Elasticsearch allows you to index data quickly and in a flexible manner. Try it free in the cloud or run it locally to see how easy indexing can be.
Elastic Connectors overview
Elastic Connectors are a type of Elastic integrations that sync data from an original data source to an Elasticsearch index. Connectors enable you to create searchable, read-only replicas of your data sources.
There are a number of connectors that are supported for variety of 3rd-parties, such as:
- MongoDB
- Various SQL DBMS such as MySQL, PostgreSQL, MSSQL and OracleDB
- Sharepoint Online
- Amazon S3
- And many more. The full list is available here.
Connectors content synchronization jobs
Connectors support two types of content synchronization jobs: full syncs and incremental syncs.
1. Full syncs
Full sync is a sync that extracts all desired documents from a 3rd-party service and ingests them into Elasticsearch. So if you've set up your Network Drive connector to ingest all documents from a folder "\Documents/Reports\2022**.docx", during a full sync the connector will fetch all the documents that match this criteria and send all of them to Elasticsearch. Simplified pseudocode for this would look like:
This works well until the sync starts to take too long. This could happen because the connector fetches more data than needed. For instance, why fetch old files that have not changed and send them to Elasticsearch? One could argue that the metadata for files could be unreliable, so all files need to be fetched again and sent to Elasticsearch. Indeed, that could be the case, but if we can trust the metadata of the data fetched from 3rd-party, we can ingest less data. Incremental sync is the way to do so.
2. Incremental syncs
Most of the time, if written well, connector spends doing IO operations. Returning to the example code there are 3 places where IO happens:
Each of these places can become a bottleneck and take a significant amount of time during the sync.
Here's where incremental sync comes into play. Its purpose is to decrease the amount of IO on any of the stages, if possible.
Potential optimizations for incremental sync
Fetch fewer documents from 3rd-party systems
Modifying the example above, the code could look like this:
In cases where only a small number of documents change in our 3rd-party system, we can speed up the ingestion process significantly. However, for Network Drive it's not possible - its API does not support filtering documents by metadata. We won't be able to avoid scanning through the full content of Network Drive.
Skip download of content of files that haven't changed since previous sync
Downloading file content takes a significant amount of time in the syncs. If files are reasonably large, the connection is unstable or throughput is low, downloading the content of files would take most of the time when syncing the content from the 3rd-party. If we skip downloading some of them, it can already significantly speed up the connector.
Consider the following example pseudocode:
If no documents were updated, the sync will actually be magnitudes faster than fully syncing the content.
Skip ingestion of non-modified documents into Elasticsearch
While it may seem minor, ingestion of data into Elasticsearch takes a significant amount of time - albeit normally less than downloading the content from the 3rd-party system. We can start storing timestamps per each document and not send the documents into Elasticsearch if their timestamp did not change.
We can combine this approach with the previous approach to save the most time possible during the sync.
This approach helps save even more time when running a sync. Now let's take a look into performance considerations for such improvements.
Measuring incremental sync performance
Now since we've taken a look into simplified code that shows how incremental syncs can work, we can try to estimate potential performance improvements.
For some connectors, incremental sync is implemented in a certain manner that optimizes the way data is fetched from a 3rd-party. For example, the Sharepoint Online connector fetches some data via delta API - only collecting documents that changed after the last sync. This improves performance in an obvious manner - less data -> less time to sync the data to latest.
For other connectors (currently all connectors except Sharepoint Online connector) incremental sync is done by framework in a generic way which was described in one of previous sections "Skip ingestion of non-modified documents into Elasticsearch".
Connectors still collect all the data from 3rd-party data source (as it does not provide a way to fetch only the changed records). However if this data contains timestamps, the connector framework compares document IDs and timestamps of already ingested documents with incoming documents. If the document exists in Elasticsearch with the same timestamp that was received from the 3rd-party data source, then this document will not be sent to Elasticsearch.
We've described abstract approach for the performance improvements with incremental syncs, but we already have these implemented in connectors, so let's dive into real numbers!
Performance tests
We will estimate the rough magnitude of improvement for incremental syncs with these performance tests, not aiming at high precision.
The two connectors chosen for this test, Google Drive and Github, were chosen because they have different IO profiles.
Google Drive acts like a file storage. It:
- Has a fast API that does not throttle too soon
- Normally stores a lot of binary content of variable size - from small to really large
- Normally stores a small number of records - tens or hundreds of thousands rather than millions
GitHub data is ingested via a more of a classic API, that:
- Throttles quite often
- Contains many records that are much smaller than those in Google Drive
- Does not send binary content at all
Due to these differences, the incremental sync performance will majorly differ.
Both tests will contain these mandatory steps:
- Do a full sync against a 3rd-party system
- Modify some documents on the 3rd-party system
- Run an incremental sync and check the amount of time it takes
This setup is very bare bones but will already give a good indication of the magnitude of performance improvement. Both tests will be slightly different and I will provide results with commentary in the next section.
Setup #1 - Google Drive Connector
Initial setup will be:
- 1 folder is on Google Drive with 1553 files (100 of them are 2MB in size, 1443 are 5KB in size)
- A full sync is executed and this data gets into Elasticsearch
- More files are added into Google Drive to make it 10144 files (100 of them are 2MB in size, all the rest are 5KB in size)
- Incremental sync is executed again to pull the new data
- Then some minor changes are made to files on Google Drive (1 added, 2 deleted)
- Incremental sync is executed again
- Full sync is executed to compare the run time against incremental sync again
The following table contains the results of the described test with commentary:
| Sync Description | Run time | Documents Added | Documents Deleted | Comment |
|---|---|---|---|---|
| Initial Full Sync | 0h 4m 0s | 1553 | 0 | This is initial sync - it pulls all documents |
| Incremental Sync after more data was added to Google Drive | 0h 20m 9s | 7939 | 0 | Run time was high as expected - a lot of documents went in |
| Incremental Sync after some data was slightly changed in Google Drive | 0h 1m 25s | 1 | 2 | Run was very fast. It still called Google Drive API a lot, but did not have to ingest 200+MB of data into Elasticsearch |
| Full Sync to compare performance | 0h 23m 23s | 10144 | 0 | As expected, it takes a lot of time - all the data is downloaded from Google Drive and is sent to Elasticsearch, even if it did not change. We can assume that it takes 22 minutes to download and then upload the data into Elasticsearch for the setup |
In summary, incremental sync significantly improved the performance of the connector because most of the time is spent on the connector downloading the content of the files and sending this content to Elasticsearch. Full sync brings 2 * 100 + 1443 * 5 / 1024 = 207MB of content - both downloaded by connector and ingested into Elasticsearch. If only 1 large file is changed, this amount changes to only 2MB - a magnitude of 100 change. This explains the performance improvement well.
Setup #2: GitHub connector
The GitHub connector is very different since the actual volume of data it syncs is relatively small - issues, pull requests and such are reasonably small, while there are lots of them. Additionally, GitHub has strict throttling policies and throttles connector a lot.
To give a good real-world example we’ll use the Kibana Github repository with the GitHub connector and observe its performance.
| Sync Description | Run time | Documents Added | Documents Deleted | Comment |
|---|---|---|---|---|
| Initial Full Sync | 8h 40m 1s | 147421 | 0 | --- |
| Incremental Sync ran immediately after | 9h 6m 7s | 59 | 0 | This sync took even more time to run, mostly because it was constantly throttled. Connector had to fetch all the data from GitHub but sent only 59 records with a total volume of less than 1MB |
| Next incremental sync | 9h 2m 52s | 191 | 1 | This sync was triggered immediately after previous incremental sync finished. Run time is the same due to data being almost the same and throttling being a major factor in the connector run time |
Key takeaways
- As you can see, there is no performance improvement for incremental sync for the Github connector - there is barely any space for optimization as most of the time is spent by the connector querying the system and waiting for the throttling to stop.
- Documents that are extracted are reasonably small, so network throughput usage is minimal. To improve the connector run time, the incremental sync would actually have to limit the number of queries to Github, but at this point it's not implemented in the connector.
Summary
What is the primary factor that impacts the performance of incremental sync? In simplified terms, it's the raw volume of data that is ingested.
For Sharepoint Online connector there is a special logic to fetch less data via the delta API. This saves good amount of time because the delta API allows connectors to not fetch files that were not changed. Files tend to be large, thus not downloading and ingesting them will save a lot of time.
For other connectors, incremental sync is generic - it just checks document timestamps before ingesting them to Elasticsearch - if this document is already in the index and the timestamp did not change, then it is not ingested. It saves less time than the previous approach that Sharepoint Online employs but works generically for all connectors. Some connectors - ones that contain large documents - benefit from this logic a lot, while others - that get throttled by a 3rd-party system and contain relatively small documents - get no benefit from incremental syncs.
Additionally, if Elasticsearch is under heavy load, incremental sync is less likely to be throttled by Elasticsearch, thus making it more performant under load.
Let's look at the following graph:
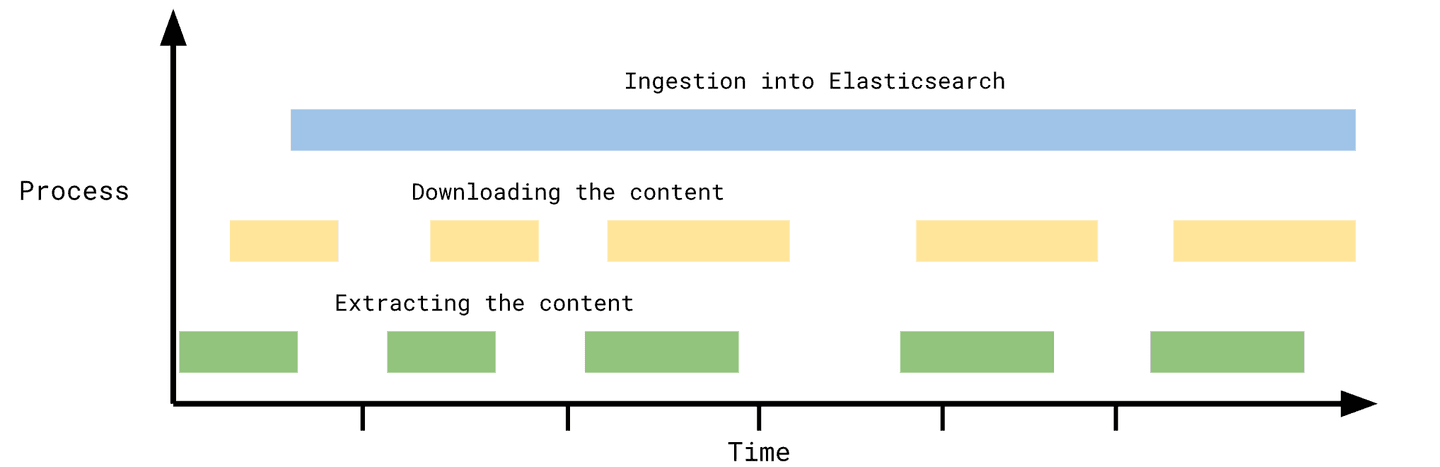
In the graph you can see how much time each part of content extraction and ingestion takes on the timeline. In the example above the connector is spending the most time on ingesting the data, even pausing for extraction and content download. In this case incremental sync has a potential of improving the run time of the sync by 30-40%.
Let's look at another example - a system that has throttling and low throughput, but stores very little data in Elasticsearch (Sharepoint Online, GitHub, Jira, Confluence):
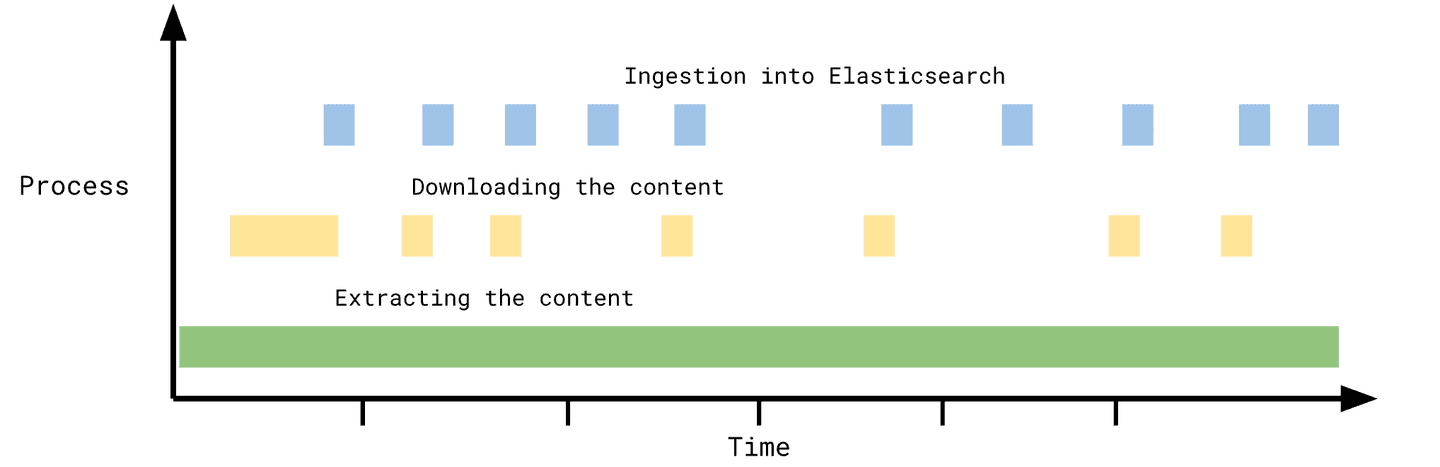
This system will not benefit from generic incremental syncs a lot - most of the time is spent extracting content from the 3rd-party system.
And the last example - fast and accessible system that stores huge amounts of data in Elasticsearch (Google Drive, Box, OneDrive, Network Drive):
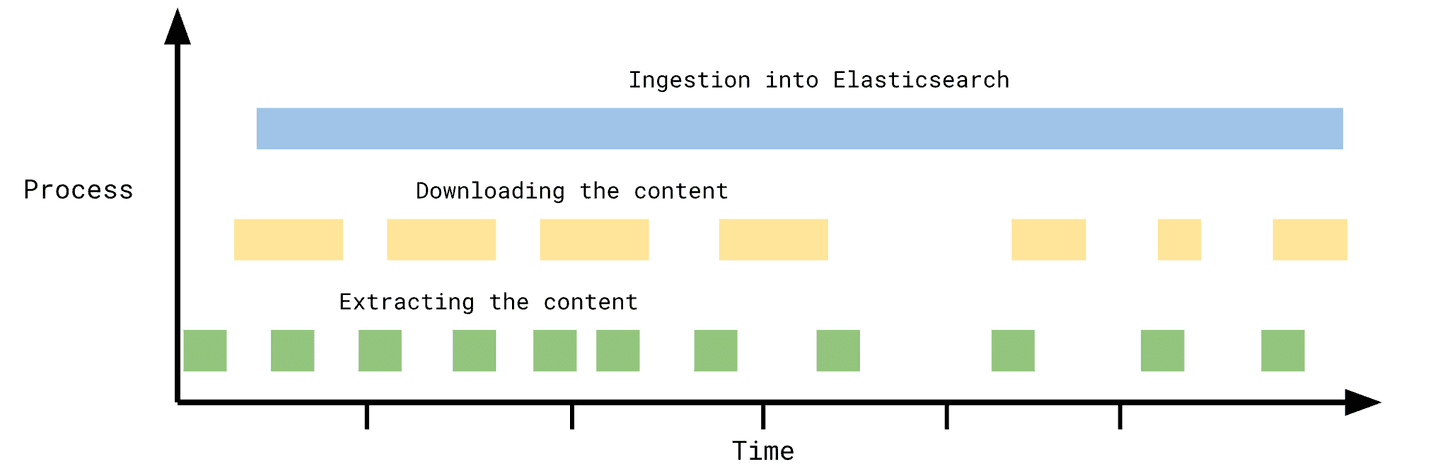
If there aren't too many items that change in such a system between syncs, this system will benefit a lot from generic incremental syncs.
Currently connectors that potentially get the most of incremental sync are:
- Azure Blob Storage
- Box
- Dropbox
- Google Cloud Storage
- Google Drive
- Network Drive
- OneDrive
- S3
- Sharepoint Online
Other connectors will benefit less from incremental syncs, or will not benefit at all, but there's no one-size-fits-all answer here. Performance heavily depends on the profile of data ingested. The bigger each individual document is, the bigger the benefit.
Frequently Asked Questions
What are Elastic Connectors?
Elastic Connectors are a type of Elastic integrations that sync data from an original data source to an Elasticsearch index. Connectors enable you to create searchable, read-only replicas of your data sources.
Related Content

December 16, 2025
Reducing Elasticsearch frozen tier costs with Deepfreeze S3 Glacier archival
Learn how to leverage Deepfreeze in Elasticsearch to automate searchable snapshot repository rotation, retaining historical data and aging it into lower cost S3 Glacier tiers after index deletion.

September 22, 2025
Elastic Open Web Crawler as a code
Learn how to use GitHub Actions to manage Elastic Open Crawler configurations, so every time we push changes to the repository, the changes are automatically applied to the deployed instance of the crawler.

August 6, 2025
How to display fields of an Elasticsearch index
Learn how to display fields of an Elasticsearch index using the _mapping and _search APIs, sub-fields, synthetic _source, and runtime fields.

July 14, 2025
Run Elastic Open Crawler in Windows with Docker
Learn how to use Docker to get Open Crawler working in a Windows environment.

June 24, 2025
Ruby scripting in Logstash
Learn about the Logstash Ruby filter plugin for advanced data transformation in your Logstash pipeline.