View infrastructure metrics by resource type
editView infrastructure metrics by resource type
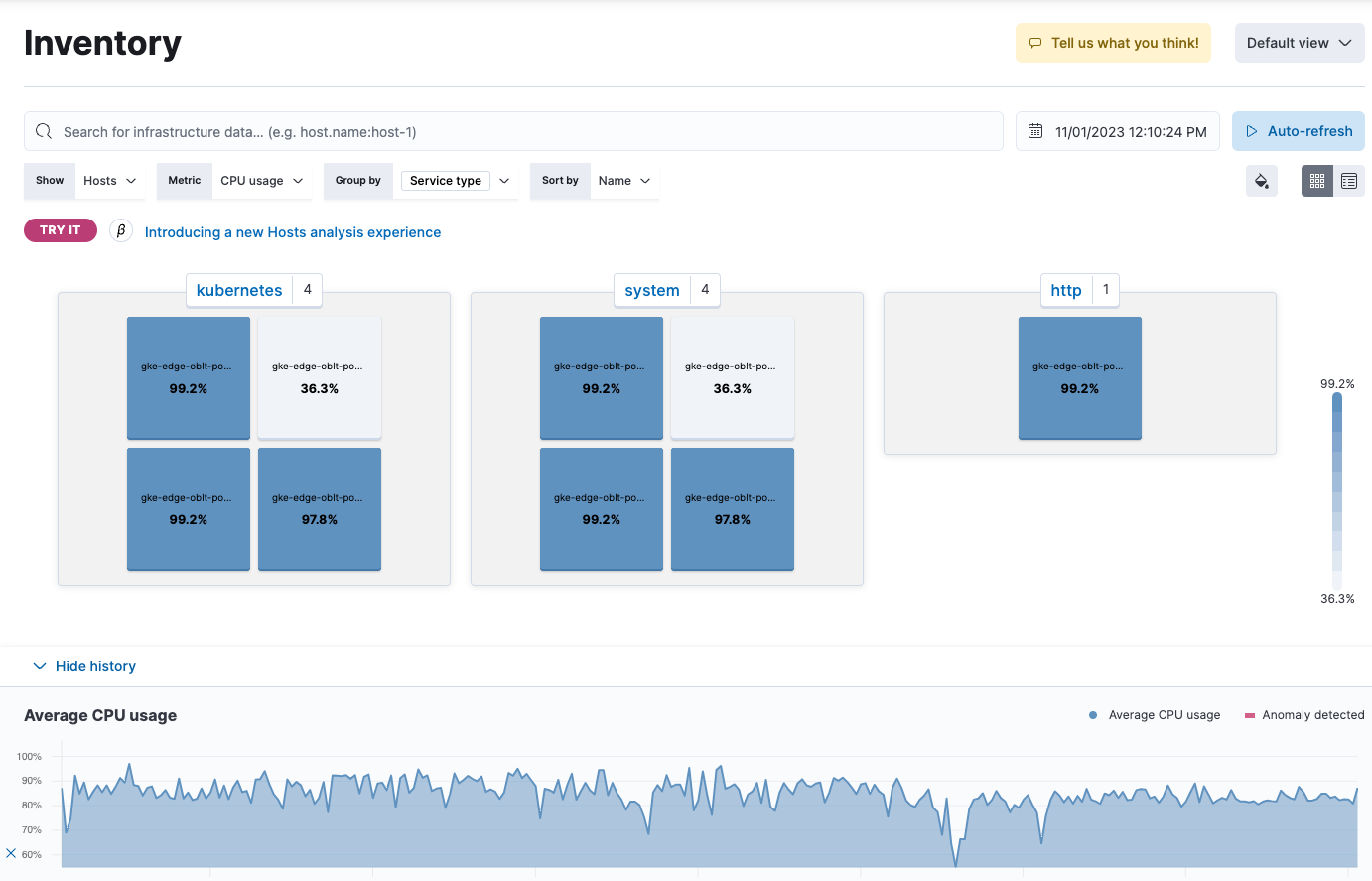
editThe Inventory page provides a metrics-driven view of your entire infrastructure grouped by the resources you are monitoring. All monitored resources emitting a core set of infrastructure metrics are displayed to give you a quick view of the overall health of your infrastructure.
To access this page from the main Kibana menu, go to Observability → Infrastructure → Inventory.
To learn more about the metrics shown on this page, refer to the Metrics reference documentation.
If there are no metrics to display, Kibana prompts you to add a metrics integration. Click Add a metrics integration to get started. If you want to add more data in the future, click Add data from any page in the Infrastructure app.
Need help getting started? Follow the steps in Get started with logs and metrics.
Filter the Inventory view
editTo get started with your analysis, select the type of resources you want to show in the high-level view. From the Show menu, select one of the following:
- Hosts (the default)
- Kubernetes Pods
- Docker Containers
- AWS, which includes EC2 instances, S3 buckets, RDS databases, and SQS queues
When you hover over each resource in the waffle map, the metrics specific to that resource are displayed.
You can sort by resource, group the resource by specific fields related to it, and sort by either name or metric value. For example, you can filter the view to display the memory usage of your Kubernetes pods, grouped by namespace, and sorted by the memory usage value.
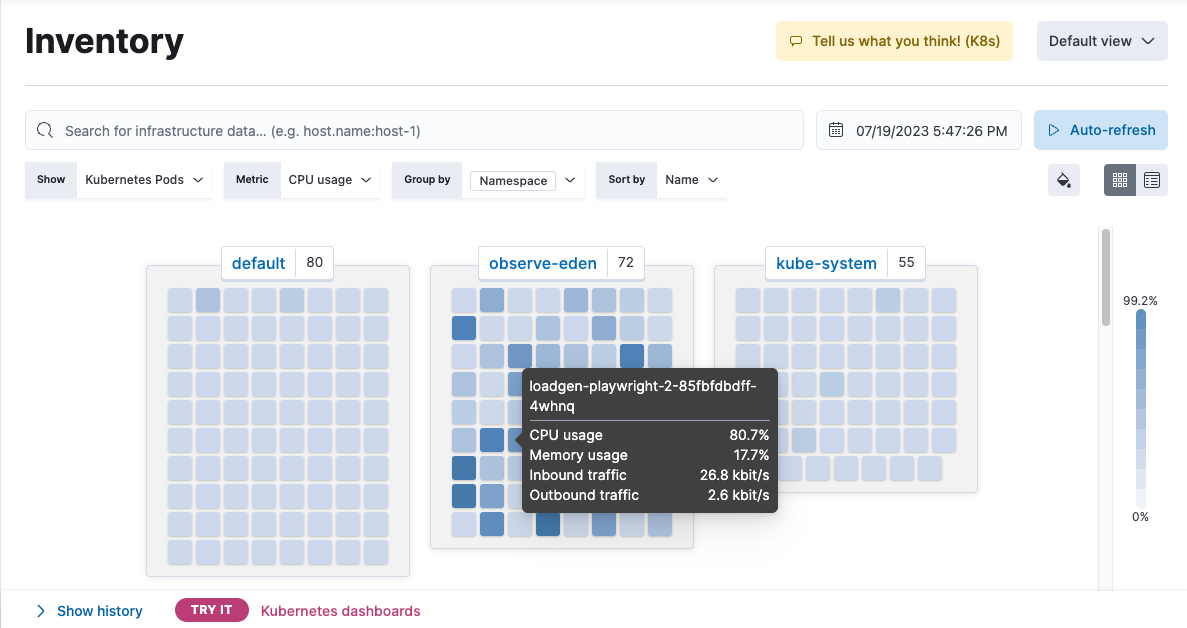
You can also use the search bar to create structured queries using Kibana Query Language.
For example, enter host.hostname : "host1" to view only the information for host1.
To examine the metrics for a specific time, use the time filter to select the date and time.
View host metrics
editBy default the Inventory page displays a waffle map that shows the hosts you
are monitoring and the current CPU usage for each host.
Alternatively, you can click the Table view icon ![]() to switch to a table view.
to switch to a table view.
Without leaving the Inventory page, you can view enhanced metrics relating to each host running in your infrastructure. On the waffle map, select a host to display the host details overlay.
To expand the overlay and view more detail, click Open as page in the upper-right corner.
The host details overlay contains the following tabs:
Overview
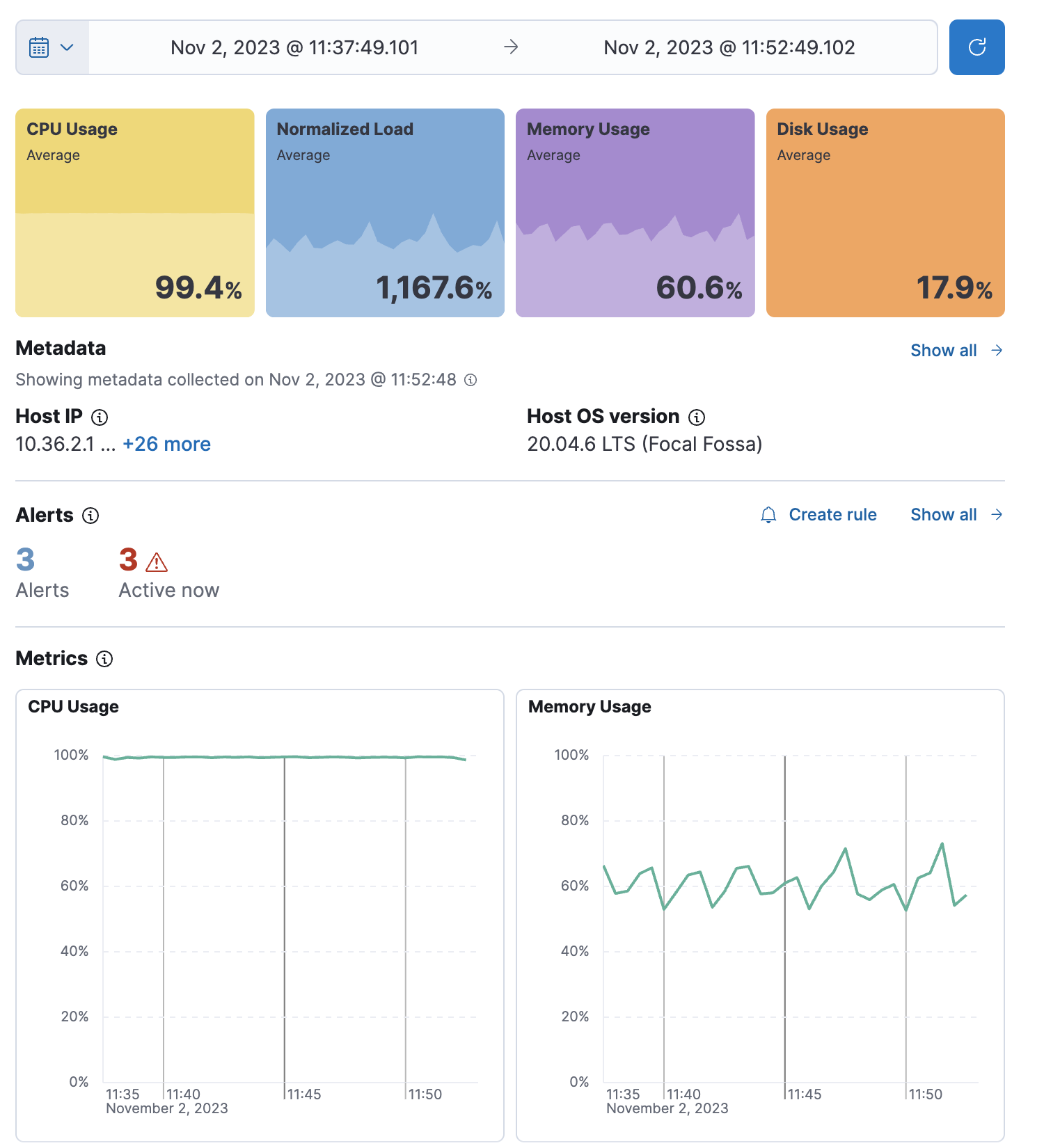
The Overview tab displays metrics about the selected host, including CPU usage, normalized load, memory usage, disk usage, network traffic, and the log rate.
Change the time range to view metrics over a specific period of time.
Hover over a specific time period on a chart to compare the various metrics at that given time.
Metadata
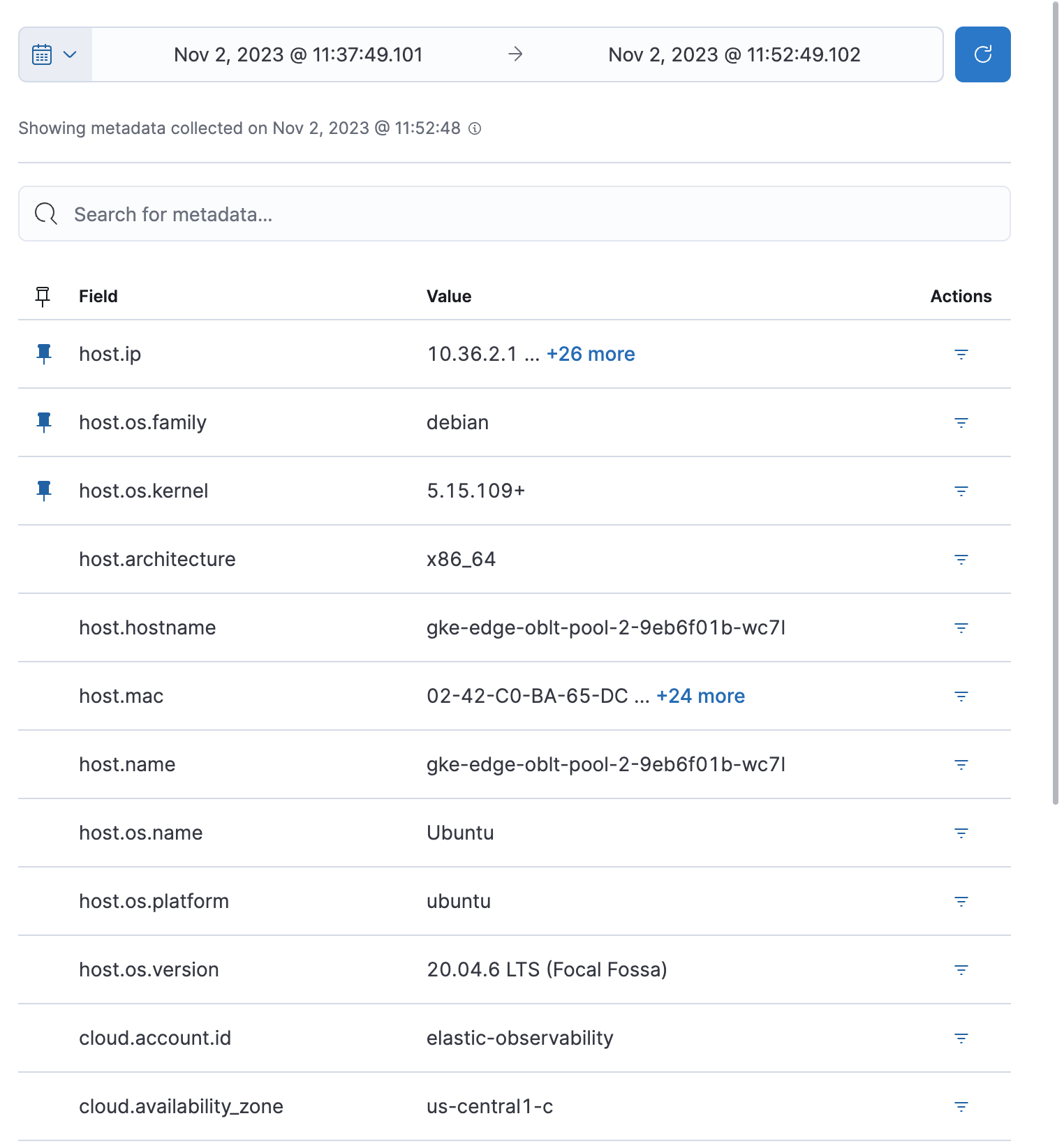
The Metadata tab lists all the meta information relating to the host:
- Host information
- Cloud information
- Agent information
All of this information can help when investigating events—for example, filtering by operating system or architecture.
Processes
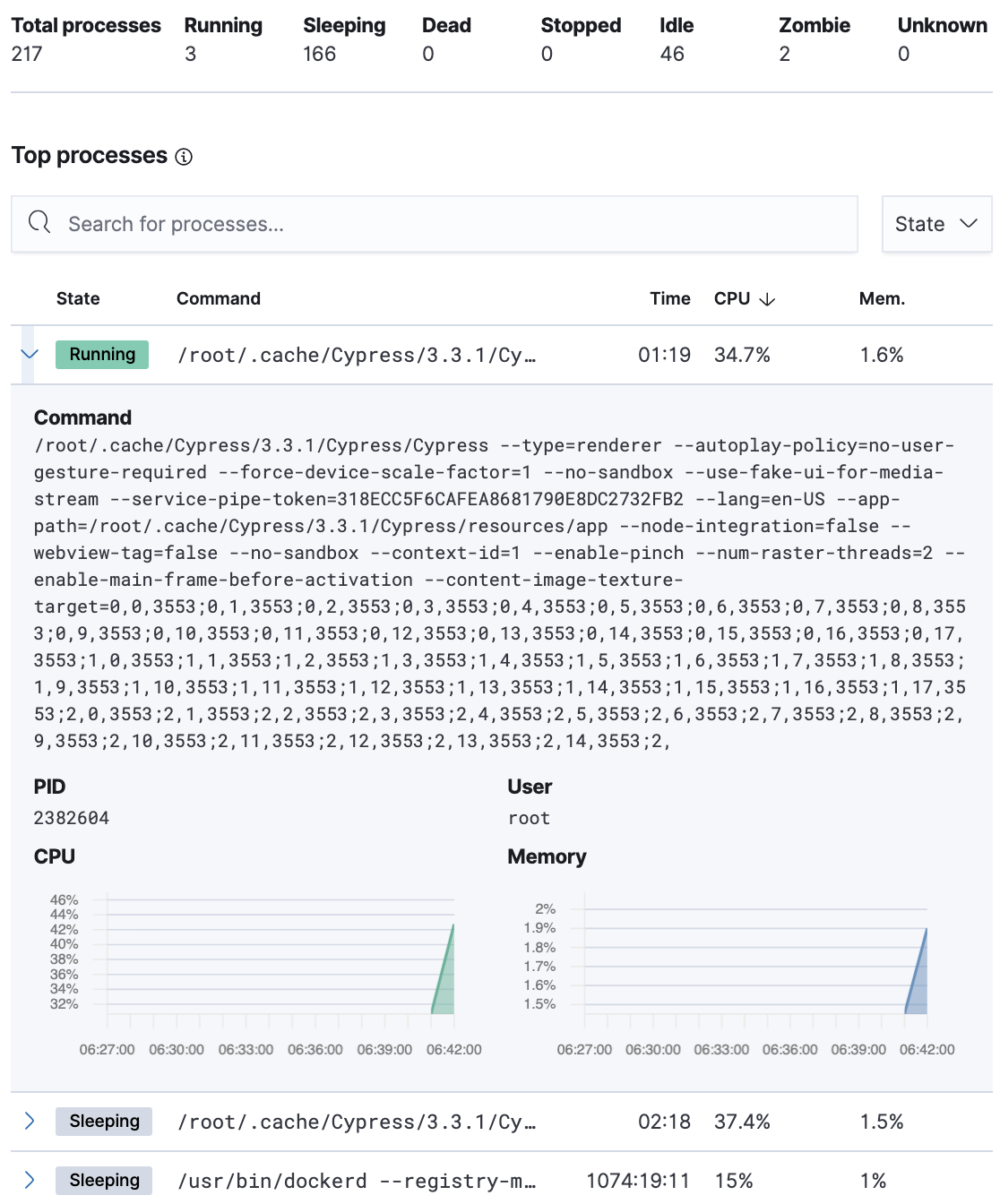
The Processes tab lists the total number of processes (system.process.summary.total) running on the host,
along with the total number of processes in these various states:
-
Running (
system.process.summary.running) -
Sleeping (
system.process.summary.sleeping) -
Stopped (
system.process.summary.stopped) -
Idle (
system.process.summary.idle) -
Dead (
system.process.summary.dead) -
Zombie (
system.process.summary.zombie) -
Unknown (
system.process.summary.unknown)
The processes listed in the Top processes table are based on an aggregation of the top CPU and the top memory consuming processes.
The number of top processes is controlled by process.include_top_n.by_cpu and process.include_top_n.by_memory.
Command |
Full command line that started the process, including the absolute path to the executable, and all the arguments ( |
PID |
Process id ( |
User |
User name ( |
CPU |
The percentage of CPU time spent by the process since the last event ( |
Time |
The time the process started ( |
Memory |
The percentage of memory ( |
State |
The current state of the process and the total number of processes ( |
Universal Profiling
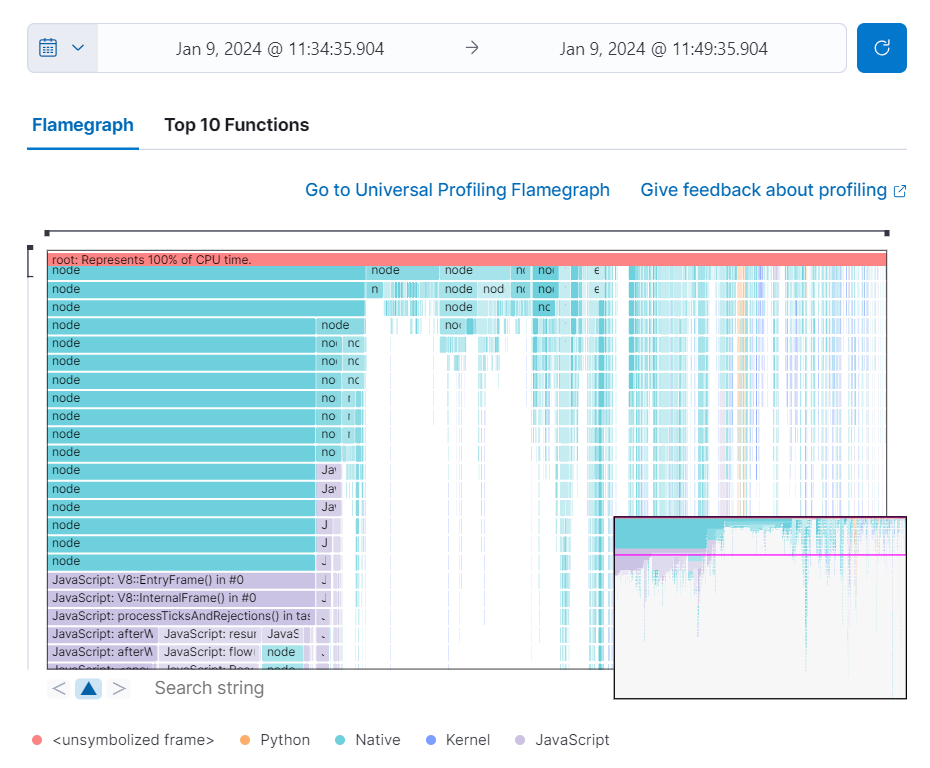
The Universal Profiling tab shows CPU usage down to the application code level. From here, you can find the sources of resource usage, and identify code that can be optimized to reduce infrastructure costs. The Universal Profiling tab has the following views.
Flamegraph |
A visual representation of the functions that consume the most resources. Each rectangle represents a function. The rectangle width represents the time spent in the function. The number of stacked rectangles represents the stack depth, or the number of functions called to reach the current function. |
Top 10 Functions |
A list of the most expensive lines of code on your host. See the most frequently sampled functions, broken down by CPU time, annualized CO2, and annualized cost estimates. |
For more on Universal Profiling, refer to the Universal Profiling docs.
Logs
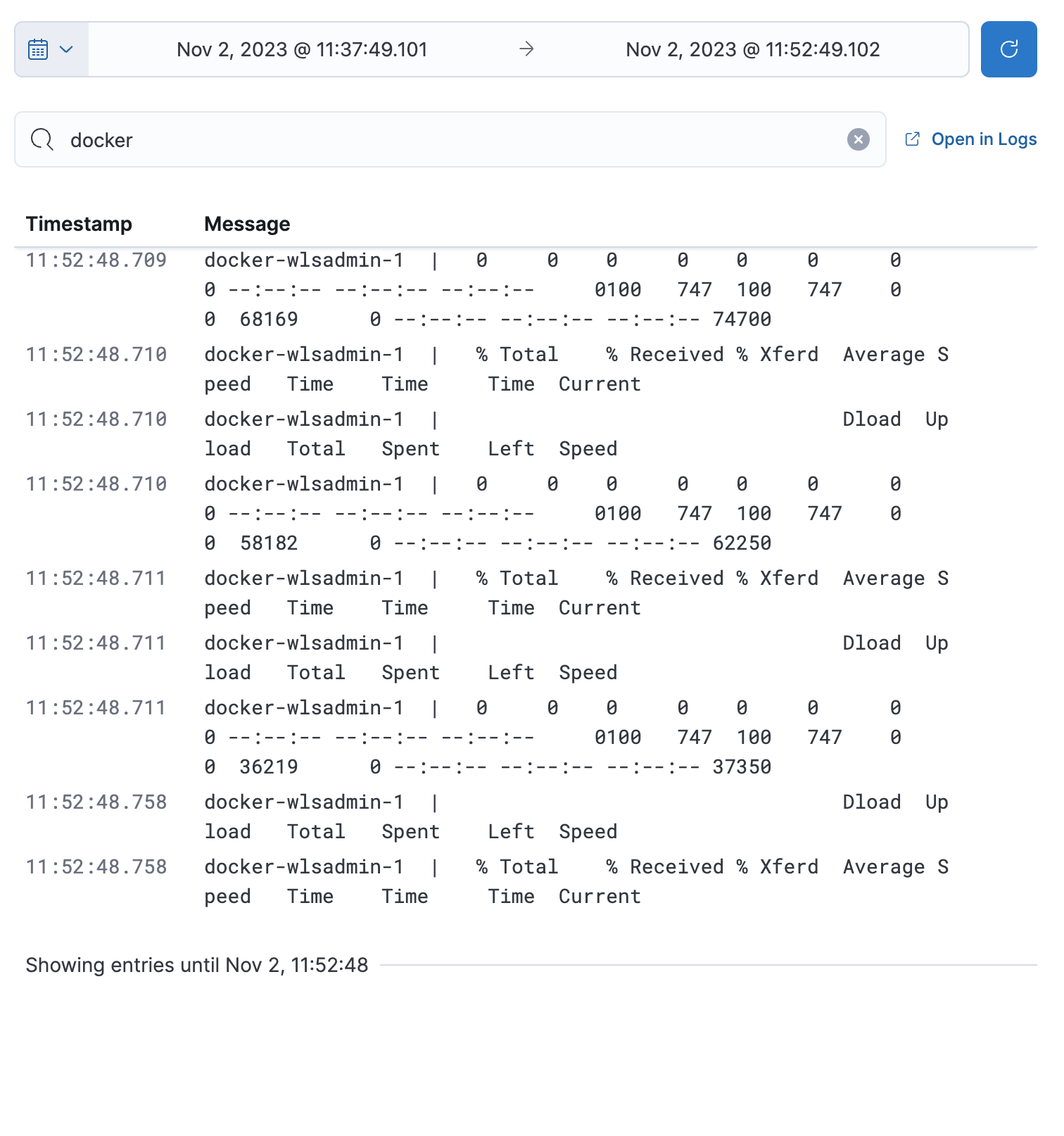
The Logs tab displays logs relating to the host that you have selected. By default, the logs tab displays the following columns.
Timestamp |
The timestamp of the log entry from the |
Message |
The message extracted from the document.
The content of this field depends on the type of log message.
If no special log message type is detected, the Elastic Common Schema (ECS)
base field, |
You can customize the logs view by adding a column for an arbitrary field you would like to filter by. For more information, refer to Customize Stream. To view the logs in the Logs app for a detailed analysis, click Open in Logs.
Anomalies
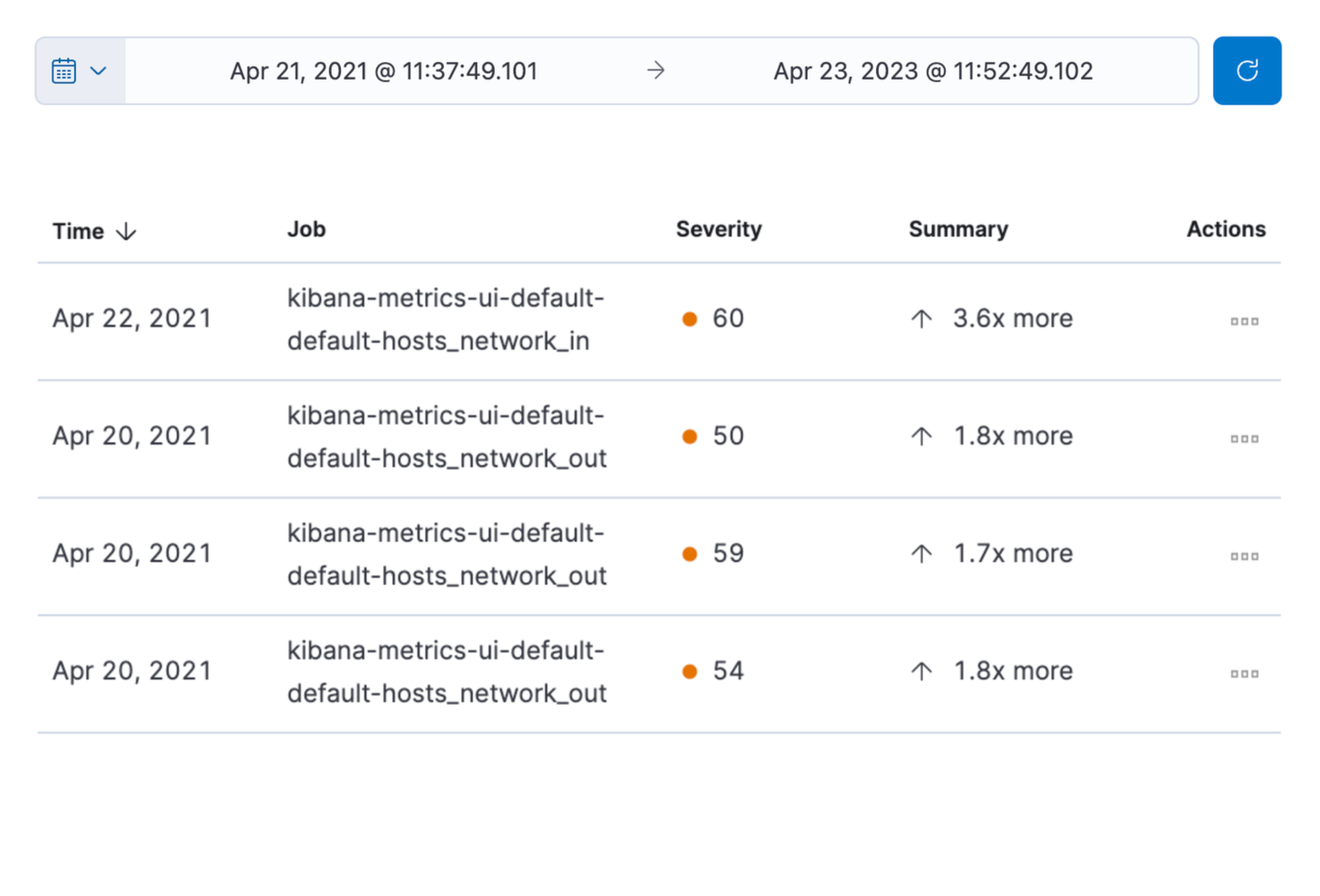
The Anomalies table displays a list of each single metric anomaly detection job for the specific host. By default, anomaly jobs are sorted by time, showing the most recent jobs first.
Along with the name of each anomaly job, detected anomalies with a severity score equal to 50, or higher, are listed. These scores represent a severity of "warning" or higher in the selected time period. The summary value represents the increase between the actual value and the expected ("typical") value of the host metric in the anomaly record result.
To drill down and analyze the metric anomaly, select Actions → Open in Anomaly Explorer to view the Anomaly Explorer in Machine Learning. You can also select Actions → Show in Inventory to view the host Inventory page, filtered by the specific metric.
Osquery
You must have an active Elastic Agent with an assigned agent policy that includes the Osquery Manager integration and have Osquery Kibana privileges as a user.
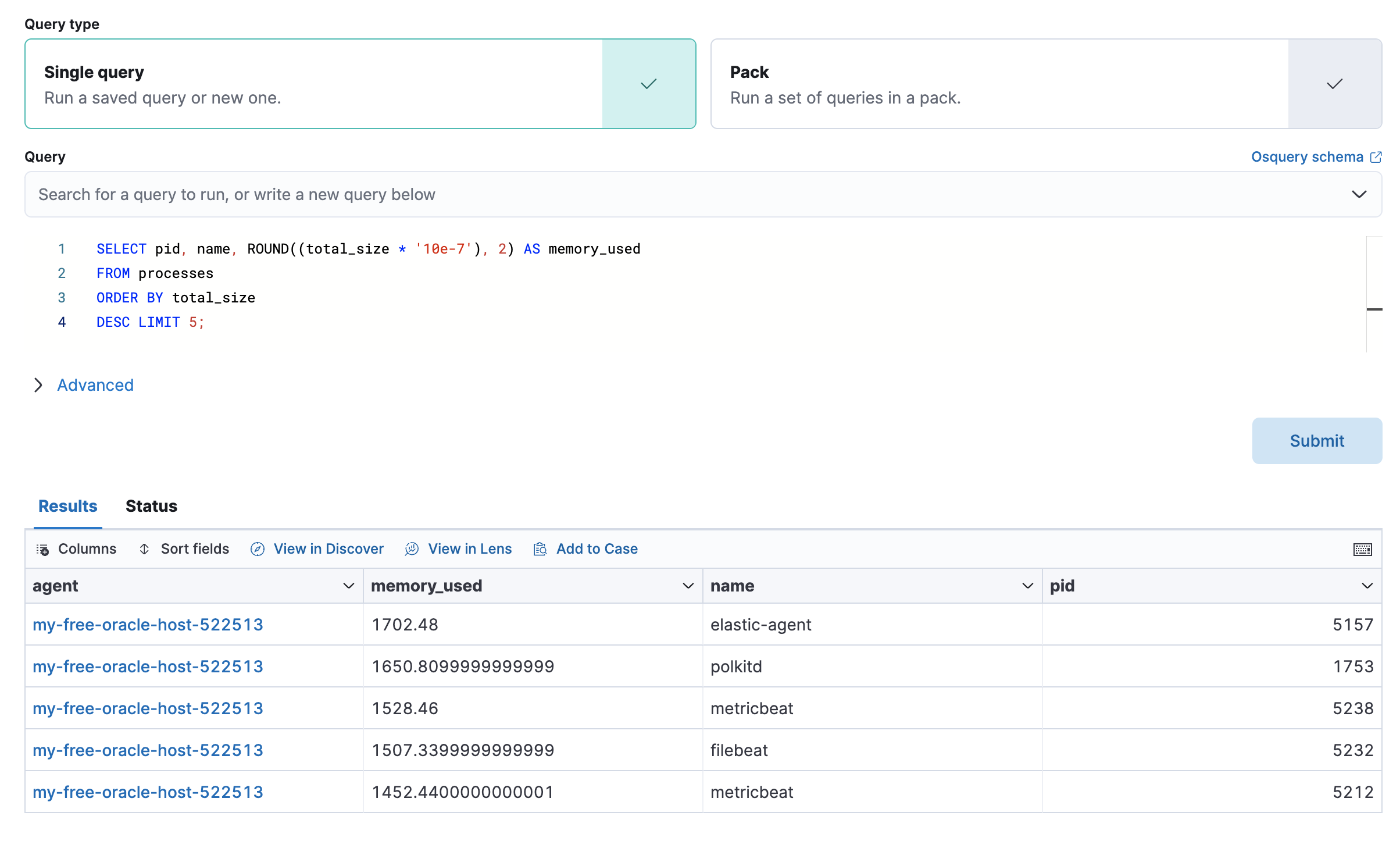
The Osquery tab allows you to build SQL statements to query your host data. You can create and run live or saved queries against the Elastic Agent. Osquery results are stored in Elasticsearch so that you can use the Elastic Stack to search, analyze, and visualize your host metrics. To create saved queries and add scheduled query groups, refer to Osquery.
To view more information about the query, click the Status tab. A query status can result in
success, error (along with an error message), or pending (if the Elastic Agent is offline).
Other options include:
- View in Discover to search, filter, and view information about the structure of host metric fields. To learn more, refer to Discover.
- View in Lens to create visualizations based on your host metric fields. To learn more, refer to Lens.
- View the results in full screen mode.
- Add, remove, reorder, and resize columns.
- Sort field names in ascending or descending order.
These metrics are also available when viewing hosts on the Hosts page.
View metrics for other resources
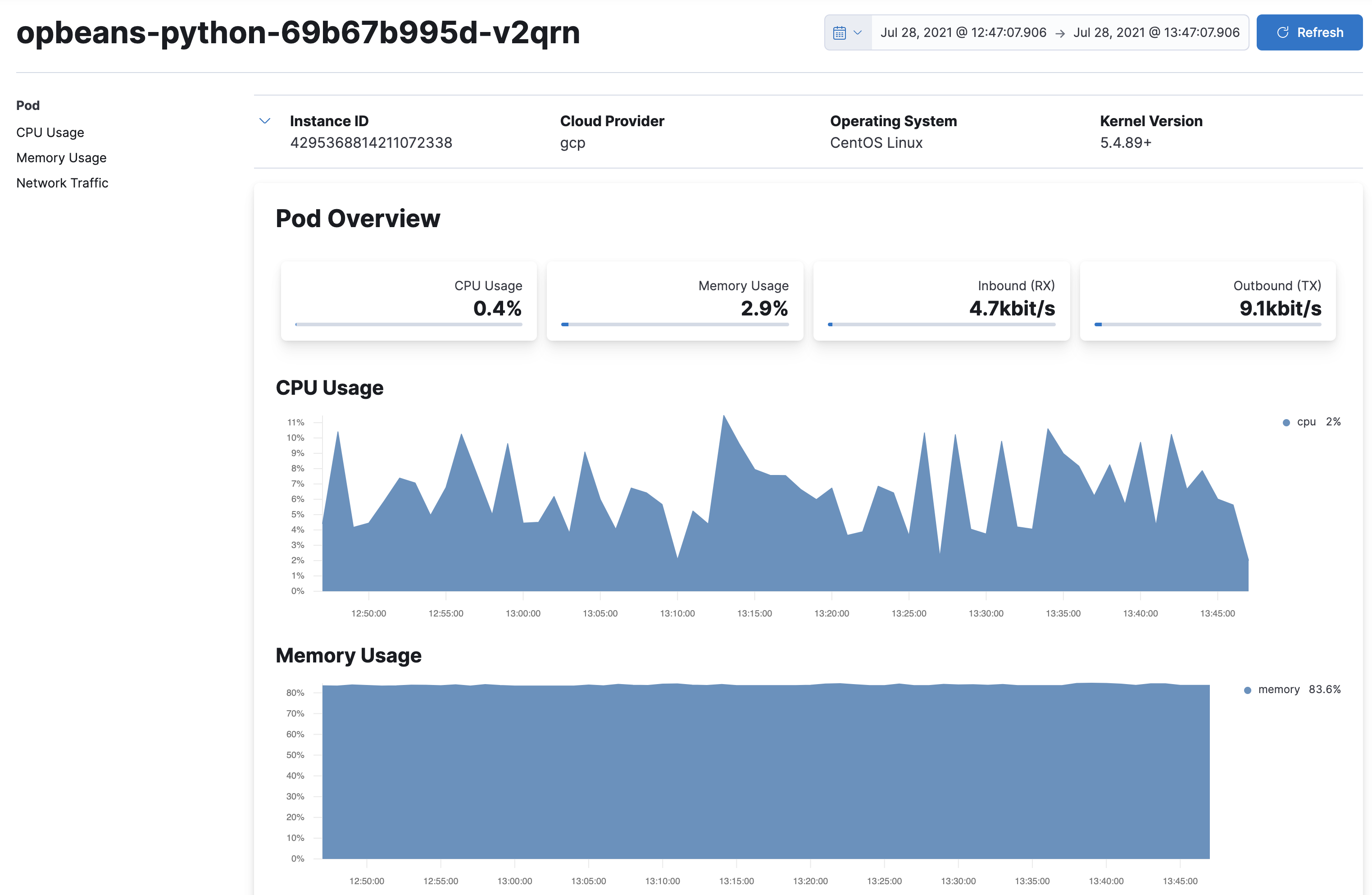
editWhen you have searched and filtered for a specific resource, you can drill down to analyze the metrics relating to it. For example, when viewing Kubernetes Pods in the high-level view, click the Pod you want to analyze and select Kubernetes Pod metrics to see detailed metrics:
Add custom metrics
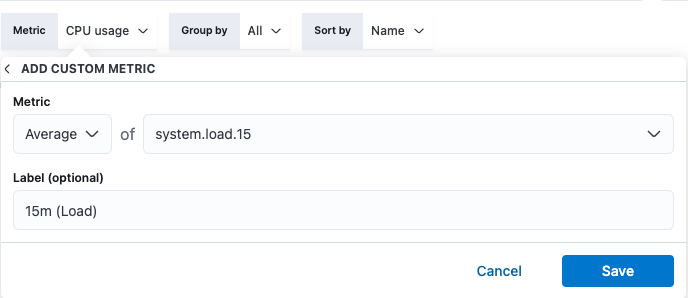
editIf the predefined metrics displayed on the Inventory page for each resource are not sufficient for your specific use case, you can add and define custom metrics.
Select your resource, and from the Metric filter menu, click Add metric.
Integrate with Logs, Uptime, and APM
editDepending on the features you have installed and configured, you can view logs, traces, or uptime information relating to a specific resource. For example, in the high-level view, when you click a Kubernetes Pod resource, you can choose:
- Kubernetes Pod logs to view corresponding logs in the Logs app.
- Kubernetes Pod APM traces to view corresponding APM traces in the APM app.
- Kubernetes Pod in Uptime to view related uptime information in the Uptime app.