Elasticsearch allows you to index data quickly and in a flexible manner. Try it free in the cloud or run it locally to see how easy indexing can be.
This is the third installment in a multi-part blog series exploring different options for ingesting data from AWS S3 into Elastic Cloud. Check out the other parts of the series:
In this blog, we will learn about how to ingest data from AWS S3 using the Elastic S3 Native connector. Elastic Native connectors are available directly within your Elastic Cloud environment. Customers have the option to use self-managed connector clients that provide the highest degree of customization options and flexibility.
Note 1: See the comparison between the options in Part 1 : Elastic Serverless Forwarder.
Note 2: An Elastic Cloud deployment is a prerequisite to follow along the steps described below.
Elastic Cloud
Check the Part 1 of the blog series on how to get started with Elastic Cloud.
Elastic S3 Native Connector
This option for ingesting S3 data is quite different from the earlier ones in terms of use case. This time we will use Elastic S3 Native Connector which is available in Elastic Cloud.
Connectors sync data from data sources and create searchable, read only replicas of the data source. They ingest the data and transform them into Elasticsearch documents.
The Elastic S3 Native Connector is a good option to ingest data suitable for content search. For example, you can sync your company's private data (such as internal knowledge data and other files) in S3 buckets and perform a text-based search or can perform vector/semantic search through the use of large language models (LLMs).
S3 connectors may not be a suitable option for ingesting Observability data such as logs & metrics as its main use case is ingesting content.
Features
- Native connectors are available by default in Elastic Cloud and customers can use self-managed connectors too if they need further customization.
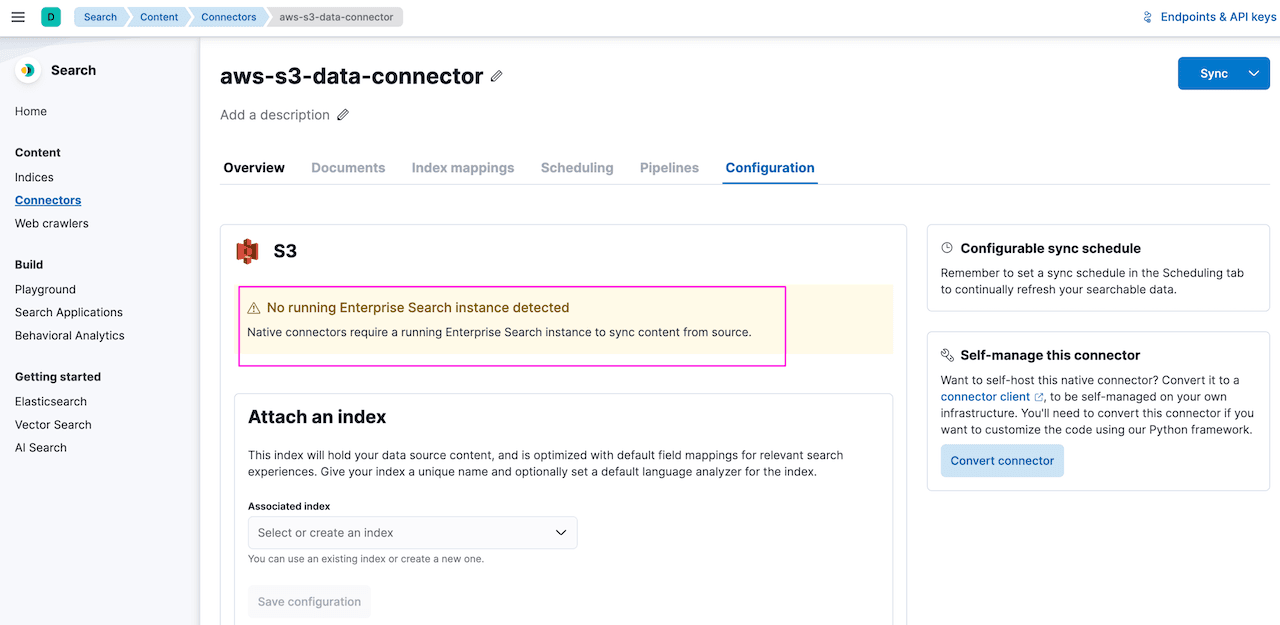
- Currently an Enterprise Search node (at least 1) must be configured in your cluster to use connectors.
- Basic & advanced sync rules are available for data filtering at source, such as specific bucket prefix.
- Synced data is always stored in content tier which is used for search related use cases.
- The connector offers default and custom options for data filtering, extracting and transforming content.
- Connector connection is a public egress (outbound) from Elastic Cloud and using Elastic Traffic Filter has no impact as Elastic Traffic Filter (Private Link) connection is is a one-way private egress from AWS. This means that data transfer will be over the public network (HTTPS) and Connector connection is independent of the traffic filter use.
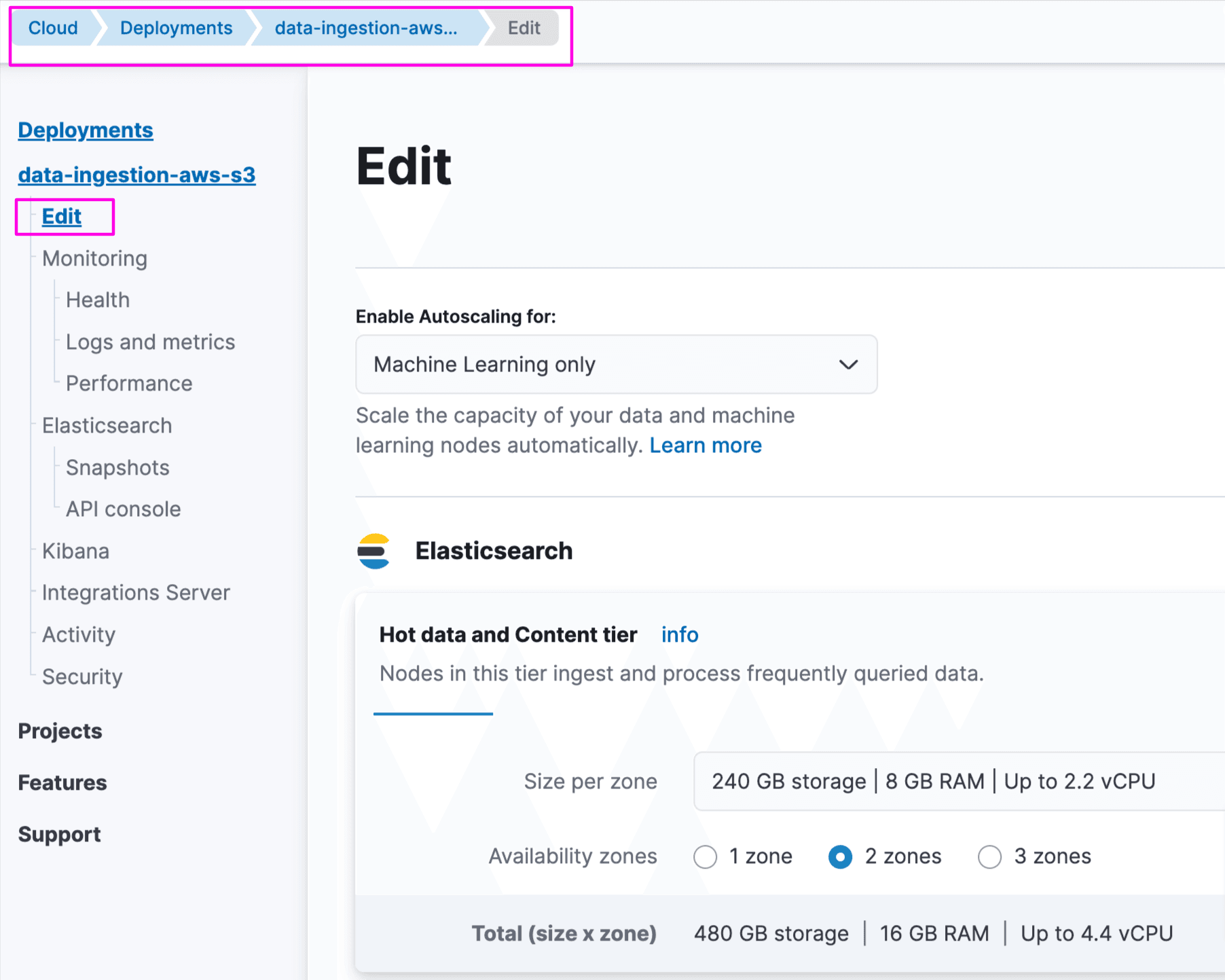
- Connector scaling depends on the volume of data ingested from the source. The Enterprise Search node sizing depends on Elasticsearch sizing as well, and it is recommended to reach out to Elastic for large-scale data ingestion. Generally, a 2GB–4GB RAM size for Enterprise Search is sufficient for light to medium use cases.
- Cost will be for object storage in S3 only. There is no data transfer cost from S3 buckets to Elasticsearch when they are within the same AWS Region. There will be some data transfer cost for cross-region data sync i.e S3 bucket and Elasticsearch deployment are in different region. More on AWS Data transfer pricing here.
Data flow of Elastic S3 Connector
The Elastic S3 Connector syncs data between the S3 bucket and Elasticsearch, as per the below high level flow:

- Elastic S3 Connector is configured with S3 bucket information and credentials with the necessary permissions to connect to the bucket and sync data.
- Based on the sync rules, the connector will pull the data from the specified bucket(s).
- Ingest pipelines perform data parsing and filtering before indexing. When you create a connector,
ent-search-generic-ingestionpipeline is available by default which performs most of the common data processing tasks. - Custom ingest pipelines can be defined too for transforming data as needed.
- Connection is over public (HTTPS) network to AWS S3.
Note 1: Content larger than 10MB will not be synced. If you are using self-managed connectors, you can use the self-managed local extraction service to handle larger binary files.
Note 2: Original permissions at the S3-bucket level are not synced and all indexed documents are visible to the user with Elastic deployment access. Customers can manage documents permissions at Elastic using Role based access control, Document level security & Field level security
More information on Connector architecture is available here.
Set up Elastic S3 Native Connector
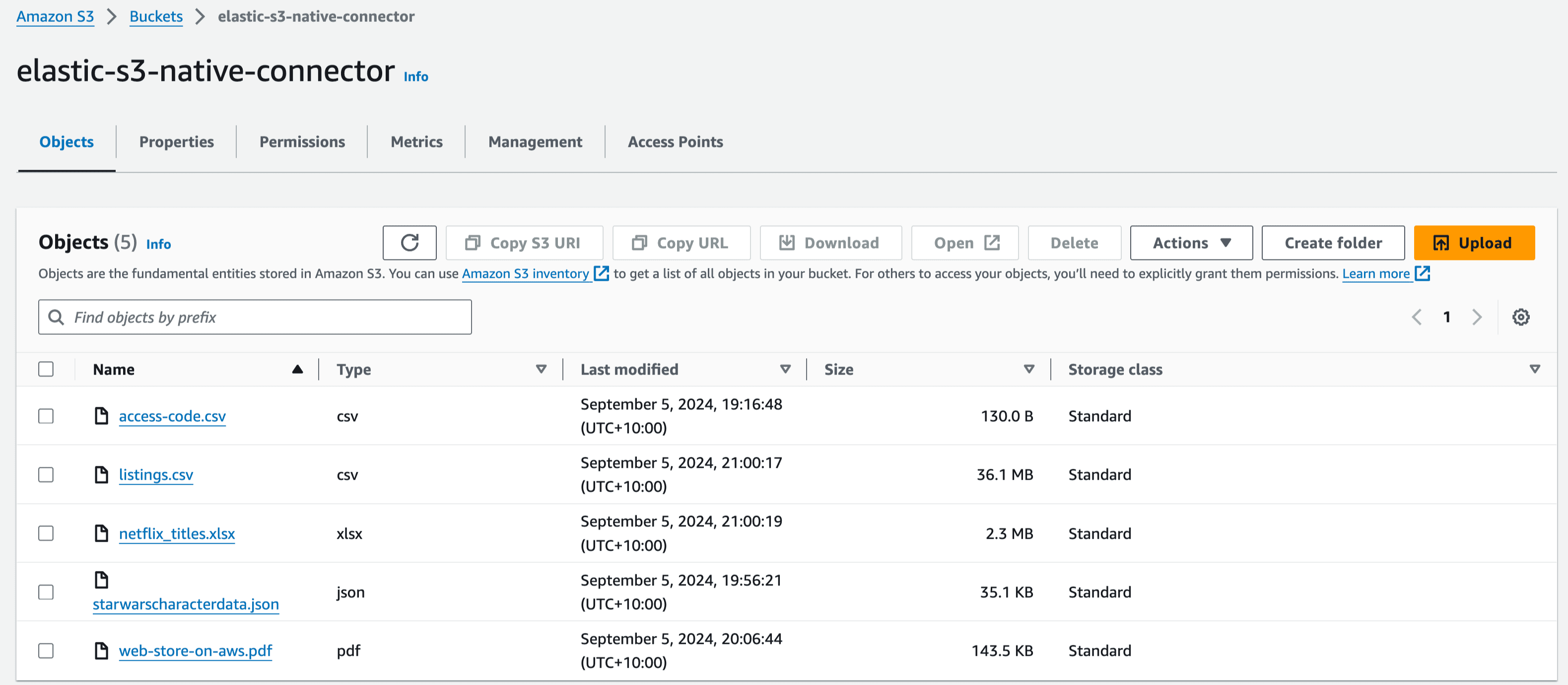
1. Create the S3 bucket, here named elastic-s3-native-connector:
AWS Console -> S3 -> Create bucket. You may leave other settings as default or change as per the requirements.
This bucket will store data to be synced to Elastic. The connector supports a variety of file types. For the purpose of ingestion testing we will upload a few pdf and text files.
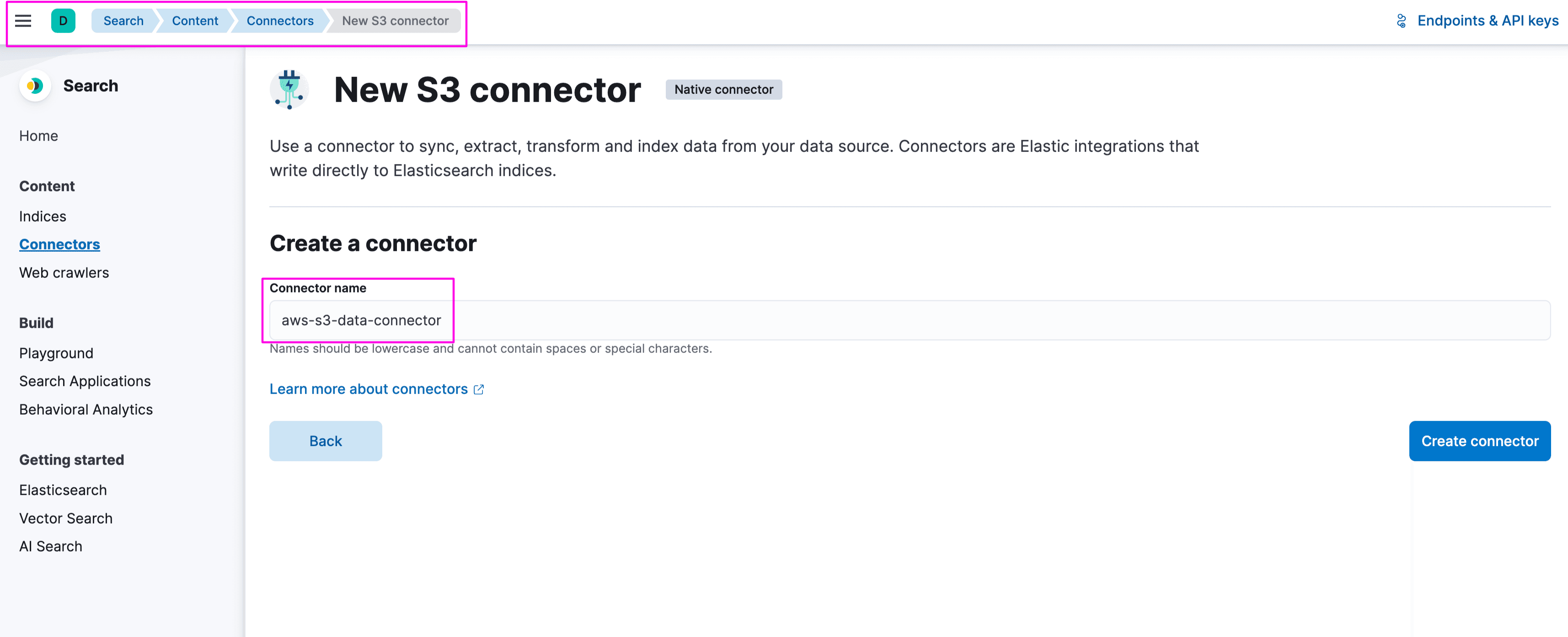
2. Login to Kibana and navigate to Search-> Content -> Connectors. Search for S3 connector. Provide a name for connector, we have given aws-s3-data-connector:
The Connector will show a warning message if there is no Enterprise Search node detected, similar to the below:
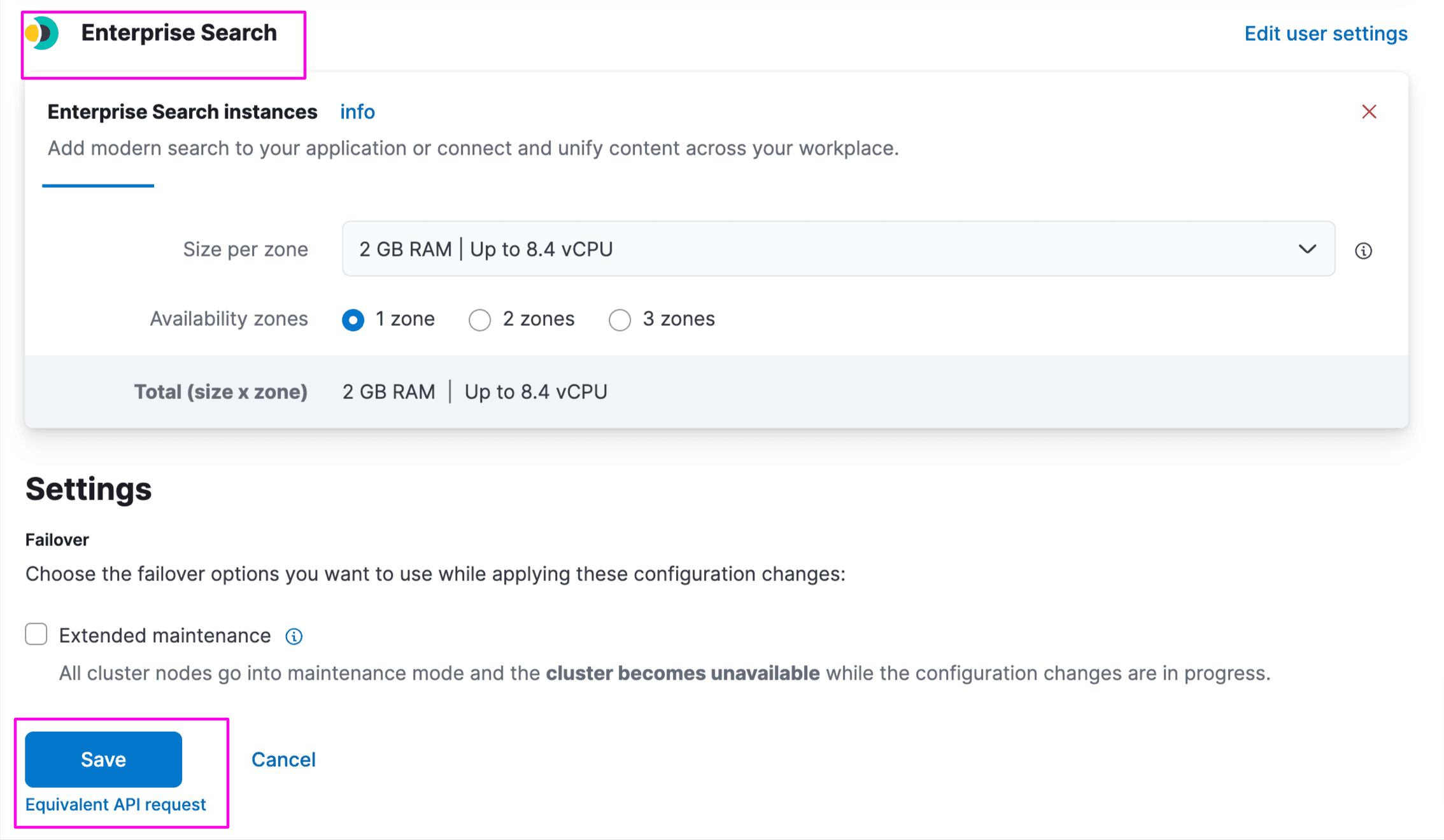
Login to Elastic Cloud Console and edit your deployment. Under Enterprise Search, select the node size and zones and save:
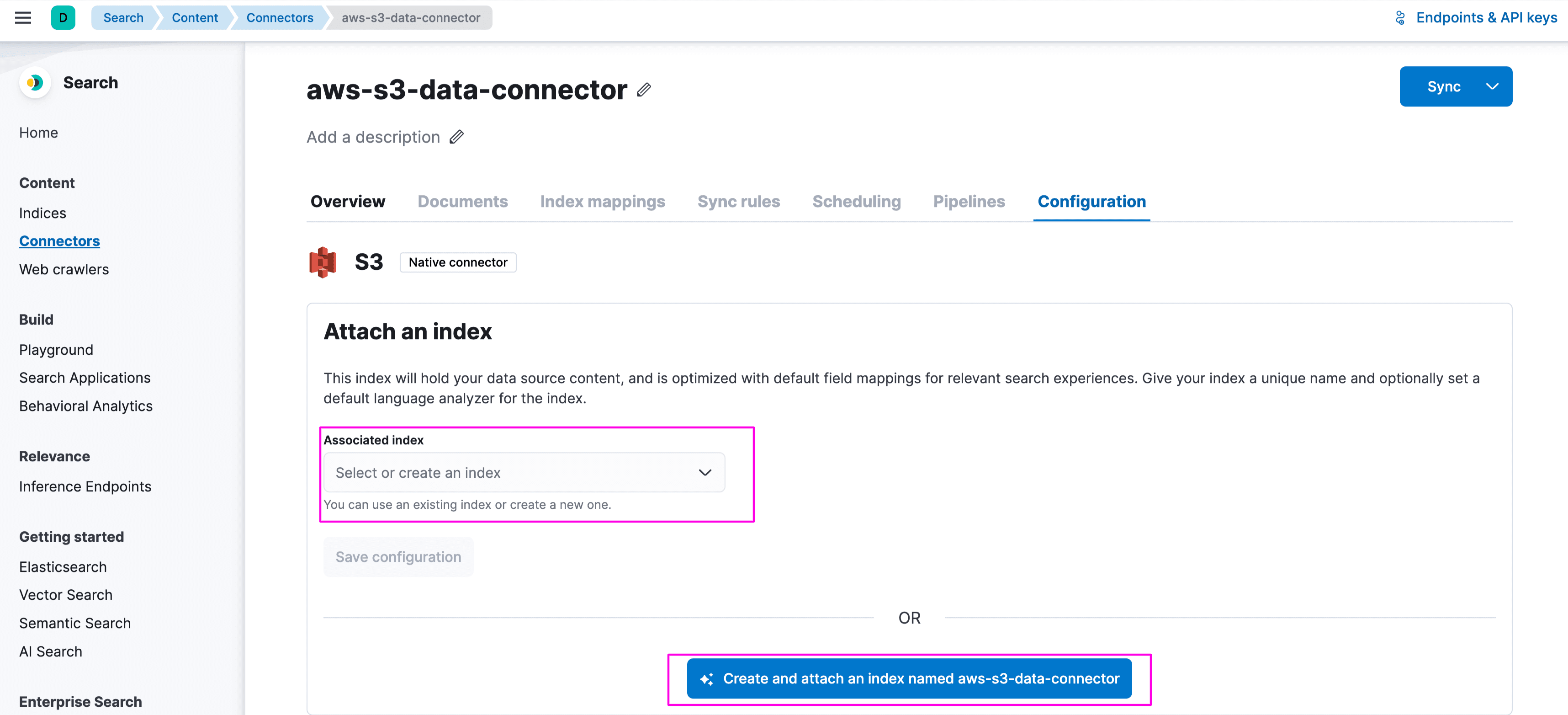
You can provide a different index name or the same as connector name. We are using the same index name:
Provide AWS credentials and bucket details for elastic-s3-native-connector:
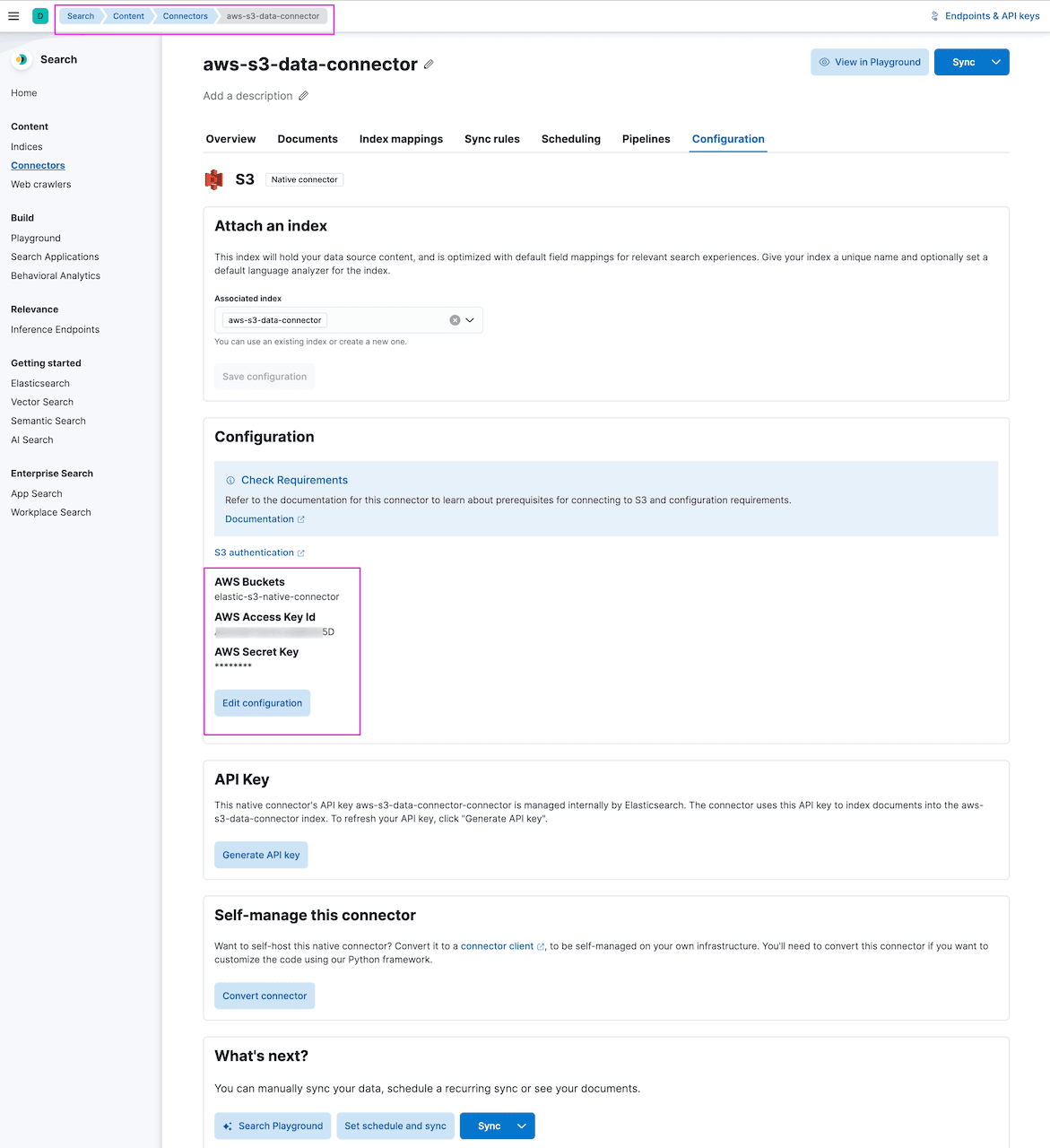
When you update the configuration, the connector can display a validation error if there is some delay in updating AWS credentials and bucket names. You can provide the required information and ignore the error banner. This is a known thing as connectors communicate asynchronously with Kibana and for any configuration update there is some delay in communication between the connector and Kibana. The error will go away once the sync starts or a refresh starts after some time:

3. Once configuration is done successfully, click on the "Sync" button to perform the initial full content sync.
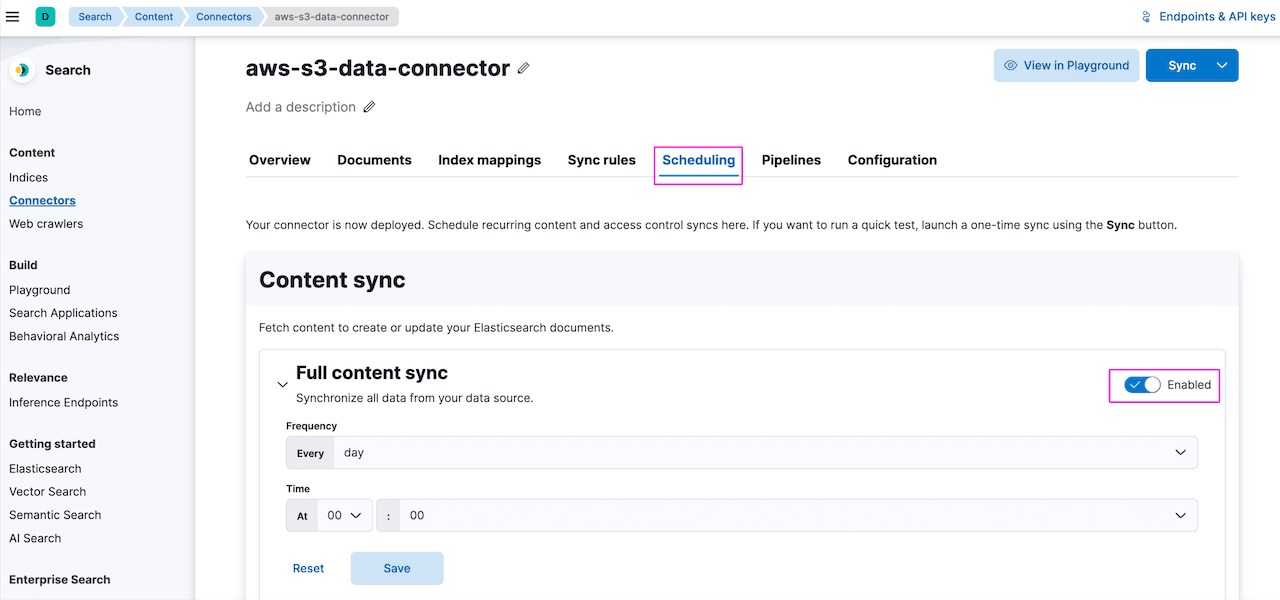
For a recurring sync, configure the sync frequency under the Scheduling tab. It is disabled by default, so you'll need to toggle the "Enable" button to enable it. Once scheduling is done, the connector will run at the configured time and pull all the content from the S3 bucket. Elastic Native Connector can only sync files of size 10MB and less. Any files more than 10MB of size will be ignored and will not be synced. You either have to chunk the files accordingly or use a self-managed connector to customize the behavior:
Search after AWS S3 data ingestion
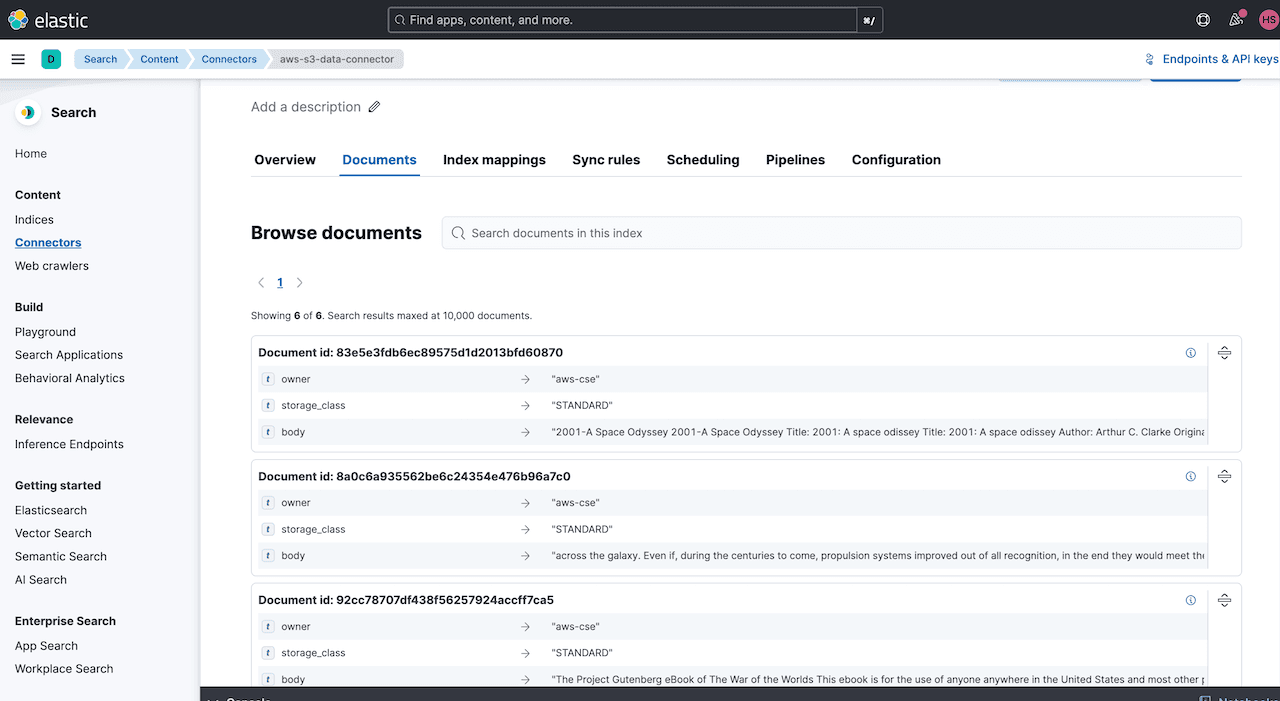
Once the data is ingested, you can validate directly from the connector under Documents tab:
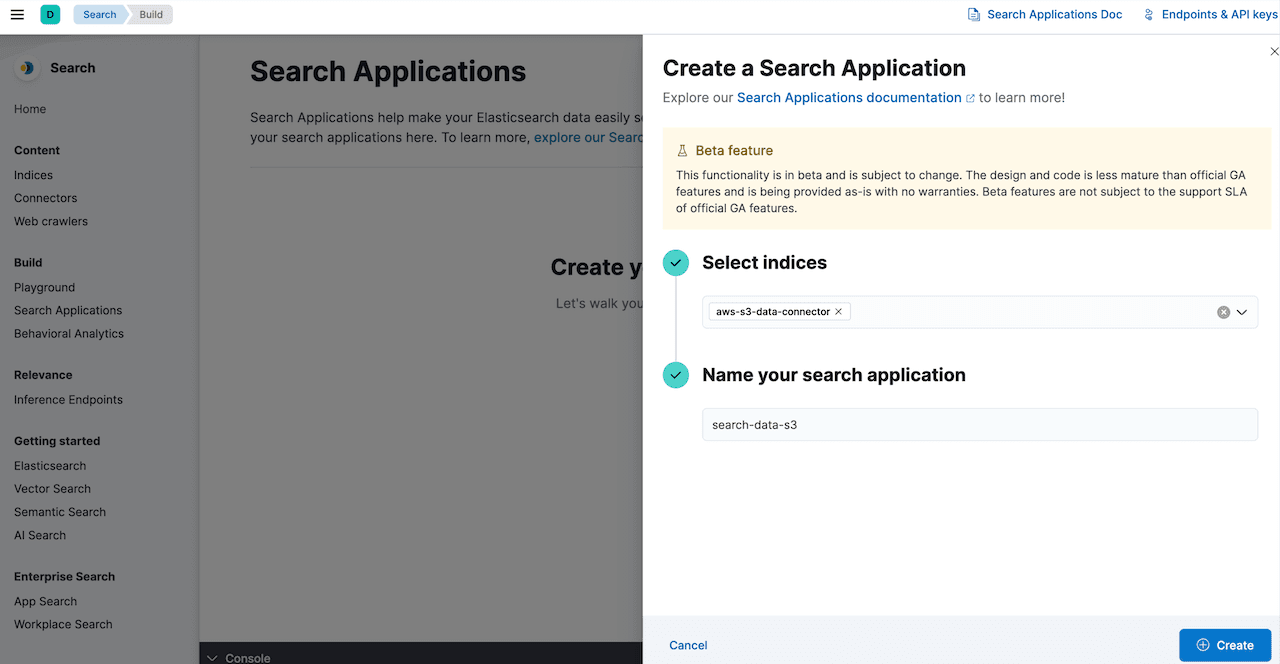
Also, Elasticsearch provides Search applications feature which enable users to build search-powered applications. You can create search applications based on your Elasticsearch indices, build queries using search templates, and easily preview your results directly in the Kibana Search UI.
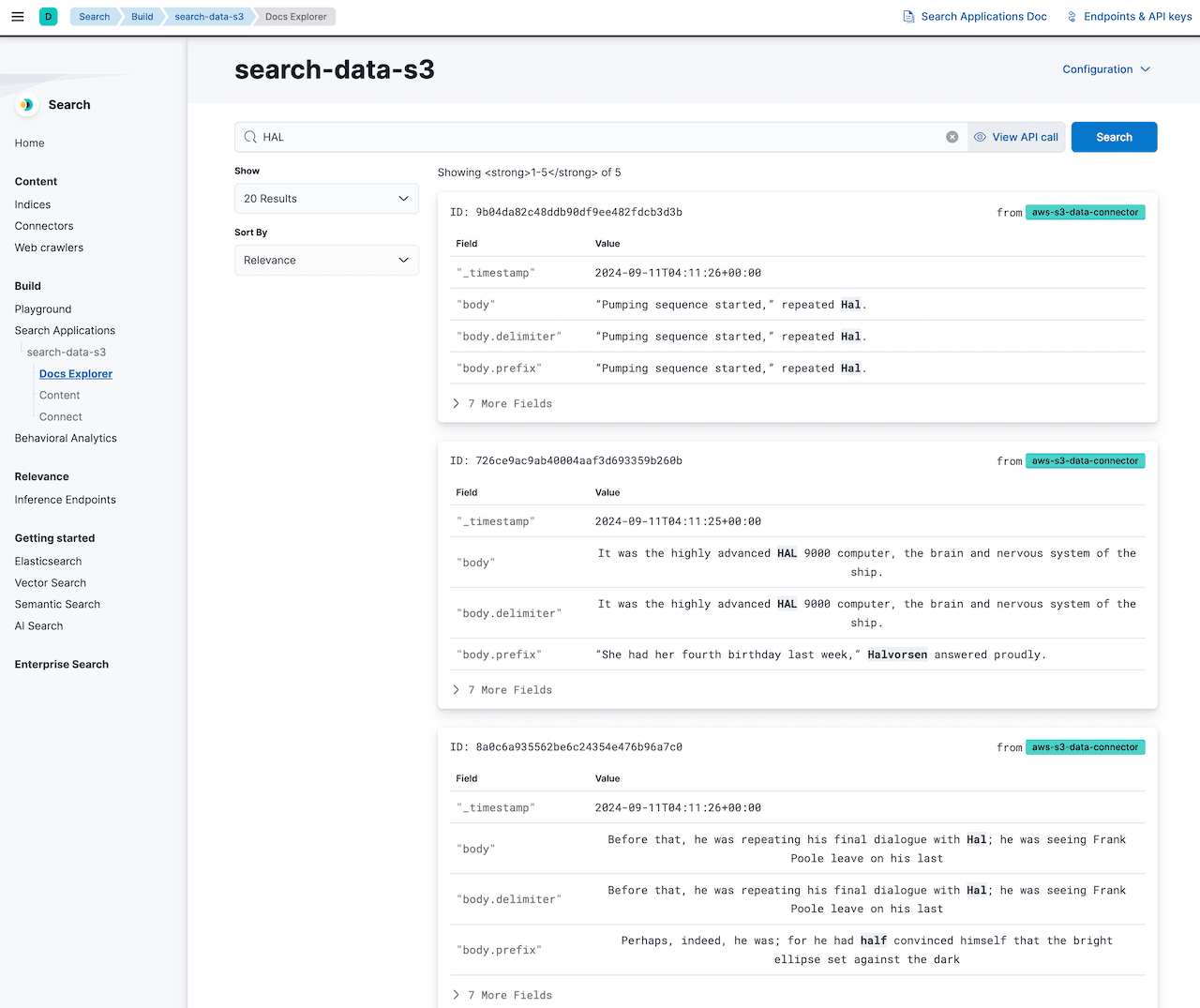
Enhance the search experience of AWS S3 ingested data with Playground
Elastic provides Playground functionality to implement Retrieval Augmented Generation(RAG) based question answering with LLM to enhance the search experience on the ingested data.
In our case, once the data is ingested from S3, you can configure Playground and use its chat interface, which takes your questions, retrieves the most relevant results from your Elasticsearch documents, and passes those documents to the LLM to generate tailored responses.
Check out this great blog post from Han Xiang Choong showcasing the Playground feature using S3 data ingestion.
Conclusion
In this blog series, we have seen 3 different options Elasticsearch provides to sync and ingest data from AWS S3 into Elasticsearch deployments. Depending on the use case and requirements, customers can choose the best option for them and ingest data via Elastic Serverless Forwarder, Elastic Agent or the S3 Connector.
Frequently Asked Questions
What is the Elastic S3 Connector?
The Elastic S3 Connector syncs data between the S3 bucket and Elasticsearch. it is available in Elastic Cloud.
Related Content

December 16, 2025
Reducing Elasticsearch frozen tier costs with Deepfreeze S3 Glacier archival
Learn how to leverage Deepfreeze in Elasticsearch to automate searchable snapshot repository rotation, retaining historical data and aging it into lower cost S3 Glacier tiers after index deletion.

September 22, 2025
Elastic Open Web Crawler as a code
Learn how to use GitHub Actions to manage Elastic Open Crawler configurations, so every time we push changes to the repository, the changes are automatically applied to the deployed instance of the crawler.

August 6, 2025
How to display fields of an Elasticsearch index
Learn how to display fields of an Elasticsearch index using the _mapping and _search APIs, sub-fields, synthetic _source, and runtime fields.

July 14, 2025
Run Elastic Open Crawler in Windows with Docker
Learn how to use Docker to get Open Crawler working in a Windows environment.

June 24, 2025
Ruby scripting in Logstash
Learn about the Logstash Ruby filter plugin for advanced data transformation in your Logstash pipeline.