Correlações de APM no Elastic Observability: identificação automática das prováveis causas de lentidão ou falha nas transações


 Share on Twitter
Share on TwitterCompartilhar no Twitter

 Share on LinkedIn
Share on LinkedInCompartilhar no LinkedIn

 Share on Facebook
Share on FacebookCompartilhar no Facebook

 Share by Email
Share by EmailCompartilhar por e-mail

 Print this page
Print this pageImprimir
Um engenheiro de DevOps ou um SRE frequentemente precisa investigar questões complexas — problemas misteriosos de desempenho que ocorrem de forma intermitente ou apenas em determinadas partes do tráfego da aplicação, afetando seus usuários finais e, potencialmente, os objetivos financeiros da empresa. Analisar centenas ou mesmo milhares de transações e spans pode ser um trabalho investigativo tedioso, manual e demorado. As implantações de microsserviços distribuídos ou nativos da nuvem apresentam outras complexidades, aumentando o tempo para determinar a causa raiz.
Não seria incrível se você pudesse identificar rapidamente um padrão comum que pudesse ajudar a explicar um problema aparentemente tão complexo, desmistificando-o e abrindo caminho para uma análise e correção mais rápidas da causa raiz?
A mágica das correlações de APM no Elastic Observability
A funcionalidade de correlação de APM da Elastic revela automaticamente atributos do conjunto de dados de APM que estão correlacionados a transações de alta latência ou errôneas e que têm o impacto mais significativo no desempenho geral do serviço.
Seu fluxo de trabalho investigativo para problemas de APM geralmente começa na guia Transactions (Transações) da visualização de APM. Quer seu interesse seja as transações com alta latência ou as transações que falharam, comece visualizando as discrepâncias no gráfico de distribuição de latência desse grupo de transações específico. As transações de alta latência aparecem no lado direito do gráfico, e os rótulos das transações com latência e com falha mostram a extensão do impacto. Além disso, a anotação do 95º percentil no gráfico ajuda ainda mais a separar visualmente as verdadeiras discrepâncias.
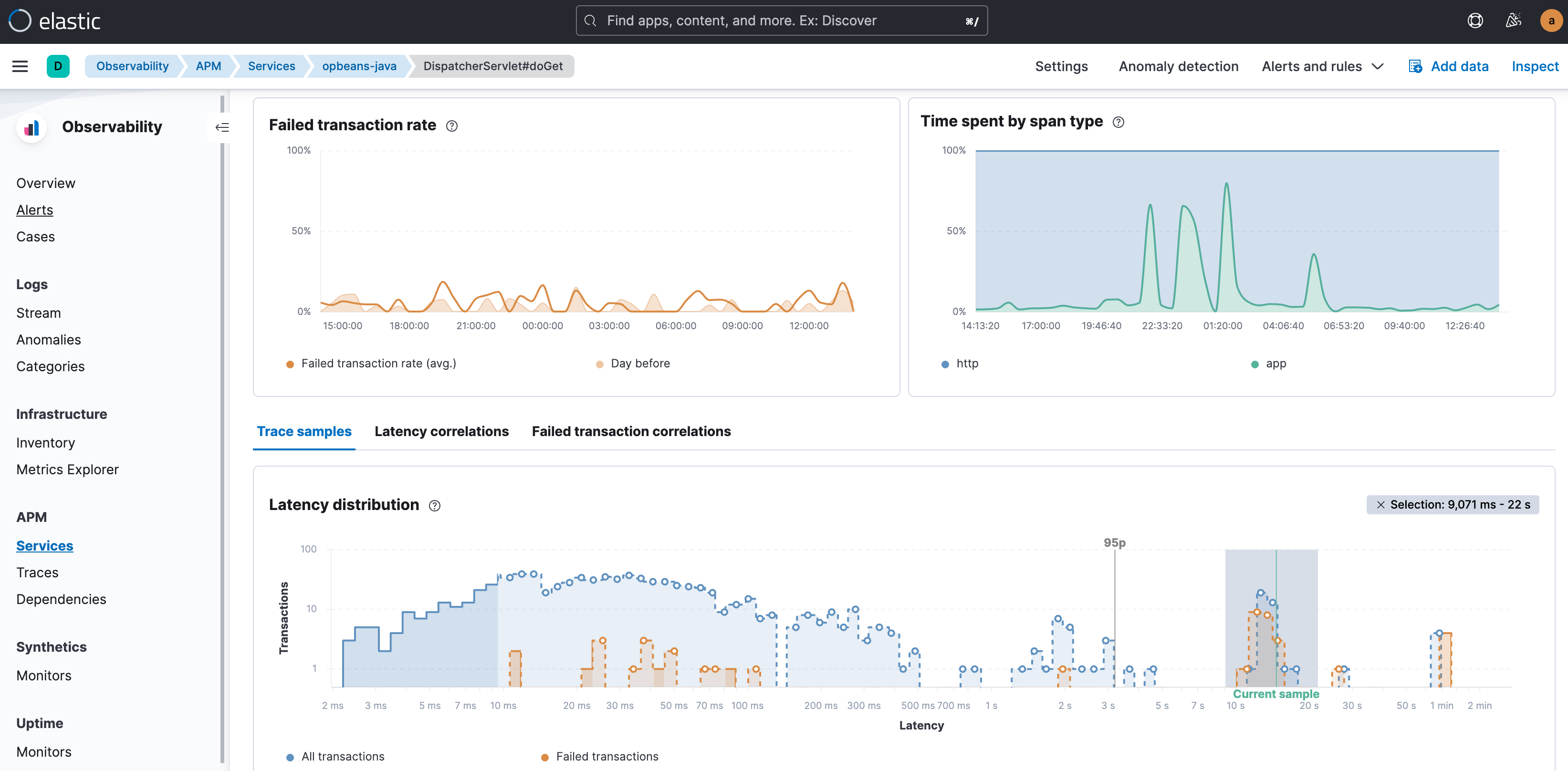
Sua próxima etapa seria procurar atributos e fatores nos dados que mais se correlacionem com essas discrepâncias e restringir sua investigação aos subgrupos afetados no conjunto de dados geral. Em outras palavras, procure atributos que estejam desproporcionalmente representados em transações lentas ou errôneas. Esses atributos incluem rótulos, tags, atributos de trace e metadados, como versões de serviço; localizações geográficas; tipos de dispositivos; identificadores de infraestrutura; rótulos específicos da nuvem, como zona de disponibilidade, sistema operacional e tipo de cliente para serviços de frontend; e uma série de outros atributos. A intenção é ser capaz de explicar as transações anômalas em termos desses atributos. Por exemplo, a capacidade de dizer “quase todas as transações de alta latência estão ocorrendo no pod do Kubernetes x” ou “transações com o rótulo shoppingCartVolumeHigh e a versão do serviço a.b estão falhando”.
Imagine se você tivesse de examinar todos esses atributos manualmente (que podem chegar às centenas) para determinar quais atributos específicos poderiam ajudar a explicar as discrepâncias no desempenho!
O Elastic Observability compara automaticamente os atributos com altas latências e erros com o conjunto completo de transações e identifica tags e metadados que são “excepcionalmente comuns” nas transações abaixo do ideal. Em outras palavras, ele identifica elementos que são significativamente mais comuns em transações abaixo do ideal do que no conjunto completo de transações. Em seguida, além de oferecer as correlações, também apresenta primeiro os atributos de correlação mais altos. O valor de correlação (variando de 0 a 1,00, onde 1,00 indica uma correlação perfeita) ajuda a fornecer uma indicação rápida da extensão da correspondência. Clique em qualquer atributo para ver as transações que carregam esse atributo, codificadas por cores e apresentadas no gráfico de distribuição, para visualizar melhor a sobreposição.
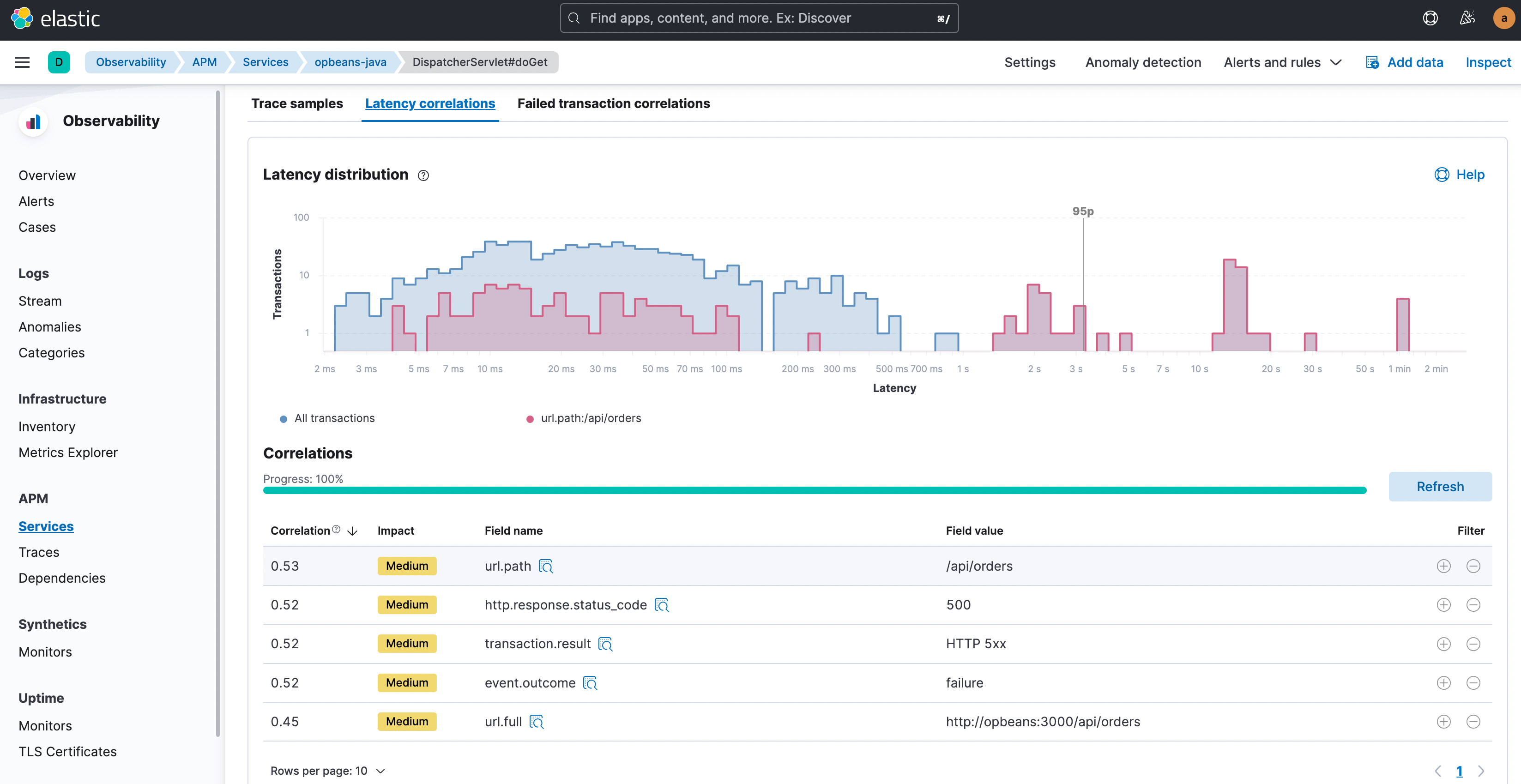
Com esses fatores correlacionados identificados, agora você pode restringir seu foco apenas a essas transações. Clique nos botões de filtro “+” ou “-” para selecionar apenas as transações com esse valor de atributo ou para excluir tais transações e estudar mais detalhadamente as transações de interesse. Uma próxima etapa típica para latência poderia ser examinar as amostras de trace apenas das transações de alta latência que também carregam os atributos correlacionados identificados e chegar a esse momento “Ahá!” em que você vê o culpado: uma chamada de função lenta nos traces.
Depois que a causa raiz for confirmada, você poderá iniciar o processo de correção e recuperação por meio de mecanismos como reversões, patches de software ou atualizações.
Vamos considerar o cenário de transações com falha a seguir. No exemplo abaixo, o grupo de transações '/pt/hipstershop.CheckoutService/PlaceOrder' no 'checkoutService' está apresentando uma alta taxa de transações com falha.
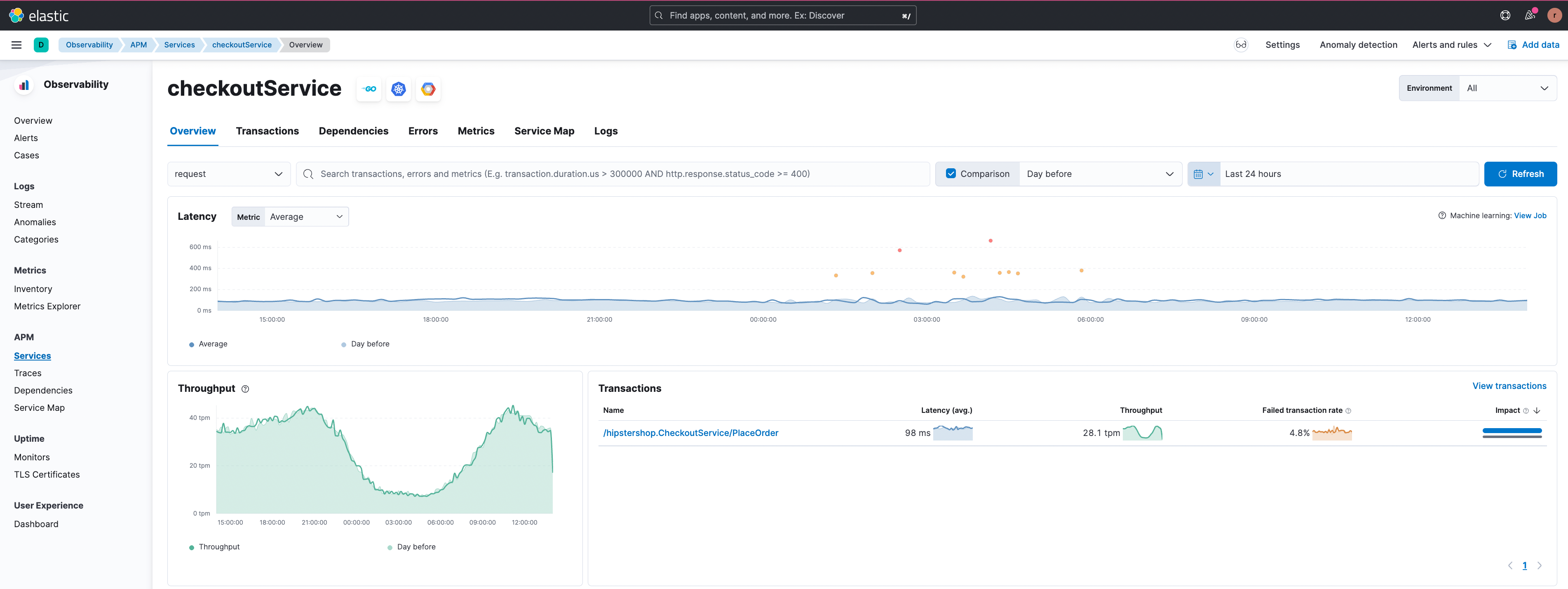
O recurso de correlação mostra as transações com falha dos usuários da América do Sul na figura abaixo.
Ao clicar no filtro “+”, podemos nos concentrar neste subconjunto particular de transações, e uma transação de exemplo com o erro é mostrada.
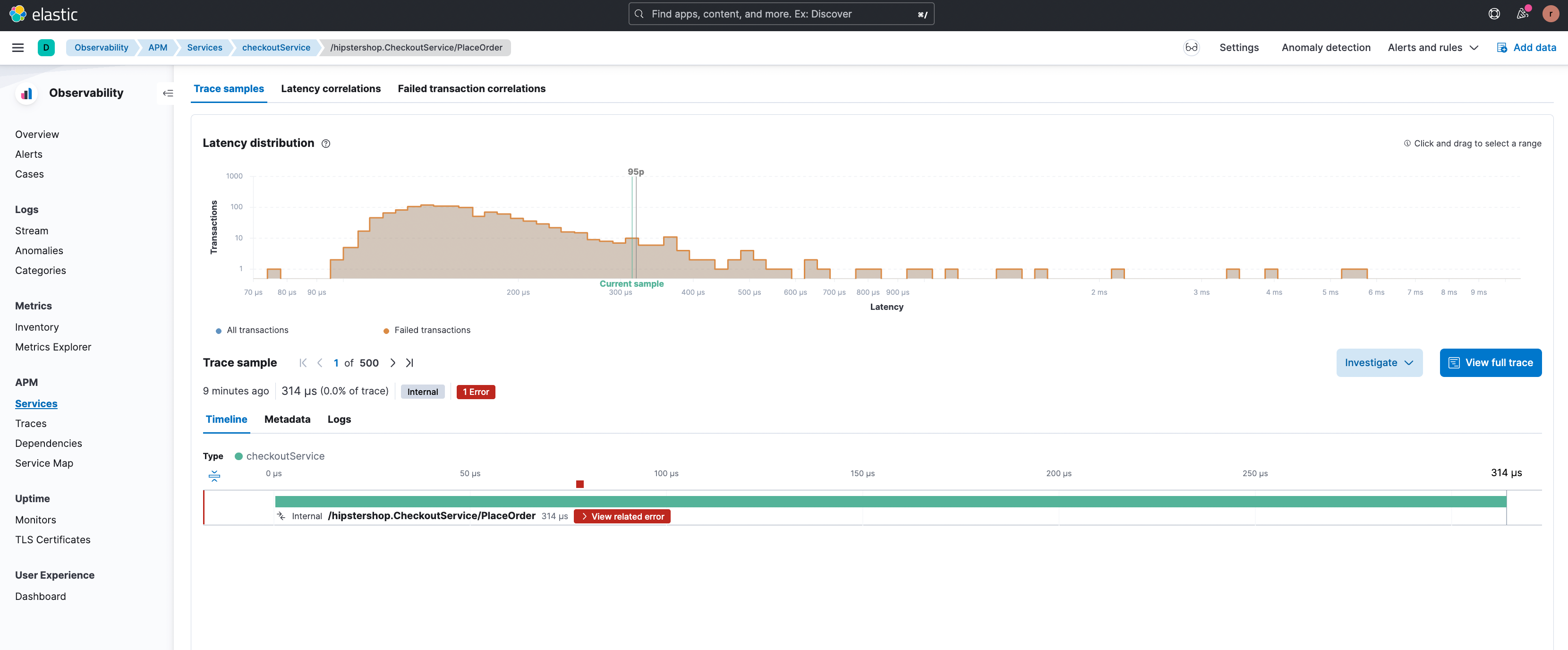
Ao clicar em “View related error” (Ver o erro relacionado), o usuário é redirecionado para a página de detalhes do erro relevante (mostrada abaixo), onde os diferentes tipos de erros associados a este endpoint são destacados. O trace de stack de uma ocorrência de erro também está disponível aqui, fornecendo informações de depuração aprimoradas.
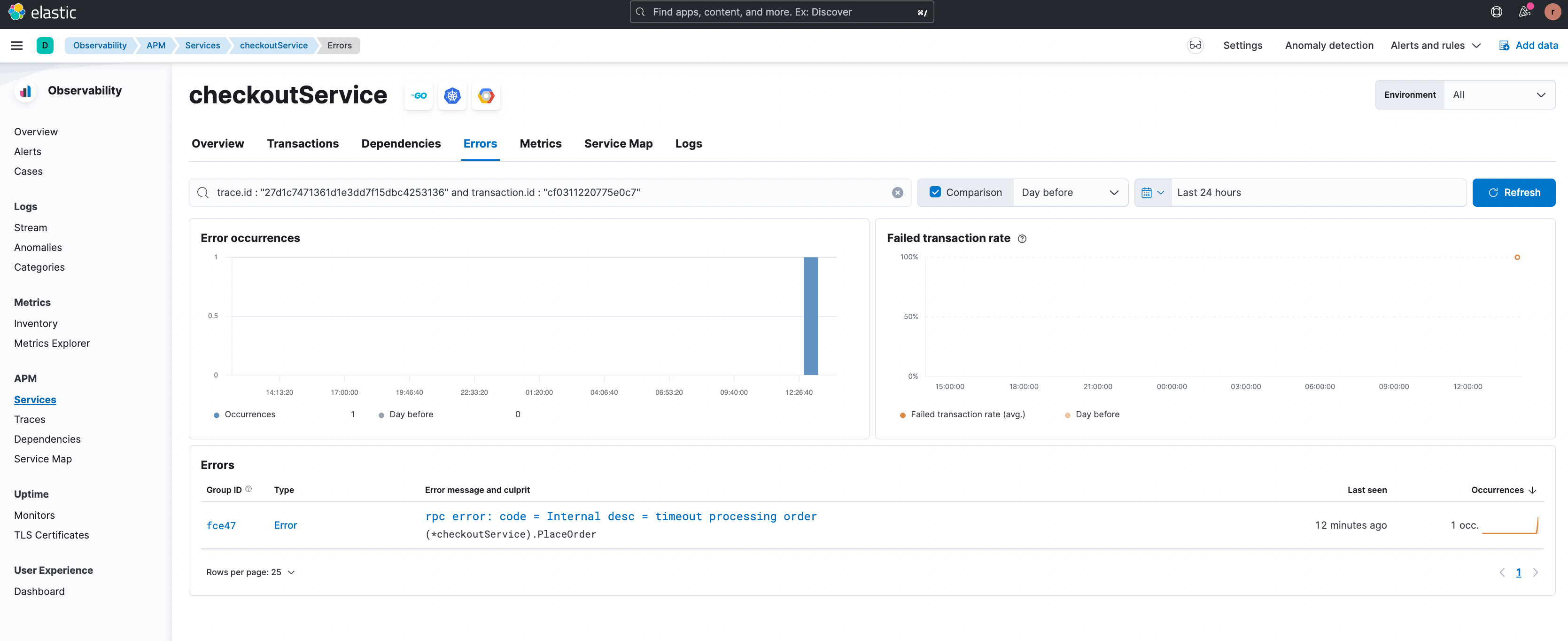
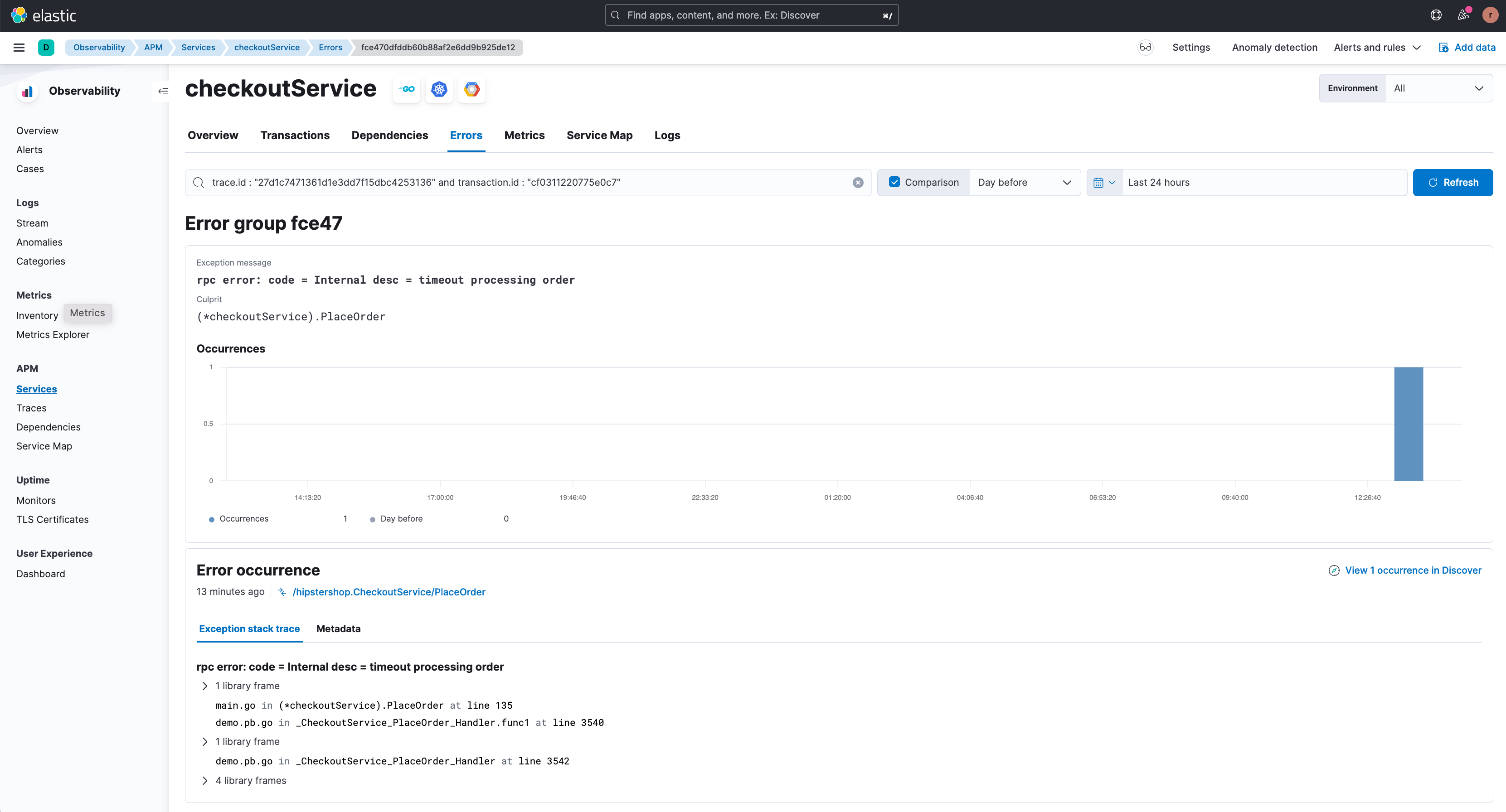
A partir dos exemplos acima, pode-se ver que o recurso de correlações de APM faz o trabalho pesado para o usuário em termos de restringir os grupos de transações lentas ou errôneas. Consequentemente, o tempo médio para a detecção e o tempo para a resolução do problema são significativamente reduzidos.
Entradas e dados necessários para auxiliar nas correlações
A funcionalidade de correlações de APM pode acelerar significativamente a análise de causa raiz em problemas que afetam apenas um segmento da população. Quanto mais metadados houver para descrever os apps, os serviços, as transações, a infraestrutura e os clientes, mais rica será a análise e maior será a probabilidade de encontrar atributos que expliquem claramente as transações abaixo do ideal. O recurso de correlações utiliza todos os campos e rótulos presentes nos dados.
Use o fluxo de trabalho “Add Integrations” (Adicionar integrações) na página “Overview” (Visão geral) para adicionar funcionalidades de agente e/ou ingestão de dados para as várias aplicações, a infraestrutura e as dependências implantadas no seu ambiente. Observe que você também pode fazer a integração nativamente com várias tecnologias, incluindo ambientes nativos da nuvem como o Kubernetes baseado na nuvem e tecnologias sem servidor como o Lambda. Depois de identificar as várias fontes de telemetria, você pode enriquecer ainda mais os dados recebidos por meio do Logstash ou diretamente por meio do agente de APM. A Elastic também tem integração perfeita e suporte nativo abrangente para dados do OpenTelemetry (que, por sua vez, também oferece suporte para instrumentação manual).
As informações do lado do cliente podem ser trazidas por meio de dados de monitoramento de usuário real (RUM). O tracing distribuído é habilitado por padrão ao usar o agente de RUM da Elastic, e o tracing para solicitações de origem cruzada e propagação de tracestate pode ser facilmente configurado definindo a opção de configuração distributedTracingOrigins. Juntamente com o APM dessa forma, o RUM adiciona informações valiosas do lado do cliente, como versões do navegador, sistema operacional do cliente e contexto do usuário, e todos esses dados são incluídos automaticamente na determinação da correlação.
Com esses dados fluindo para o Elastic, as correlações de APM podem então começar a funcionar, fornecendo insights investigativos nítidos e claros, além de reduzir o tempo para determinar a causa raiz em muitas situações.
Situações em que as correlações de APM podem reduzir drasticamente o tempo para a determinação da causa raiz
Quase por definição, não há um conjunto fixo de problemas complexos para os quais um recurso específico possa fornecer todas as respostas com certeza. Afinal, muitos problemas de APM são considerados complexos exatamente porque há várias incógnitas entrando na investigação. Caso contrário, com apenas alguns problemas conhecidos, saberíamos exatamente o que procurar, e esses problemas não seriam mais complexos!
No entanto, para muitas investigações complexas, as correlações de APM podem se tornar uma parte vital do seu kit de ferramentas de investigação para restringir rapidamente o foco a áreas específicas da sua implantação e determinar ou validar a causa raiz. Uma consideração importante: seu problema está afetando toda a sua implantação ou apenas algumas subpopulações? Por exemplo, você vê todas as transações sofrerem de alta latência? Ou você vê uma fração das transações exibindo alta latência, enquanto outras parecem estar sendo executadas dentro dos limites esperados? Quando você perceber que o problema não é generalizado, considere usar o recurso de correlações de APM para ver se um subconjunto dos atributos pode ajudar a caracterizar as transações de interesse. Com esses atributos, você pode filtrar para um conjunto de transações menor e mais gerenciável, e verificar os traces para revelar a causa raiz ou visualizar as dependências de infraestrutura que contribuem para os problemas de desempenho das transações.
Estes são alguns dos exemplos de situações em que vimos que as correlações de APM são particularmente eficazes:
Problemas de desempenho de hardware: especialmente em casos de balanceamento de carga nos quais determinadas cargas estão sendo atendidas por um determinado hardware, a degradação do desempenho do hardware pode, por sua vez, resultar em determinados grupos de usuários ou determinadas partes de uma aplicação com maior latência. As correlações de APM podem ajudar a isolar rapidamente essas instâncias específicas de hardware por meio de rótulos e identificadores.
Dados de entrada utilizados:
- Rótulos globais do agente de APM coletados nos traces distribuídos
- Métricas de infraestrutura do Elastic Agent ou do Metricbeat, para poder continuar investigando depois de utilizar o recurso de correlações de APM
Problemas relacionados a tenancy de hiperescalador ou implantação multinuvem: os hiperescaladores adicionam outra camada de complexidade às implantações de aplicações. As implantações multinuvem e de nuvem híbrida são cada vez mais comuns. Ao solucionar problemas que afetam apenas algumas partes de uma aplicação, rótulos e tags de hiperescalador (por exemplo, metadados de nuvem) ajudam a detectar quais instâncias, provedores de serviços em nuvem, regiões ou zonas de disponibilidade estão vinculados ao problema. O Agente de APM Java da Elastic permite a detecção automática do provedor de serviços em nuvem usando variáveis de configuração.
Dados de entrada utilizados (coletados automaticamente pelo agente de APM):
- Zona de disponibilidade da nuvem
- Região da nuvem
Problemas específicos da região geográfica ou do grupo de usuários: as tags que identificam geolocalizações ou grupos de usuários específicos podem ser reveladas por meio de correlações de APM e podem ser usadas para isolar um segmento de usuário e estudar apenas essas transações. Por exemplo, o Agente de APM Java da Elastic oferece suporte para rótulos globais, que são utilizados por esse recurso, para que possam ajudar a fornecer contexto adicional e identificar um subconjunto da população. Os Agentes de APM da Elastic, como o Agente de APM Java, oferecem suporte para a configuração de rótulos globais, que podem ser usados para adicionar outras metainformações a todos os eventos. Rótulos globais são adicionados a transações, métricas e erros. Da mesma forma, a API do Agente de APM Java permite a instrumentação manual de transações que podem ser usadas para extrair informações geográficas ou de grupos de usuários. Esses rótulos podem ajudar a manter o foco em classes/métodos importantes ou novos no serviço que podem acelerar a análise da causa raiz, a validação de hipóteses etc.
Dados de entrada utilizados:
- Metadados da nuvem (coletados automaticamente pelo agente de APM)
- Rótulos globais, para adicionar opcionalmente metainformações aos eventos
- Qualquer dado adicionado por meio de instrumentação manual
Problemas relacionados a implantações canário ou outras implantações parciais: em implantações de aplicações empresariais e especialmente em aplicações fornecidas como SaaS, não é incomum ter várias versões do seu software em execução simultaneamente. Rollouts canário ou estratégias de teste A/B são exemplos de implantações simultâneas de várias versões. Quando uma versão específica da aplicação se comporta mal, a correlação de APM pode ajudar a revelar a versão errônea, estreitando o escopo do problema e levando a uma determinação mais rápida da causa raiz. A versão do serviço pode ser configurada por detecção automática ou por meio de uma variável de ambiente, por exemplo, no Agente de APM Java da Elastic.
Dados de entrada utilizados:
- Versão do serviço, por meio de detecção automática ou do agente de APM
Problemas do lado do cliente: indicadores do lado do cliente como versões específicas do navegador ou tipos de dispositivos ajudam imediatamente a restringir o escopo e a causa potencial, fornecendo informações valiosas sobre a causa raiz para análise, resolução e correção.
Dados de entrada utilizados:
- Dados do cliente coletados automaticamente por meio do Agente de RUM da Elastic, como navegador e versão do sistema operacional, detalhes do dispositivo, tipo de rede etc.
Problemas com provedores de serviços terceirizados: em cenários em que provedores terceirizados, como os provedores de serviços de autenticação, estão sendo usados, as correlações de APM ajudam a identificar problemas relacionados a um provedor específico rapidamente. Isso pode ser feito usando um SDK (da Elastic ou do OpenTelemetry) para adicionar rótulos personalizados a fim de identificar os provedores de autenticação. Rótulos personalizados podem ser úteis em outros cenários semelhantes em que a instrumentação automática sozinha não será suficiente para fornecer o contexto relevante necessário para facilitar a análise da causa raiz.
Dados de entrada utilizados:
- Rótulos personalizados adicionados via SDK da Elastic ou do OpenTelemetry
- Rótulos globais
… e muitos outros casos de uso. As correlações funcionam para problemas complexos que afetam algumas partes do seu serviço, enquanto outras partes parecem estar funcionando sem problemas.
Por outro lado, há certas situações em que as correlações de APM podem não produzir os melhores resultados. Os exemplos incluem problemas generalizados que ocorrem em todos os serviços da sua aplicação, em oposição a subpopulações ou segmentos menores específicos. Em tais situações, muitas tags, rótulos ou indicadores diferentes podem estar altamente correlacionados com as transações abaixo do ideal, fornecendo pouco valor para aprofundar sua investigação. E, finalmente, se os dados relevantes não estiverem presentes ou não tiverem descritores e rótulos suficientes, a correlação poderá nem ser detectada. Consulte a seção anterior sobre entradas e dados para auxiliar nas correlações.
No entanto, para muitas das suas investigações de APM, o recurso de correlações de APM é uma ferramenta poderosa que pode ajudar a restringir rapidamente as investigações a grupos específicos de transações. Em muitos casos, essas transações correlacionadas levarão você rapidamente à causa raiz, reduzindo drasticamente o tempo de investigação.
Boa solução de problemas para você!
Recursos e informações adicionais
O recurso de correlações de APM tem disponibilidade geral a partir da versão 7.15. Clique aqui para ler as notas de lançamento sobre o recurso.
O guia do usuário e a documentação do recurso de correlações de APM estão disponíveis aqui.
Compartilhar
- Share on Twitter
Compartilhar no Twitter
- Share on LinkedIn
Compartilhar no LinkedIn
- Share on Facebook
Compartilhar no Facebook
- Share by Email
Compartilhar por e-mail
- Print this page
Imprimir