Agent Builder is available now GA. Get started with an Elastic Cloud Trial, and check out the documentation for Agent Builder here.
This blog post delves into agentic RAG workflows, explaining their key features and common design patterns. It further demonstrates how to implement these workflows through a hands-on example that uses Elasticsearch as the vector store and LangChain to construct the agentic RAG framework. Finally, the article briefly discusses best practices and challenges associated with designing and implementing such architectures. You can follow along to create a simple agentic RAG pipeline with this Jupyter notebook.
Introduction to agentic RAG
Retrieval Augmented Generation (RAG) has become a cornerstone in LLM-based applications, enabling models to provide optimal answers by retrieving relevant context based on user queries. RAG systems enhance the accuracy and context of LLM responses by drawing on external information from APIs or data stores, instead of being limited to pre-trained LLM knowledge. On the other hand, the AI agents operate autonomously, making decisions and taking actions to achieve their designated objectives.
Agentic RAG is a framework that unifies the strengths of both retrieval-augmented generation and agentic reasoning. It integrates RAG into the agent’s decision-making process, enabling the system to dynamically choose data sources, refine queries for better context retrieval, generate more accurate responses, and apply a feedback loop to continuously improve output quality.
Key features of agentic RAG
The agentic RAG framework marks a major advancement over traditional RAG systems. Instead of following a fixed retrieval process, it leverages dynamic agents capable of planning, executing, and optimizing results in real time.
Let’s look at some of the key features that distinguish agentic RAG pipelines:
- Dynamic decision making: Agentic RAG uses a reasoning mechanism to understand the user’s intent and route each query to the most relevant data source, producing accurate and context-aware responses.
- Comprehensive query analysis: Agentic RAG deeply analyzes user queries, including sub-questions and their overall intent. It assesses query complexity and dynamically selects the most relevant data sources to retrieve information, ensuring accurate and complete responses.
- Multi-stage collaboration: This framework enables multi-stage collaboration through a network of specialized agents. Each agent handles a specific part of a larger objective, working sequentially or simultaneously to achieve a cohesive outcome.
- Self-evaluation mechanisms: The agentic RAG pipeline uses self-reflection to evaluate retrieved documents and generated responses. It can check if the retrieved information fully addresses the query and then review the output for accuracy, completeness, and factual consistency.
- Integration with external tools: This workflow can interact with external APIs, databases, and real-time information sources, incorporating up-to-date information and adapting dynamically to evolving data.
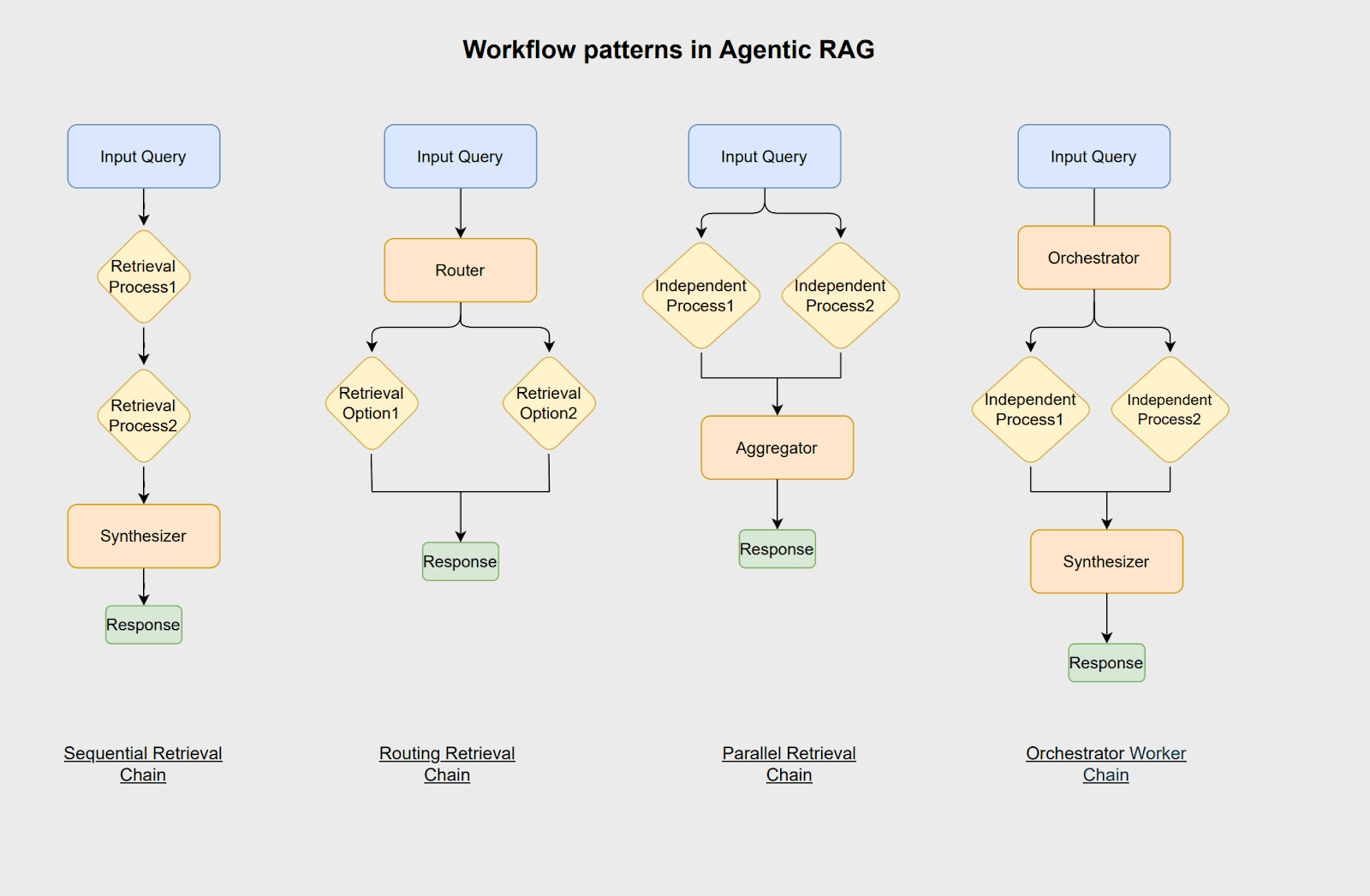
Workflow patterns of agentic RAG
The workflow patterns define how agentic AI structures, manages, and orchestrates LLM-based applications in a reliable and efficient manner. Several frameworks and platforms, such as LangChain, LangGraph, CrewAI, and LlamaIndex, can be used to implement these agentic workflows.
- Sequential retrieval chain: Sequential workflows divide complex tasks into simple, ordered steps. Each step improves the input for the next one, leading to better results. For example, when creating a customer profile, one agent might pull basic details from a CRM, another retrieves purchase history from a transaction database, and a final agent combines this information to generate a complete profile for recommendations or reports.
- Routing retrieval chain: In this workflow pattern, a router agent analyzes the input and directs it to the most appropriate process or data source. This approach is particularly effective when multiple distinct data sources exist with minimal overlap. For instance, in a customer service system, the router agent categorizes incoming requests, such as technical issues, refunds, or complaints, and routes them to the appropriate department for efficient handling.
- Parallel retrieval chain: In this workflow pattern, multiple independent subtasks are executed concurrently, and their outputs are later aggregated to generate a final response. This approach significantly reduces processing time and increases workflow efficiency. For example, in a customer service parallel workflow, one agent retrieves similar past requests, and another consults relevant knowledge base articles. An aggregator then combines these outputs to generate a comprehensive resolution.
- Orchestrator worker chain: This workflow shares similarities with parallelization due to its utilization of independent subtasks. However, a key distinction lies in the integration of an orchestrator agent. This agent is responsible for analyzing user queries, dynamically segmenting them into subtasks during runtime, and identifying the appropriate processes or tools required to formulate an accurate response.
Building an agentic RAG pipeline from scratch
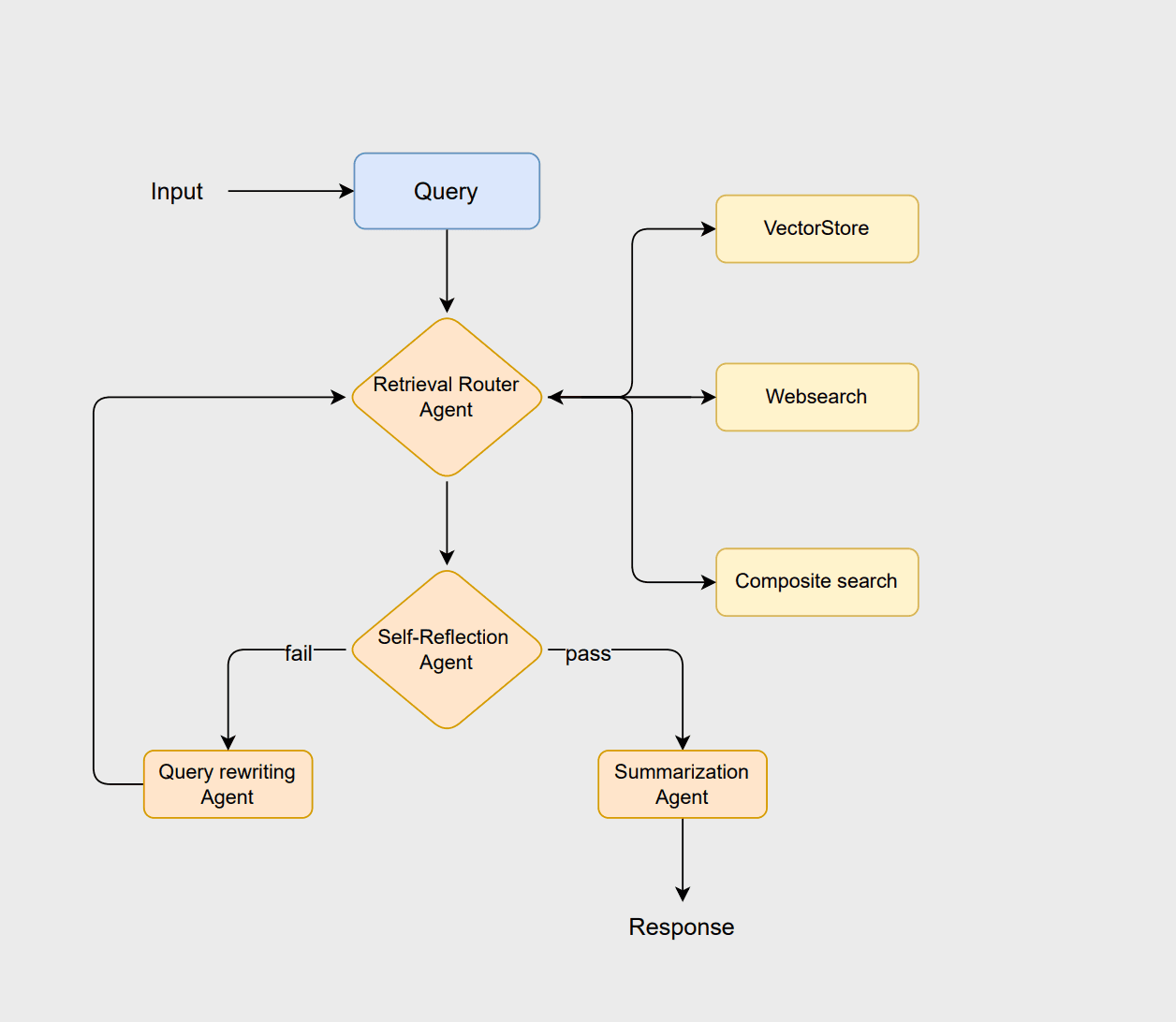
To illustrate the principles of agentic RAG, let's design a workflow using LangChain and Elasticsearch. This workflow adopts a routing-based architecture, where multiple agents collaborate to analyze queries, retrieve relevant information, evaluate results, and generate coherent responses. You could refer to this Jupyter notebook to follow along with this example.
The workflow starts with the router agent, which analyzes the user's query to select the optimal retrieval method, i.e., either a vectorstore, websearch, or composite approach. The vectorstore handles traditional RAG-based document retrieval, the websearch fetches the most recent information not stored in the vectorstore, and the composite approach combines both when information from multiple sources is needed.
If the documents are deemed suitable, the summarization agent generates a clear and contextually appropriate response. However, if the documents are insufficient or irrelevant, the query rewriting agent reformulates the query to improve the search. This revised query then reinitiates the routing process, allowing the system to refine its search and enhance the final output.
Prerequisites
This workflow relies on the following core components to execute the example effectively:
- Python 3.10
- Jupyter notebook
- Azure OpenAI
- Elasticsearch
- LangChain
Before proceeding, you will be prompted to configure the following set of required environment variables for this example.
Data sources
This workflow is illustrated using a subset of the AG News dataset. The dataset comprises news articles across diverse categories, such as International, Sports, Business, and Science/Technology.
The ElasticsearchStore module is utilized from the langchain_elasticsearch as our vector store. For retrieval, we implement the SparseVectorStrategy, employing ELSER, Elastic's proprietary embedding model. It is essential to confirm that the ELSER model is correctly installed and deployed in your Elasticsearch environment before initiating the vector store.
The web search functionality is implemented using DuckDuckGoSearchRun from the LangChain community tools, which allows the system to retrieve live information from the web efficiently. You can also consider using other search APIs that may provide more relevant results. This tool was chosen as it allows searches without requiring an API key.
Composite retriever is designed for queries that require a combination of sources. It is used to provide a comprehensive and contextually accurate response by simultaneously retrieving real-time data from the web and consulting historical news from the vector store.
Setting up the agents
In the next step, the LLM agents are defined to provide reasoning and decision-making capabilities within this workflow. The LLM chains we will create include: router_chain, grade_docs_chain, rewrite_query_chain, and summary_chain.
The router agent uses an LLM assistant to determine the most appropriate data source for a given query at run-time. The grading agent evaluates the retrieved documents for relevance. If the documents are deemed relevant, they are passed to the summary agent to generate a summary. Otherwise, the rewrite query agent reformulates the query and sends it back to the routing process for another retrieval attempt. You can find the instructions for all the agents under the LLM chains section of the notebook.
The llm.with_structured_output constrains the output of the model to follow a predefined schema defined by the BaseModel under the RouteQuery class, ensuring consistency of the results. The second line composes a RunnableSequence by connecting router_prompt with router_structured, forming a pipeline in which the input prompt is processed by the language model to produce structured, schema-compliant results.
Define graph nodes
This part involves defining the states of the graph, which represent the data that flows between different components of the system. A clear specification of these states ensures that each node in the workflow knows what information it can access and update.
Once the states are defined, the next step is to define the nodes of the graph. Nodes are like the functional units of the graph that perform specific operations on the data. There are 7 different nodes in our pipeline.
The query_rewriter node serves two purposes in the workflow. First, it rewrites the user query using the rewrite_query_chain to improve retrieval when the documents evaluated by the self-reflection agent are deemed insufficient or irrelevant. Second, it acts as a counter that tracks how many times the query has been rewritten.
Each time the node is invoked, it increments the retry_count stored in the workflow state. This mechanism prevents the workflow from entering an infinite loop. If the retry_count exceeds a predefined threshold, the system can fallback to an error state, a default response, or any other predefined condition you choose.
Compiling the graph
The last step is to define the edges of the graph and add any necessary conditions before compiling it. Every graph must start from a designated starting node, which serves as the entry point for the workflow. Edges in the graph represent the flow of data between nodes and can be of two types:
- Straight edges: These define a direct, unconditional flow from one node to another. Whenever the first node completes its task, the workflow automatically proceeds to the next node along the straight edge.
- Conditional edges: These allow the workflow to branch based on the current state or the results of a node’s computation. The next node is selected dynamically depending on conditions such as evaluation results, routing decisions, or retry counts.
With that, your first agentic RAG pipeline is ready and can be tested using the compiled agent.
Testing the agentic RAG pipeline
We will now test this pipeline using three distinct types of queries as below. Note that results can differ, and the examples shown below illustrate just one potential outcome.
For the first query, the router selects websearch as the data source. The query fails the self-reflection evaluation and is subsequently redirected to the query rewriting stage, as shown in the output.
Next, we examine an example where vectorstore retrieval is used, demonstrated with the second query.
The final query is directed to composite retrieval, which utilizes both the vectorstore and web search.
In the above workflow, agentic RAG intelligently determines which data source to use when retrieving information for a user query, thereby improving the accuracy and relevance of the response. You can create additional examples to test the agent and review the outputs to see if they yield any interesting results.
Best practices for building agentic RAG workflows
Now that we understand how agentic RAG works, let’s look at some best practices for building these workflows. Following these guidelines will help keep the system efficient and easy to maintain.
- Prepare for fallbacks: Plan fallback strategies in advance for scenarios where any step of the workflow fails. These may include returning default answers, triggering error states, or using alternative tools. This ensures that the system handles failures gracefully without breaking the overall workflow.
- Implement comprehensive logging: Try implementing logging at each stage of the workflow, such as retries, generated outputs, routing choices, and query rewrites. These logs help to improve transparency, make debugging easier, and help refine prompts, agent behavior, and retrieval strategies over time.
- Select the appropriate workflow pattern: Examine your use case and select the workflow pattern that best suits your needs. Use sequential workflows for step-by-step reasoning, parallel workflows for independent data sources, and orchestrator-worker patterns for multi-tool or complex queries.
- Incorporate evaluation strategies: Integrate evaluation mechanisms at different stages of the workflow. These can include self-reflection agents, grading retrieved documents, or automated quality checks. Evaluation helps verify that retrieved documents are relevant, responses are accurate, and all parts of a complex query are addressed.
Challenges
While agentic RAG systems offer significant advantages in terms of adaptability, precision, and dynamic reasoning, they also come with certain challenges that must be addressed during their design and implementation stages. Some of the key challenges include:
- Complex workflows: As more agents and decision points are added, the overall workflow becomes increasingly complex. This can lead to higher chances of errors or failures at runtime. Whenever possible, prioritize streamlined workflows by eliminating redundant agents and unnecessary decision points.
- Scalability: It can be challenging to scale agentic RAG systems to handle large datasets and high query volumes. Incorporate efficient indexing, caching, and distributed processing strategies to maintain performance at scale.
- Orchestration and computational overhead: The execution of workflows with multiple agents requires advanced orchestration. This includes careful scheduling, dependency management, and agent coordination to prevent bottlenecks and conflicts, all of which add to the overall system complexity.
- Evaluation complexity: The evaluation of these workflows presents inherent challenges, as each stage requires a distinct assessment strategy. For instance, the RAG stage must be evaluated for the relevance and completeness of retrieved documents, while generated summaries need to be checked for quality and accuracy. Likewise, the effectiveness of query reformulation requires a separate evaluation logic to determine whether the rewritten query improves retrieval outcomes.
Conclusion
In this blog post, we introduced the concept of agentic RAG and highlighted how it enhances the traditional RAG framework by incorporating autonomous capabilities from agentic AI. We explored the core features of agentic RAG and demonstrated these features through a hands-on example, building a news assistant using Elasticsearch as the vector store and LangChain to create the agentic framework.
Additionally, we discussed best practices and key challenges to consider when designing and implementing an agentic RAG pipeline. These insights are intended to guide developers in creating robust, scalable, and efficient agentic systems that effectively combine retrieval, reasoning, and decision-making.
What’s next
The workflow we built is simple, leaving ample room for improvements and experimentation. We can enhance this by experimenting with various embedding models and refining retrieval strategies. Additionally, integrating a re-ranking agent to prioritize retrieved documents could be beneficial. Another area for exploration involves developing evaluation strategies for agentic frameworks, specifically identifying common and reusable approaches applicable across different types of frameworks. Finally, experimenting with these frameworks on large and more complex datasets.
In the meantime, if you have similar experiments to share, we’d love to hear about them! Feel free to provide feedback or connect with us through our community Slack channel or discussion forums.
Resources
Related Content

January 29, 2026
Building human-in-the-loop (HITL) AI agents with LangGraph and Elasticsearch
Learn what human-in-the-loop (HITL) is and how to build an HITL system with LangGraph and Elasticsearch for a flight system.
January 27, 2026
Using Discord and Elastic Agent Builder A2A to build a gaming community support bot
Learn how to connect Discord to Elastic Agent Builder's Agent-to-Agent (A2A) server to create a gaming community support bot.
January 22, 2026
Agent Builder now GA: Ship context-driven agents in minutes
Agent Builder is now GA. Learn how it allows you to quickly develop context-driven AI agents.

January 22, 2026
Building voice agents with Elastic Agent Builder
Exploring how voice agents work and how to build one using Elastic Agent Builder and LiveKit.
January 22, 2026
Agent Builder, beyond the chatbox: Introducing Augmented Infrastructure
Learn about Elastic Agent Builder with Augmented Infrastructure, an AI agent that enables augmented operations, augmented development, and augmented synthetics.