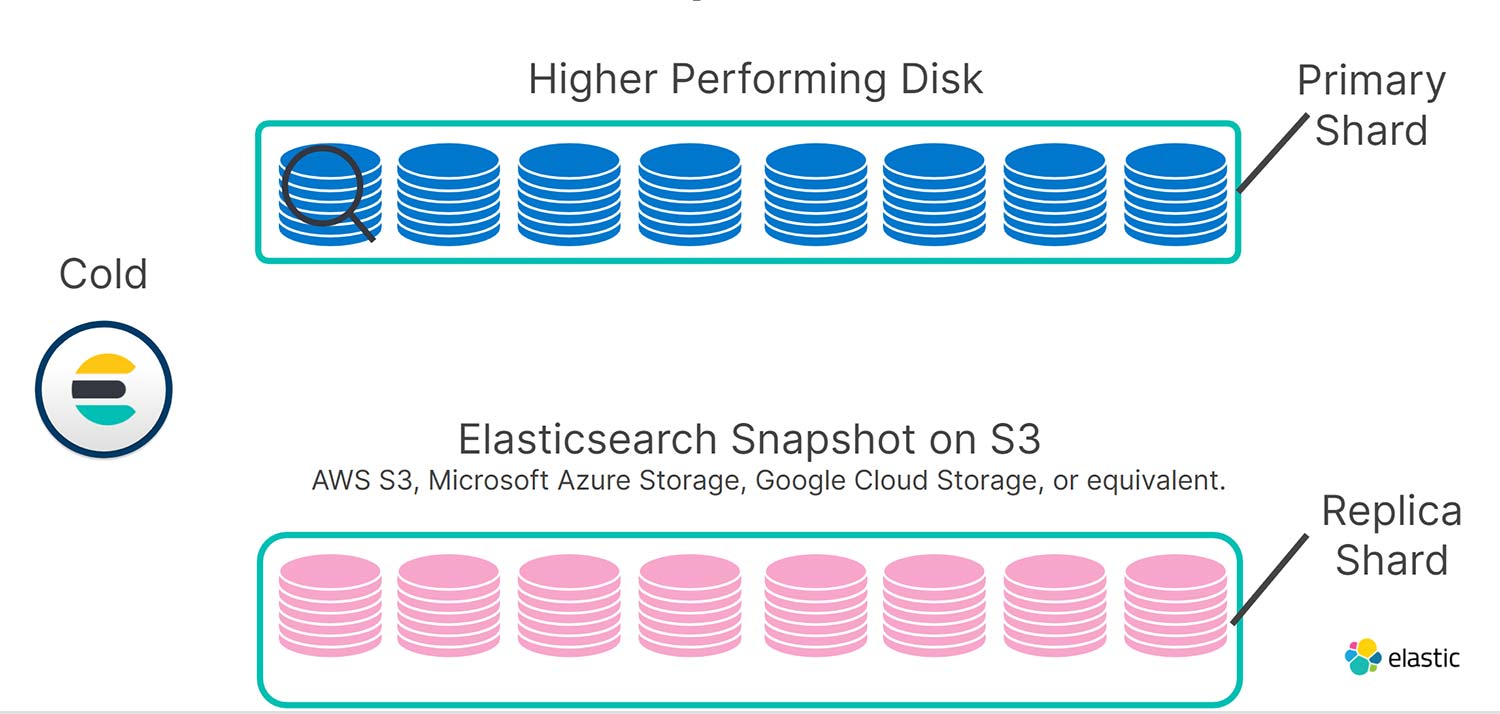
Sollte einmal ein lokaler Knoten oder eine Festplatte in der Tier für „kalte“ Daten ausfallen, können wir die Funktion „Durchsuchbare Snapshots“ nutzen, um die Daten mithilfe der als Snapshots in S3 gespeicherten Replikatindizes automatisch wiederherstellen zu lassen. Diese Indizes sind dann für die Bearbeitung von Suchanfragen in einem Bruchteil der Zeit verfügbar, die eine reguläre Snapshot-Wiederherstellung benötigen würde. So greift eins ins andere.
Die Tier für „eingefrorene“ Daten
Stellen Sie sich vor, Sie könnten für Security-Untersuchungen unbegrenzt lange in die Vergangenheit zurückblicken oder Drilldowns in APM-Rohdaten durchführen, um zu sehen, wie sich das Verhalten Ihrer Kunden in den letzten beiden Jahren verändert hat. Mit der Tier für „eingefrorene“ Daten wird dies möglich – und sie eröffnet auch völlig neue Anwendungsfälle für Datentypen und Datenmengen, die für Elasticsearch bisher aus Kostengründen einfach nicht in Frage kamen. Denken Sie nur daran, was das Konzept durchsuchbarer Daten in S3 für Ihre geschäftlichen Ziele bedeuten kann: Die Tier für „eingefrorene“ Daten, an der derzeit noch aktiv gearbeitet wird, wird das direkte Durchsuchen von Daten in S3 oder einem beliebigen anderen Objektspeicher ermöglichen. Mit einer solchen Tier gibt es keine Notwendigkeit mehr, irgendwelche Daten lokal zu speichern – alles kann einfach als Snapshot in S3 abgelegt werden. Und wenn Sie die Daten doch einmal für ein Audit oder eine Sicherheitsuntersuchung benötigen sollten, müssen Sie sie nicht erst rehydrieren, sondern Sie können die durchsuchbaren Snapshots einfach direkt abfragen.
Was wir mit der Tier für „eingefrorene“ Daten anbieten werden, ist beispiellos: die Fähigkeit, eine fast unbegrenzte Menge von Daten „on demand“ abzufragen, und das zu Kosten, die nicht viel höher liegen als die Kosten, die zur Speicherung dieser Daten in S3 anfallen. Das Ergebnis ist ein vollautomatischer Lebenszyklus für Ihre Daten – von „heiß“ zu „warm“ zu „kalt“ und schließlich zu „eingefroren“, zu Speicherkosten, die so niedrig sind wie irgend möglich, und immer verbunden mit der Gewissheit für Sie, dass Sie die Zugriffsmöglichkeiten und die Suchgeschwindigkeit erhalten, die Sie für Ihre Arbeit brauchen.
Optimierung für ein bestmögliches Nutzungserlebnis
Das Veröffentlichen bahnbrechender neuer Funktionen ist das eine, und wir arbeiten stets daran, den Funktionsumfang für Sie zu erweitern. Aber für ein bestmögliches Nutzungserlebnis ist es auch nötig sicherzustellen, dass alles andere gut mit diesen neuen Funktionen zusammenarbeitet.
- Vereinfachte Daten-Tier-Konfiguration: Wir haben das Einrichten Ihrer Daten-Tiers und das Konfigurieren von ILM-Richtlinien mit neuen Rollen für Ihre Datenknoten wesentlich einfacher und rationeller gemacht. Die Rollen helfen dem Elastic Stack dabei, Ihre Daten im Rahmen des Index-Lifecycle-Managements automatisch einer Daten-Tier zuzuordnen.
- Asynchrone Suche: Wir haben zwar alles Erdenkliche daran gesetzt, das Durchsuchen von S3 richtig schnell zu machen, aber auch wir können nicht zaubern. Das Abfragen von in S3 gespeicherten Daten dauert einfach länger als nur ein paar Millisekunden. Und wenn das schon so ist, möchten wir für ein möglichst optimales Nutzungserlebnis sorgen und haben daher einen asynchronen Suchmechanismus für Elasticsearch entwickelt. Dieser Mechanismus ermöglicht es Nutzern in Kibana, asynchron eine Suchanfrage zu stellen, ohne auf die Ergebnisse warten zu müssen. Die Nutzer können den Fortschritt der Abfrage im Auge behalten und die Ergebnisse dann herzuholen, wenn sie vorliegen. Es ist sogar möglich, Teilergebnisse abzurufen, während die Suche noch läuft.
- Abfrageeffizienz: Wir haben eine Reihe von Verbesserungen eingeführt, die dafür sorgen, dass das Durchsuchen unpassender oder für die Suche nicht benötigter Indizes übersprungen wird. So werden zum Beispiel automatisch Indizes übersprungen, von denen wir wissen, dass es keine Übereinstimmungen gibt. Möglich wird dies durch vorab eingesetzte Filter auf der Basis der Zeit oder anderer Eigenschaften in den Daten. Außerdem werden Suchen nach Möglichkeit nicht komplett durchgezogen. Bei Textsuchen kommt dazu Block-max WAND zum Einsatz, und wir arbeiten mit sortierten Abfragen, wobei die zu durchsuchenden Shards sortiert werden, sodass die Suche gestoppt wird, wenn es genügend Treffer gibt. Das sind nur einige der vielen Verbesserungen.
Jede dieser Verbesserungen ist für sich genommen ein großer Vorteil, aber die Gesamtheit all dieser Verbesserungen ist mehr als nur die Summe ihrer Einzelteile. Beim Entwickeln von Funktionen behalten wir ständig das Große und Ganze im Blick und sorgen dafür, dass die neuen Funktionen nahtlos mit dem zusammenarbeiten, was es im Elastic Stack bereits alles gibt.
Anwendungsfälle und unsere Lösungen
Stellen Sie sich nur einmal vor, welche Vorteile es bringen würde, wenn Sie einfach und kostengünstig ganze Jahresbestände an Logdaten, Metriken und APM-Traces in Objektspeichern wie S3 durchsuchen könnten – adieu, Datenrehydrierung! Durchsuchbare Snapshots und Elastic Observability ermöglichen genau das. Sie können direkt archivierte Daten aus vielen Jahren abfragen, ohne zuvor zeit- und kostenaufwendig Indizes aus Snapshots wiederherstellen zu müssen.
Wie wäre es, wenn Sie Threat-Huntern und Analysten Zugang zu ganzen Jahresbeständen an Daten geben könnten, die in Objektspeichern wie S3 archiviert sind? Mit durchsuchbaren Snapshots und Elastic Security ist dies kein Problem. Sie können viel mehr Security-Daten, wie IDS-, NetFlow-, DNS-, PCAP- oder Endpoint-Daten, erfassen und sie länger zugänglich halten, als dies bisher praktisch umsetzbar war. Möglich wird das Ganze durch neue Daten-Tiers, die die Kosten reduzieren, ohne dass dies zu Lasten der Durchsuchbarkeit geht.
Und schließlich noch: Was, wenn Sie in der Lage wären, ohne großen finanziellen Aufwand Ihre gesamten Anwendungsinhalte sowie Ihre historischen Arbeitsplatz-Datensätze zu durchsuchen? Auch das ist dank durchsuchbarer Snapshots, die in Objektspeichern gespeichert werden, problemlos möglich. Elastic Enterprise Search wird ebenfalls von den neuen durchsuchbaren Snapshots profitieren, die jetzt im Elastic Stack zur Verfügung stehen. Ob Sie zusätzliche Mengen an Anwendungsinhalten unterstützen oder in historischen Unternehmensdatensätzen suchen können müssen, die sicher in Objektspeichern wie S3 gespeichert werden können – mit durchsuchbaren Snapshots wird das Speichern sämtlicher archivierter und historischer Inhalte in einem durchsuchbaren Format erschwinglich.
Die Reise geht weiter
Wir sind stolz auf die großen Schritte, die wir mit der Veröffentlichung der Beta-Versionen der Funktion „Durchsuchbare Snapshots“ und der Tier für „kalte“ Daten in 7.10 gemacht haben. Und wir sind gespannt auf das, was vor uns liegt: die bevorstehende Einführung einer Tier für „eingefrorene“ Daten sowie die Einführung verwalteter Tiers für „kalte“ und „eingefrorene“ Daten mit einfachen Schiebereglern in Elastic Cloud, mit denen der Anmelde- und Abonnement-Prozess für Nutzer deutlich einfacher gestaltet werden wird. Wie immer ist die Reise für uns niemals zu Ende, denn wir möchten Ihnen mit jeder Version zusätzliche Funktionen und Verbesserungen bereitstellen.

Jetzt loslegen
Wenn Sie mit der Arbeit mit durchsuchbaren Snapshots und dem Speichern von Daten in der Tier für „kalte“ Daten loslegen möchten, richten Sie in Elasticsearch Service einen Cluster ein oder installieren Sie die neueste Version des Elastic Stack. Sollte Elasticsearch bereits bei Ihnen laufen, upgraden Sie Ihre Cluster einfach auf 7.10 und probieren Sie die neuen Funktionen aus. Wenn Sie mehr erfahren möchten, empfehlen wir Ihnen, die Dokumentationen zu Daten-Tiers und zur Funktion „Durchsuchbare Snapshots“ zu lesen.