Explicando as anomalias detectadas pelo machine learning da Elastic


 Share on Twitter
Share on TwitterCompartilhar no Twitter

 Share on LinkedIn
Share on LinkedInCompartilhar no LinkedIn

 Share on Facebook
Share on FacebookCompartilhar no Facebook

 Share by Email
Share by EmailCompartilhar por e-mail

 Print this page
Print this pageImprimir
Por que isso é anômalo? Por que a pontuação de anomalia não é maior? A detecção de anomalia é um recurso valioso do machine learning usado no Elastic Security e no Observability. Mas esses números podem parecer confusos. Bem que alguém podia explicá-los em linguagem clara. Ou, melhor ainda, desenhar para nós.
No Elastic 8.6, mostramos detalhes extras para registros de anomalias. Esses detalhes permitem olhar os bastidores do algoritmo de pontuação de anomalias.
Já escrevemos sobre pontuação e normalização de anomalias neste blog anteriormente. O algoritmo de detecção de anomalia analisa séries temporais de dados online. Ele identifica tendências e padrões periódicos em diferentes escalas de tempo, como um dia, uma semana, um mês ou um ano. Os dados do mundo real geralmente são uma mistura de tendências e padrões periódicos em diferentes escalas de tempo. Além disso, o que inicialmente parece uma anomalia pode se tornar um padrão recorrente emergente.
O trabalho de detecção de anomalia apresenta hipóteses que explicam os dados. Ele pesa e combina essas hipóteses usando as evidências fornecidas. Todas as hipóteses são distribuições de probabilidade. Portanto, podemos fornecer um intervalo de confiança sobre o quanto as observações são “normais”. As observações que ficam fora desse intervalo de confiança são anômalas.
Fatores de impacto na pontuação de anomalias
Agora, você provavelmente deve estar pensando: tá, essa teoria é simples. Mas quando vemos um comportamento inesperado, como quantificamos o quanto ele é fora do comum?
Três fatores podem constituir a pontuação inicial de anomalia que atribuímos aos registros:
- Impacto de um único bucket
- Impacto de vários buckets
- Impacto das características da anomalia
Vamos lembrar que os trabalhos de detecção de anomalia dividem os dados da série temporal em intervalos de tempo (buckets). Os dados dentro de um bucket são agregados usando funções. A detecção de anomalia está ocorrendo nos valores do bucket. Leia este post do blog para saber mais sobre buckets e por que escolher o intervalo do bucket correto é fundamental.
Primeiro, examinamos a probabilidade do valor real no bucket, dada a mistura de hipóteses. Essa probabilidade depende de quantos valores semelhantes vimos no passado. Frequentemente, refere-se à diferença entre o valor real e o valor típico. O valor típico é o valor mediano da distribuição de probabilidade para o bucket. Essa probabilidade leva ao impacto de um único bucket. Geralmente, ele domina a pontuação de anomalia inicial de um curto pico ou queda.
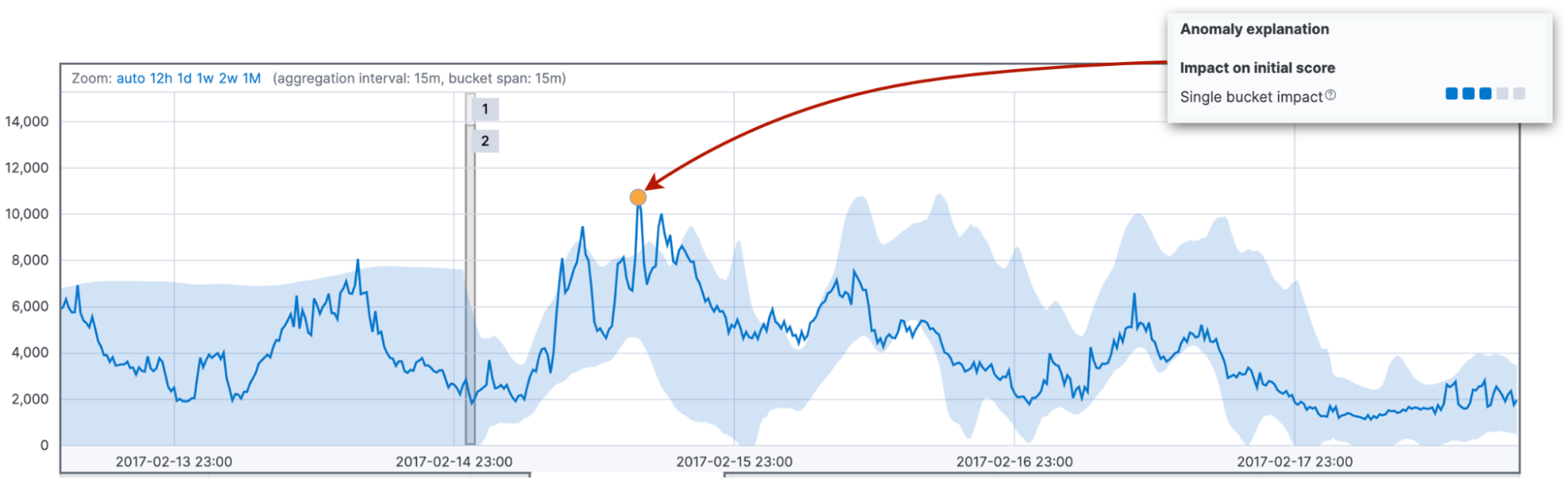
Em segundo lugar, examinamos as probabilidades de observar os valores nos valores do bucket atual junto com os 11 buckets anteriores. As diferenças acumuladas entre os valores reais e típicos resultam no impacto de vários buckets na pontuação de anomalia inicial do bucket atual.
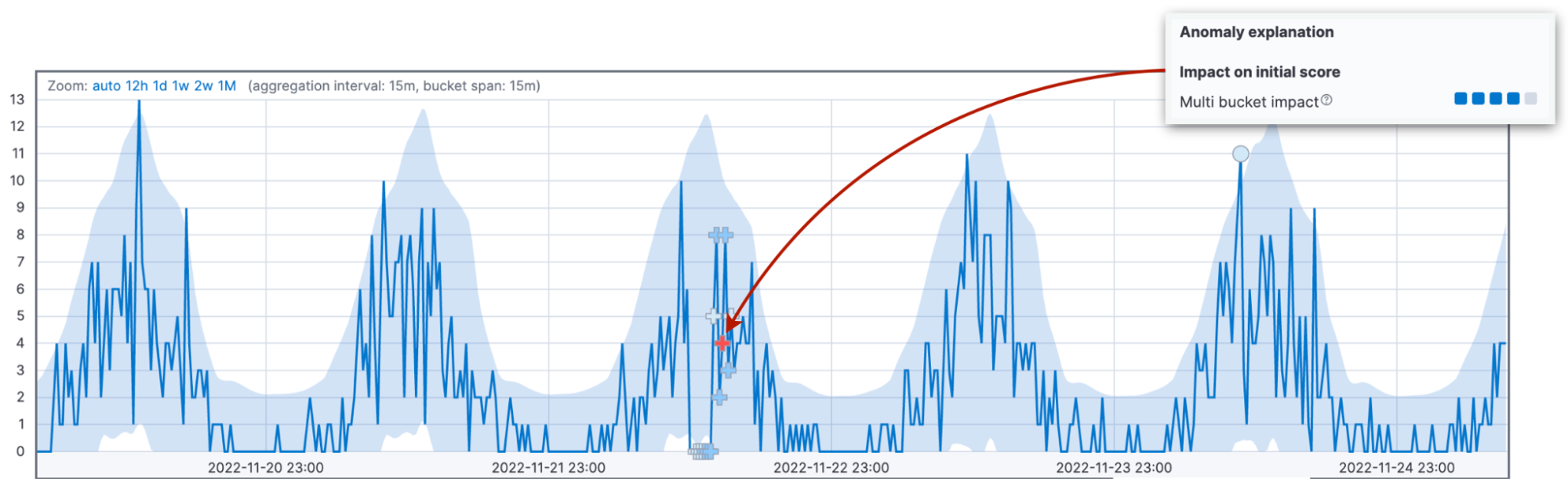
Vamos insistir nessa ideia, pois o impacto de vários buckets é a segunda causa mais comum de confusão sobre pontuações de anomalia. Observamos os desvios combinados em 12 buckets e atribuímos o impacto ao bucket atual. Um alto impacto de vários buckets indica um comportamento incomum no intervalo que antecede o bucket atual. Não importa se o valor atual do bucket pode voltar a estar dentro do intervalo de confiança de 95%.
Para destacar essa diferença, usamos até mesmo marcadores diferentes para anomalias com alto impacto de vários buckets. Se você observar atentamente a anomalia de vários buckets na figura acima, verá que a anomalia está marcada com um sinal de cruz “+” em vez de um círculo.
Por fim, consideramos o impacto das características da anomalia, como duração e tamanho. Aqui levamos em consideração a duração total da anomalia até agora, não um intervalo fixo como acima. Pode ser um bucket ou trinta. A comparação da duração e do tamanho da anomalia com as médias históricas permite a adaptação ao domínio do cliente e aos padrões nos dados.
Além disso, o comportamento padrão do algoritmo é atribuir pontuações maiores a anomalias mais longas do que a picos de curta duração. Na prática, anomalias curtas costumam ser falhas nos dados, enquanto anomalias longas são algo a que você precisa reagir.
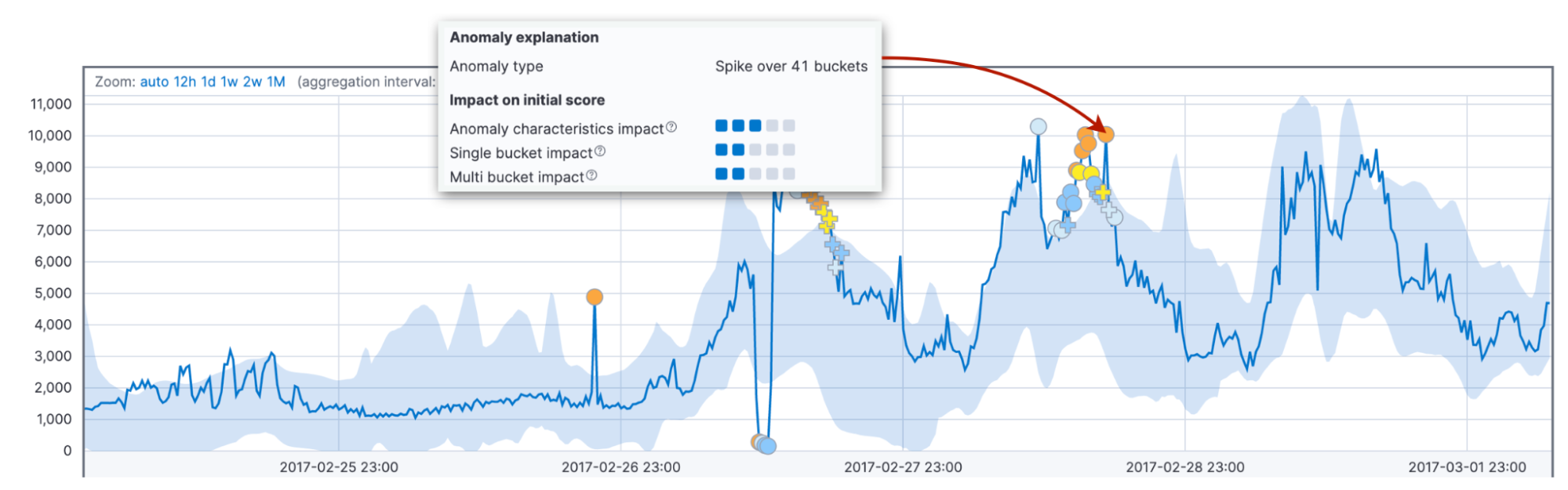
Por que precisamos de ambos os fatores com intervalos fixos e variáveis? A combinação deles leva a uma detecção mais confiável de um comportamento anormal em vários domínios.
Redução de pontuação recorde
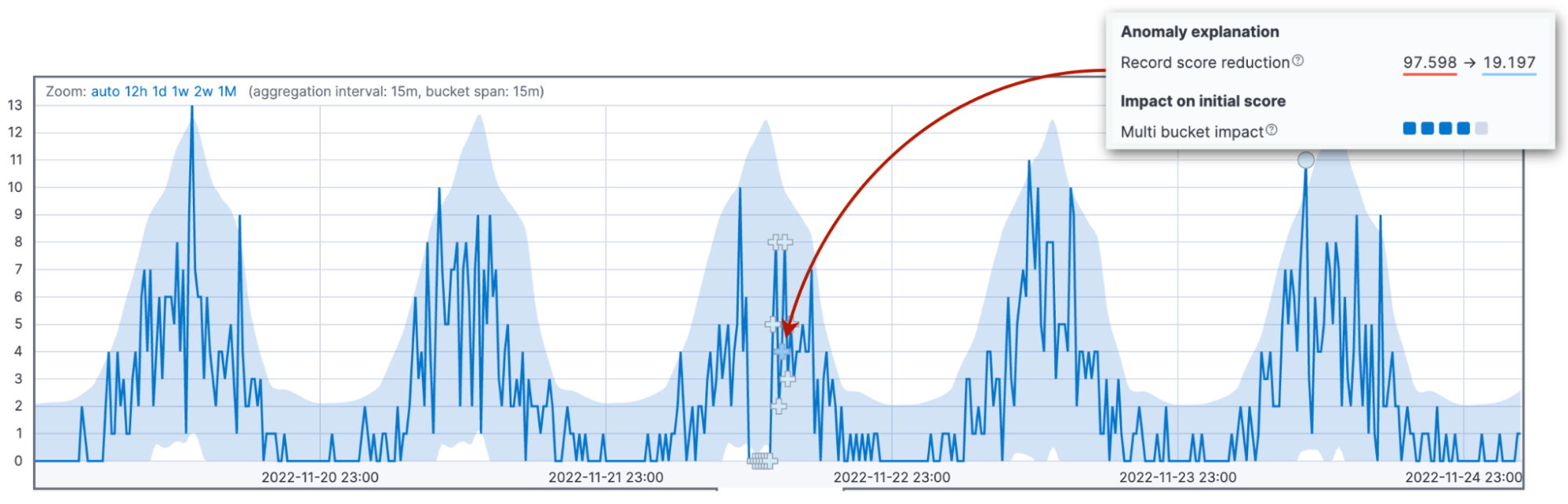
Agora, é hora de falar sobre a fonte mais comum de confusão na pontuação: a renormalização da pontuação. As pontuações de anomalia são normalizadas no intervalo entre 0 e 100. Os valores próximos a 100 significam as maiores anomalias que o trabalho já viu. Isso significa que, quando vemos uma anomalia maior do que nunca, precisamos reduzir as pontuações das anomalias anteriores.
Os três fatores descritos acima afetam o valor da pontuação de anomalia inicial. A pontuação inicial é importante porque o operador é alertado com base nesse valor. À medida que novos dados chegam, o algoritmo de detecção de anomalia ajusta as pontuações de anomalia dos registros anteriores. O parâmetro de configuração renormalization_window_days especifica o intervalo de tempo para esse ajuste. Portanto, se você está se perguntando por que uma anomalia extrema mostra uma pontuação de anomalia baixa, pode ser porque o trabalho viu anomalias ainda mais significativas posteriormente.
O visualizador de métrica única no Kibana versão 8.6 destaca essa mudança.
Outros fatores para redução de pontuação
Mais dois fatores podem levar a uma redução da pontuação inicial: alto intervalo de variância e bucket incompleto.
A detecção de anomalia é menos confiável se o bucket atual faz parte de um padrão sazonal com alta variabilidade nos dados. Por exemplo, você pode ter trabalhos de manutenção do servidor em execução todas as noites à meia-noite. Esses trabalhos podem levar a uma alta variabilidade na latência do processamento das solicitações.
Além disso, será mais confiável se o bucket atual tiver recebido um número semelhante de observações conforme o esperado historicamente.
Juntando tudo
Frequentemente, as anomalias do mundo real exibem os impactos de diversos fatores. Ao todo, a nova visualização detalhada do visualizador de métrica única pode ter a seguinte aparência:
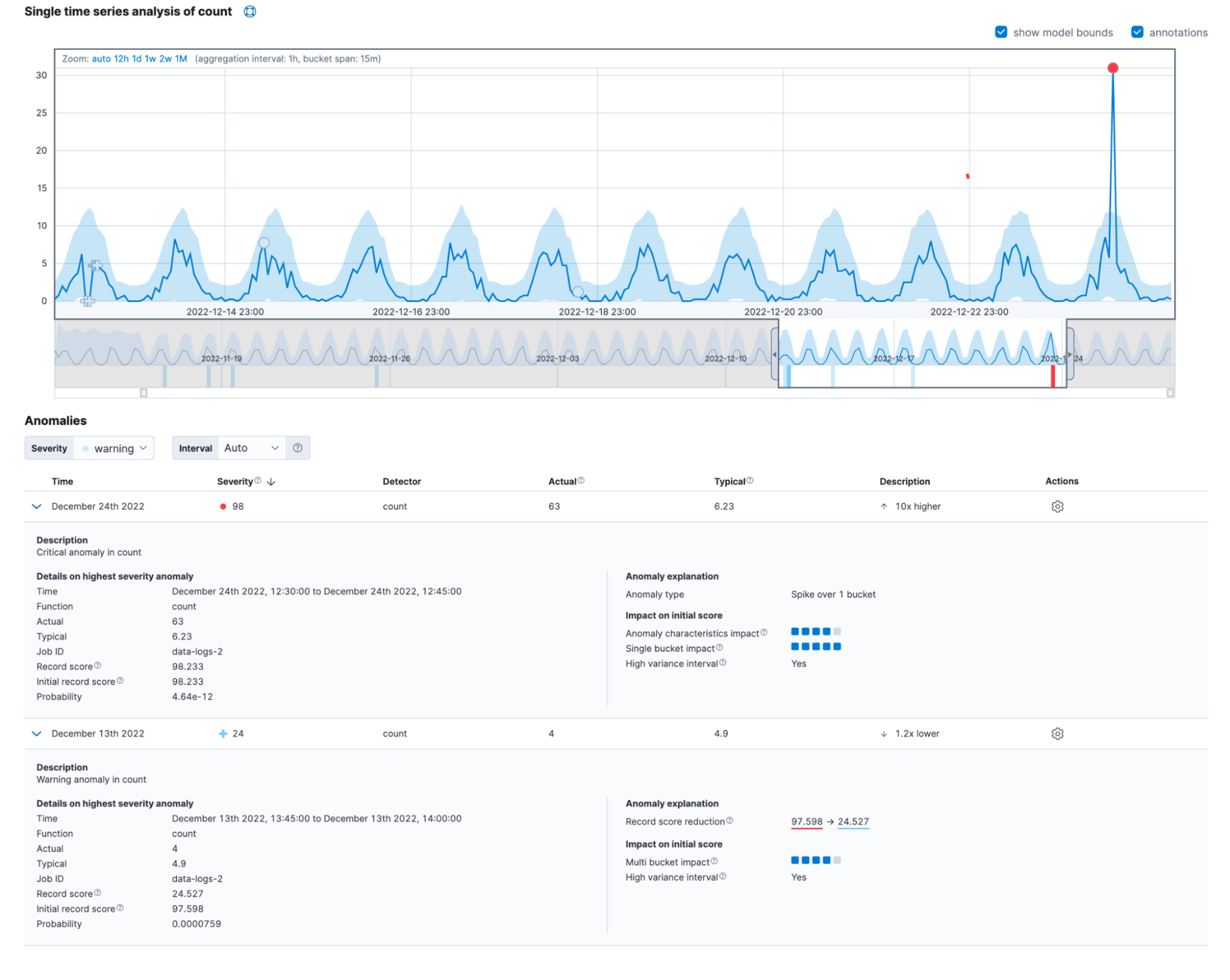
Você também pode encontrar essas informações no campo anomaly_score_explanation da get record API.
Conclusão
Experimente a versão mais recente do Elasticsearch Service no Elastic Cloud e observe a nova visualização detalhada dos registros de anomalias. Comece sua avaliação gratuita do Elastic Cloud hoje mesmo para acessar a plataforma. Boa experimentação para você!
Compartilhar
- Share on Twitter
Compartilhar no Twitter
- Share on LinkedIn
Compartilhar no LinkedIn
- Share on Facebook
Compartilhar no Facebook
- Share by Email
Compartilhar por e-mail
- Print this page
Imprimir