Elasticsearch is packed with new features to help you build the best search solutions for your use case. Learn how to put them into action in our hands-on webinar on building a modern Search AI experience. You can also start a free cloud trial or try Elastic on your local machine now.
We’ve discussed both hybrid search (Part I) and context engineering, (Part II); now, let’s dive into how they work together for the greatest effect in supplying targeted context to RAG and agentic AI operations.
Search isn’t dead, it’s just moved
So we’ve had this shift from primarily searching for context through a text box and using the information (the context) returned to construct the answers ourselves, to now using natural language to tell an agent what we want and letting it automatically research and compile the answer for us. Many in the tech world are pointing to this shift and proclaiming “search is dead” (well, the SEO and ad-words world is definitely changing: GEO anyone?), but search is still absolutely critical to agentic operations — it’s just largely performed out of sight via tools now.
Previously, humans were the main arbiters of subjective relevance: each user has their own reasons for running the search, and their personal experience colors the relative accuracy of the results. If we are to trust that agents can come to the same conclusion (or better) that we would have, we need to ensure the contextual information they have access to is as close to our subjective intent as possible. We have to engineer the context we provide LLMs towards that goal!
Generating context with hybrid search retrieval
Just a reminder from way back in Part I that Elastic’s hybrid search combines the strengths of traditional keyword-based search (syntax flexibility, keyword precision, and relevance scoring) with the semantic understanding of vector similarity search, and offers multiple reranking techniques. This synergy (a truer usage of that word has never been found!) allows for highly relevant results, with queries that can be much more nuanced in how they target content. It’s not just that you can apply subjective relevance as one of your retrieval stages; it’s really that the first-stage retrieval can include relevance scoring along with all of those other modes at once.
Superior accuracy & efficiency
Using a data platform that can provide distributed search, retrieval, and reranking as your primary context retrieval engine makes a lot of sense. You’re able to use advanced query syntax to add the missing component of subjective intent, and filter out content that might distract from or muddy the value of the contextual information returned. You can select from any of the individual syntax options available, or combine modalities into a single search that targets each type of data in the manner it understands best, and then combine/re-order them with reranking. You can have the response filtered to only include the fields/values you want, keeping extraneous data at bay. In service to agents, that targeting flexibility lets you build tools that are extremely accurate in how they retrieve context.
Context refinement (aggregations and non-content signals)
Aggregations can be especially useful in shaping the content a tool delivers to the context window. Aggregations naturally provide numerical-based facts about the shape of the contextual data returned, which makes it easier and more accurate for LLMs to reason over. Because aggregations can be hierarchically nested, it’s an easy way to add multi-level detail for the LLM to generate a more nuanced understanding. Aggregations can also help with managing the context window size — you can easily reduce a query result of 100k documents to a few hundred tokens of aggregated insights.
Non-content signals are the inherent indicators in your data that tell you the bigger picture of what you’re looking at; they’re the additional characteristics of the results, things like popularity, freshness, geo-location, categories, host diversity, or price bands. These bits of information can be useful for informing the agent in how it weighs the importance of the context it has received. Some simple examples might help illustrate this best:
- Boosting recently published and popular content - Imagine you have a knowledge base of articles. You want to find articles relevant to a user's query, but you also want to boost articles that are both recent and have been found helpful by other users (e.g., have a high "likes" count). In this scenario, we can use a hybrid search to find relevant articles and then rerank them based on a combination of their publication date and popularity.
- E-commerce search with sales and stock adjustment - In an e-commerce setting, you want to show customers products that match their search term, but you also want to promote products that are selling well and are in stock. You might also want to down-rank products with low stock to avoid customer frustration.
- Prioritizing high-severity issues in a bug tracker - For a software development team, when searching for issues, it's crucial to surface high-severity, high-priority, and recently updated issues first. You can use non-signals like ‘criticality’ and ‘most-discussed’ to weigh different factors independently, ensuring that the most critical and actively discussed issues rise to the top
These example queries and more can be found in the accompanying Elasticsearch Labs content page.
Security enforcement
A critical advantage of leveraging a search-powered speed layer like Elastic for context engineering is its built-in security framework. Elastic's platform ensures that context delivered to agentic and generative AI operations respects and protects sensitive privately held information through granular role-based access control (RBAC) and attribute-based access control (ABAC). This means that not only are queries handled with efficiency, but also that the results are filtered according to the specific permissions of the agent or the user initiating the request.
Agents run as the authenticated user, so security is implicitly applied through the security features built-into the platform:
- Fine-grained permissions: Define access at the document, field, or even term level, ensuring that AI agents only receive data they are authorized to see.
- Role-based access control (RBAC): Assign roles to agents or users, granting access to specific datasets or functionalities based on their defined responsibilities.
- Attribute-based access control (ABAC): Implement dynamic access policies based on attributes of the data, the user, or the environment, allowing for highly adaptable and context-aware security.
- Document-level security (DLS) and field-level security (FLS): These capabilities ensure that even within a retrieved document, only authorized portions are visible, preventing sensitive information from being exposed.
- Integration with enterprise security: Seamlessly integrate with existing identity management systems (like LDAP, SAML, OIDC) to enforce consistent security policies across the entire organization.
By integrating these security measures directly into the context retrieval mechanism, Elastic acts as a secure gatekeeper, ensuring that AI agents operate within defined data boundaries, preventing unauthorized data exposure, and maintaining compliance with data privacy regulations. This is paramount for building trust in agentic AI systems that handle confidential or proprietary information.
As an added bonus, by using a unified data speed layer over your enterprise data sources, you alleviate the unexpected ad hoc query loads on those repositories that agentic tools would create. You get a single location to search everything in near real-time, and one place to apply security and governance controls.
Hybrid search-based tools
There are some core features (with more coming all the time) of the Elastic platform that turbo boost the pursuit of context engineering. The main thing here is that the platform offers a multitude of ways to achieve things, with the flexibility to adapt, change, and expand methods as the AI ecosystem advances.
Introducing Agent Builder
Elastic Agent Builder is our first foray into the realm of agentic AI tools built to chat with the data you’re already storing in Elastic. Agent Builder offers a chat interface that enables users to create and manage their own agents and tools within Kibana. It comes with built-in MCP and A2A servers, programmatic APIs, and a set of pre-built system tools for querying and exploring Elasticsearch indices, and for generating ES|QL queries from natural language. Agent Builder allows you to create custom tools that target and sculpt the contextual data returned to the agent through expressive ES|QL query syntax.
How does ES|QL perform hybrid search, you ask? The core capability is accomplished through the combination of the semantic_text field type and the FORK/FUSE commands (FUSE uses RRF by default to merge results from each fork). Here’s a simple example for a fictitious product search:
The EVAL clause included with each of the FORK branches in the example above isn’t strictly necessary; it’s only included to demonstrate how you could track which search modality a given result was returned from.
Search templates
Let’s say you want to point your own external agentic tools to your Elastic deployment. And instead of ES|QL, you want to use multi-stage retrievers or re-use existing DSL syntax you’ve developed, and also want to be able to control the inputs the query accepts, the syntax used to execute the search, and the fields returned in the output. Search templates allow users to define predefined structures for common search patterns, improving efficiency and consistency in retrieving data. This is particularly beneficial for agentic tools interacting with search APIs, as they help standardize boilerplate code and enable faster iteration on search logic. And if you ever need to adjust any of those factors, you just update the search template and voilā the changes are implemented. If you’re looking for an example of search templates in action with agentic tools, take a look at the Elasticsearch Labs blog ‘MCP for intelligent search’, which utilizes a search template behind a tool call from an external MCP server.
Integrated workflows (FTW!)
One of the most difficult things to navigate in our new agentic AI world is the non-deterministic nature of semi-autonomous, self-directed “reasoning” agents. Context engineering is a critical discipline to agentic AI: they’re the techniques that help narrow the possible conclusions our agent can generate down to what we know of ground truth. Even with a highly accurate and relevant context window, (when we get outside the realm of numerical facts) we’re still missing that bit of reassurance that the agent’s response is fully repeatable, dependable.
When you run the same request to an agent multiple times, the answers might be essentially the same with just that little bit of difference in the response. That’s usually fine for simple queries, maybe barely noticeable, and we can try to shape the output with context engineering techniques. But as the tasks we ask of our agents become more complex, there’s more of a chance that one or more of the sub-tasks could introduce a variance that slightly changes the end-result. It’ll likely get worse as we begin to rely more on agent-to-agent communications, and those variances will become cumulative. This points again to the idea that the tools our agents interact with need to be very flexible and tuneable to precisely target contextual data, and that they should respond in an expected output format. It also indicates that for many use cases we have a need to direct agent and tool interactions — this is where workflows enter into the picture!
Elastic will soon have completely customizable workflows built into the core of the platform. These workflows will be able to operate with agents and tools in a bi-directional manner, so workflows will be able to call agents and tools, and agents and tools will be able to call workflows. Having these capabilities fully integrated into the same search AI platform where all of your data lives will be transformational, the potential of workflows is extremely exciting! Soon, coming very soon!
Elastic as the unified memory bank
By virtue of being a distributed data platform that’s made for near real-time search, Elastic naturally performs the long-term memory functions for agentic AI systems. With the built-in Agent Builder chat experience, we also have tracking and management of the short-term memory and chat history. And because the entire platform is API-first, it’s extremely easy to utilize Elastic as the platform to persist a tool’s contextual output (and to be able to refer to it later) that might overwhelm the agent’s context window; this technique is sometimes called “note-taking” in context engineering circles.
Having short-term and long-term memory both on the same search platform leads to a lot of intrinsic benefits: imagine being able to use chat histories and persisted contextual responses as part of the semantic influencers to future chat interactions, or to perform threat analytics, or to create persisted data products that are automatically generated from frequently repeated tool calls… The possibilities are endless!
Conclusion
The emergence of large language models has changed the way we’re able to match content and the methods we use to interrogate our data. We’re rapidly shifting away from our current world, where humans perform the research, contextual consideration, and logical reasoning to answer their own questions, to one where those steps are largely automated through agentic AI. In order for us to trust the generated answers we receive, we need assurance that the agent has considered all of the most relevant information (including the factor of subjective relevance) in generating its response. Our primary method for making agentic AI trustworthy is by grounding the tools that retrieve additional context through RAG and context engineering techniques, but how those tools perform the initial retrieval can be critical to the accuracy of the response.
The Elastic Search AI platform provides the flexibility and advantage of hybrid search, along with several built-in features that help agentic AI in terms of accuracy, performance, and scalability; in other words, Elastic makes a fantastic platform for several aspects of context engineering! In standardizing context retrieval via a search platform, we simplify agentic tool operations on several fronts — and similar to the oxymoron “slow down to go faster,” simplicity at the context generation layer means faster and more trustworthy agentic AI.
Related Content
January 30, 2026
Query rewriting strategies for LLMs and search engines to improve results
Exploring query rewriting strategies and explaining how to use the LLM's output to boost the original query's results and maximize search relevance and recall.

January 29, 2026
Building human-in-the-loop (HITL) AI agents with LangGraph and Elasticsearch
Learn what human-in-the-loop (HITL) is and how to build an HITL system with LangGraph and Elasticsearch for a flight system.
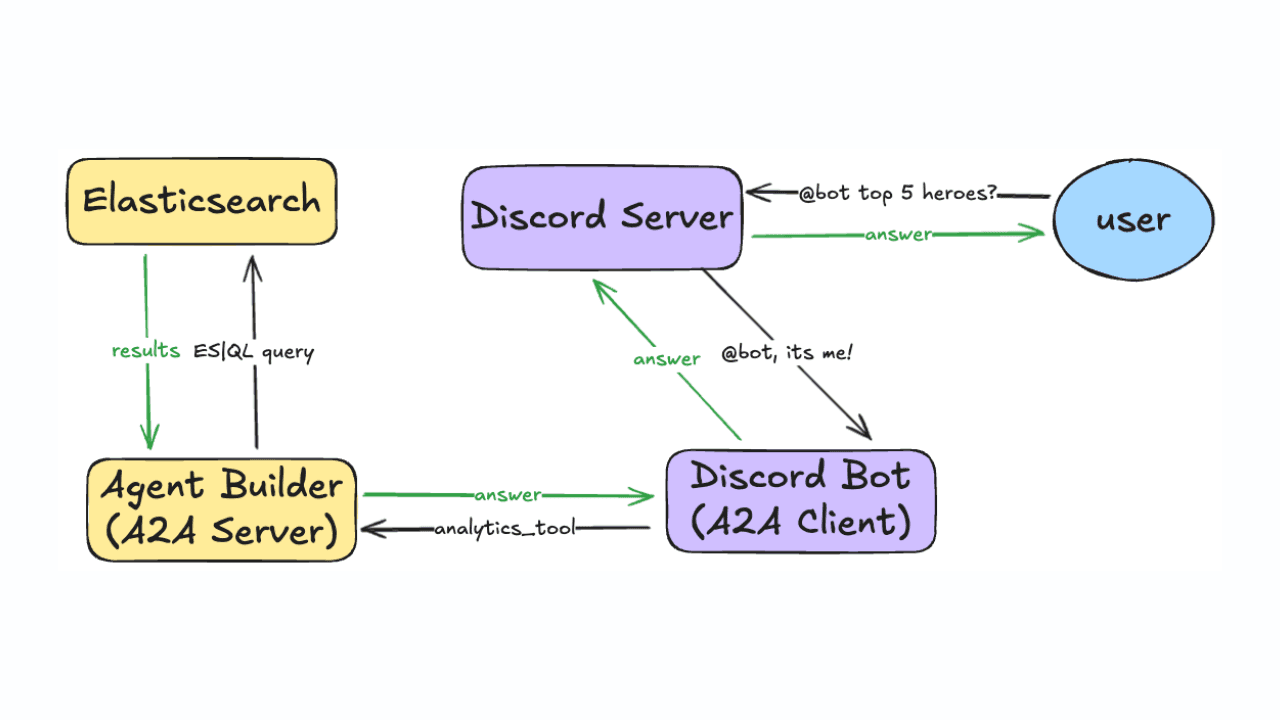
January 27, 2026
Using Discord and Elastic Agent Builder A2A to build a gaming community support bot
Learn how to connect Discord to Elastic Agent Builder's Agent-to-Agent (A2A) server to create a gaming community support bot.
January 22, 2026
Agent Builder now GA: Ship context-driven agents in minutes
Agent Builder is now GA. Learn how it allows you to quickly develop context-driven AI agents.

January 22, 2026
Building voice agents with Elastic Agent Builder
Exploring how voice agents work and how to build one using Elastic Agent Builder and LiveKit.