WARNING: Version 6.1 of the Elastic Stack has passed its EOL date.
This documentation is no longer being maintained and may be removed. If you are running this version, we strongly advise you to upgrade. For the latest information, see the current release documentation.
Creating Jobs in Kibana
editCreating Jobs in Kibana
editMachine learning jobs contain the configuration information and metadata necessary to perform an analytical task. They also contain the results of the analytical task.
This tutorial uses Kibana to create jobs and view results, but you can alternatively use APIs to accomplish most tasks. For API reference information, see Machine Learning APIs.
The X-Pack machine learning features in Kibana use pop-ups. You must configure your web browser so that it does not block pop-up windows or create an exception for your Kibana URL.
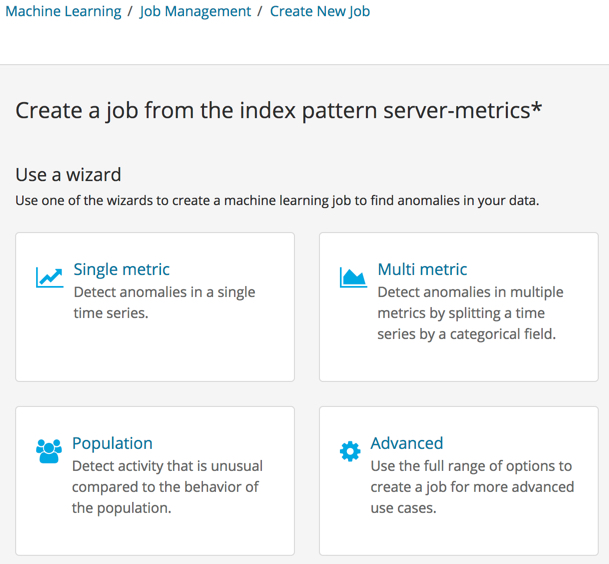
Kibana provides wizards that help you create typical machine learning jobs. For example, you can use wizards to create single metric, multi-metric, population, and advanced jobs.
To see the job creation wizards:
-
Open Kibana in your web browser. If you are running Kibana locally,
go to
http://localhost:5601/. - Click Machine Learning in the side navigation.
- Click Create new job.
-
Click the
server-metrics*index pattern.
You can then choose from a list of job wizards. For example:
If you are not certain which wizard to use, there is also a Data Visualizer that can help you explore the fields in your data.
To learn more about the sample data:
-
Click Data Visualizer.
- Select a time period that you’re interested in exploring by using the time picker in the Kibana toolbar. Alternatively, click Use full server-metrics* data to view data over the full time range. In this sample data, the documents relate to March and April 2017.
-
Optional: Change the number of documents per shard that are used in the
visualizations. There is a relatively small number of documents in the sample
data, so you can choose a value of
all. For larger data sets, keep in mind that using a large sample size increases query run times and increases the load on the cluster.
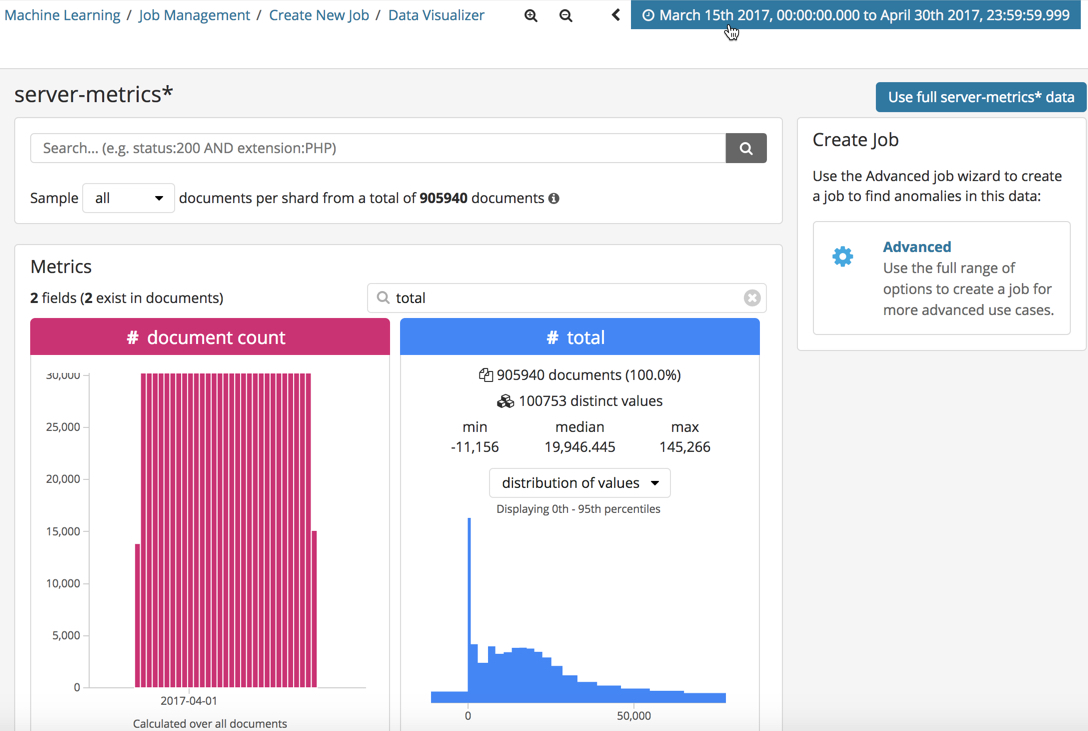
The fields in the indices are listed in two sections. The first section contains
the numeric ("metric") fields. The second section contains non-metric fields
(such as keyword, text, date, boolean, ip, and geo_point data types).
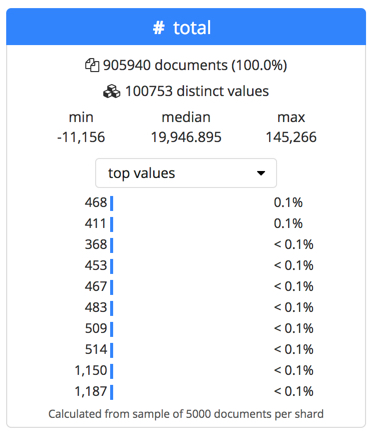
For metric fields, the Data Visualizer indicates how many documents contain the field in the selected time period. It also provides information about the minimum, median, and maximum values, the number of distinct values, and their distribution. You can use the distribution chart to get a better idea of how the values in the data are clustered. Alternatively, you can view the top values for metric fields. For example:
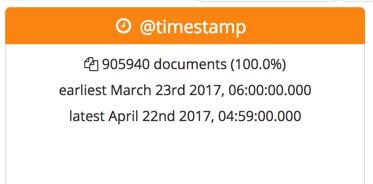
For date fields, the Data Visualizer provides the earliest and latest field values and the number and percentage of documents that contain the field during the selected time period. For example:
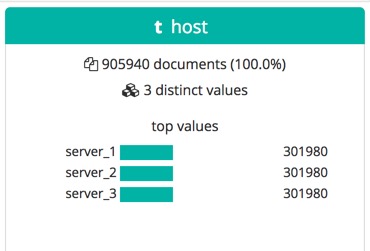
For keyword fields, the Data Visualizer provides the number of distinct values, a list of the top values, and the number and percentage of documents that contain the field during the selected time period. For example:
In this tutorial, you will create single and multi-metric jobs that use the
total, response, service, and host fields. Though there is an option to
create an advanced job directly from the Data Visualizer, we will use the
single and multi-metric job creation wizards instead.