Monitor Amazon Cloud Compute (EC2)
editMonitor Amazon Cloud Compute (EC2)
editElastic Compute Cloud (Amazon EC2) enables you to provision compute resources, on demand, in the form of virtual servers called instances. A range of instance types are available with different CPU, memory, storage, and networking capacity. Popular preconfigured Amazon Machine Images (AMIs) are available with Microsoft Windows and Linux distributions like Ubuntu, Red Hat Enterprise Linux, CentOS, SUSE, Debian, and Amazon Linux. Amazon offers Amazon Elastic Block Store (EBS) volumes to EC2 instances for persistent block-level storage. EC2 can also be used with other AWS services like Auto Scaling.
Amazon EC2 instances can be run in various locations. The location is composed of AWS Regions and Availability Zones (AZ). AZs are distinct locations that are insulated from failures to other AZs, but provide lower latency network connectivity. Each region is geographically dispersed and can consist of one or more AZs.
Like most AWS services, Amazon EC2 sends its metrics to Amazon CloudWatch. The Elastic Amazon EC2 integration collects metrics from Amazon CloudWatch using Elastic Agent.
CloudWatch, by default, uses basic monitoring that publishes metrics at five-minute intervals. You can enable detailed monitoring to increase that resolution to one-minute, at an additional cost. To learn how to enable detailed monitoring, refer to the Amazon EC2 documentation.
CloudWatch does not expose metrics related to EC2 instance memory. You can install Elastic Agent on the EC2 instances to collect detailed system metrics.
Get started
editTo collect EC2 metrics, you typically need to install the Elastic Amazon EC2 integration and deploy an Elastic Agent.
Expand the quick guide to learn how, or skip to the next section if your data is already in Elasticsearch.
Quick guide: Add data
Elastic Agent is currently the preferred way to add EC2 metrics. For other ways, refer to Adding data to Elasticsearch.
Dashboards
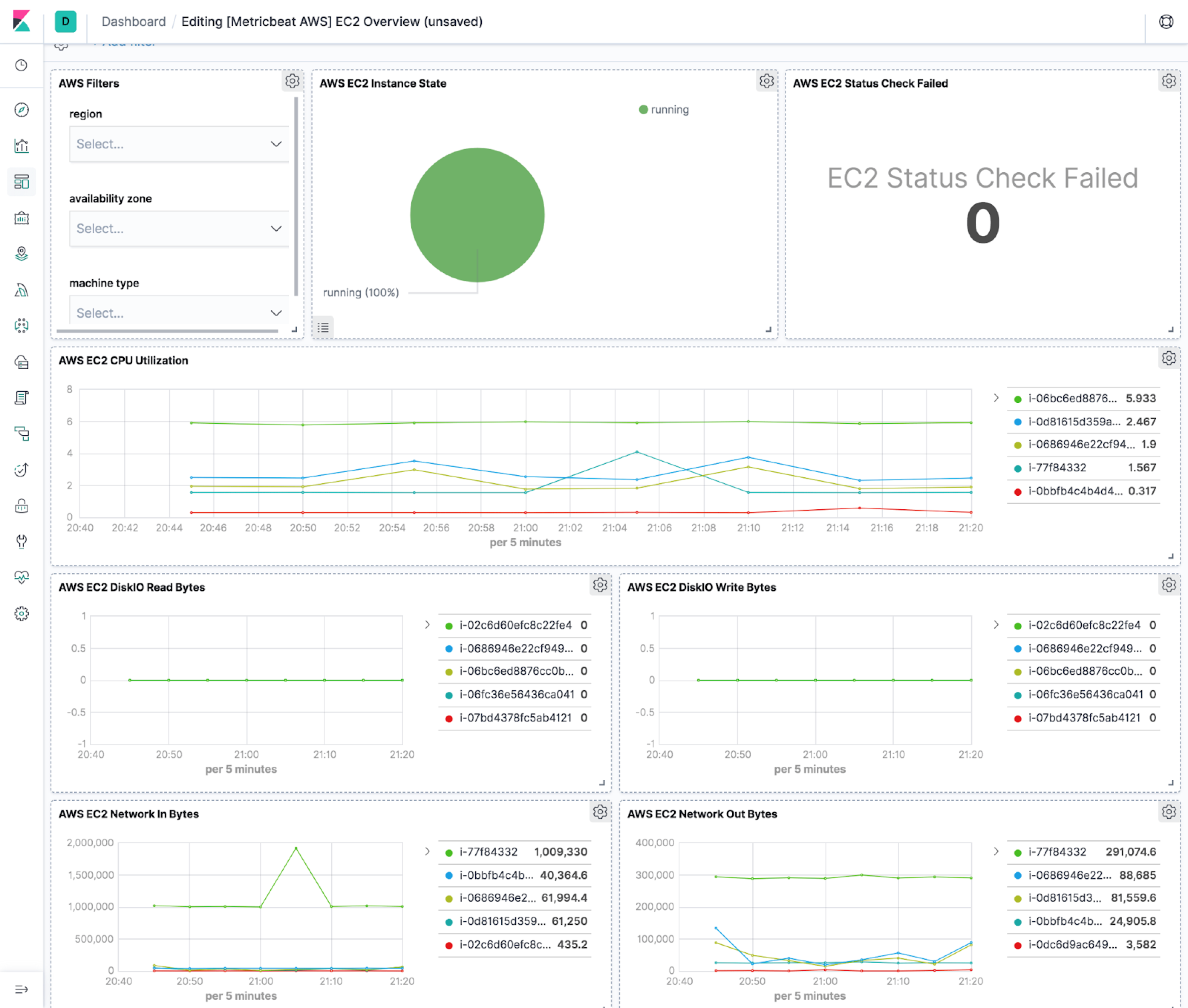
editKibana provides a full data analytics platform with out-of-the-box dashboards that you can clone and enhance to satisfy your custom visualization use cases. For example, to see an overview of your EC2 instance metrics in Kibana, go to the Dashboard app and navigate to the [Metrics AWS] EC2 Overview dashboard.
Metrics to watch
editAmazon EC2 provides a large selection of instance types. Monitoring key metrics about your instances is a cost-effective way to determine whether to upgrade, change, or downsize your instances.
This section lists the key metrics that you should watch, organized by category. For a full description of exported fields, refer to the Amazon EC2 integration docs.
CPU utilization
editHere are the key CPU utilization metrics you should monitor and what to look for in these metrics:
-
aws.ec2.metrics.CPUUtilization.avg -
This measures the percentage of allocated EC2 compute units that are currently in use on the instance. Tracking this metric helps ensure that the instance is sized appropriately for your workload. If you see degraded application performance alongside continuously high levels of CPU usage (without any accompanying constraints on network, disk I/O, or memory), CPU may be a resource bottleneck. You can review application-level data using Application Performance Monitoring and/or potentially switch to using an instance type with more vCPU.
Very low usage of CPU utilization across your EC2 instances (for example, less than 5% for multiple weeks) can also help you determine if your instances are underutilized for your workload and potentially can be replaced with a smaller instance type to save cost.
-
aws.ec2.metrics.CPUCreditBalance.avg&aws.ec2.metrics.CPUCreditUsage.avg -
The T instance family provides a baseline CPU performance with the ability to burst above the baseline. These instances are ideal for applications that are not generally CPU intensive but may benefit from higher CPU capacity for brief intervals. Credits are earned any time the instance is running below its baseline CPU performance level.
Amazon EC2 CPU credit metrics help keep track of your available balance and usage so that you are aware of possible charges as a result of extended bursting. Monitoring your instances’ credit usage can help you identify if you might need to switch to an instance type that is optimized for CPU-intensive workloads.
-
aws.ec2.metrics.CPUSurplusCreditBalance.avg&aws.ec2.metrics.CPUSurplusCreditsCharged.avg -
A burstable performance instance configured as unlimited can sustain high CPU utilization for any period of time whenever required. T4g, T3a, and T3 instances launch as unlimited by default. If the average CPU usage over a 24-hour period exceeds the baseline, you incur charges for surplus credits.
The CPU surplus credit balance metric tracks the accumulated balance. The CPU surplus credit charged measures extra credits that will result in additional charges.
Disk I/O
editAmazon EC2 provides multiple data storage options for your instances including Amazon EC2 instance store and Amazon Elastic Block Store (Amazon EBS).
An instance store provides temporary block-level storage for your instance and is usually used for temporary storage of information such as buffers, caches, scratch data, and other temporary content. The data in an instance store persists only during the lifetime of its associated instance. When you stop, hibernate, or terminate an instance, every block of storage in the instance store is reset.
For valuable, long-term data, use more durable data storage, such as Amazon EBS. EBS volumes attached to an instance are exposed as storage volumes that persist independently from the life of the instance. EBS volumes are suited for use as the primary storage for file systems or databases.
CloudWatch EC2 disk I/O metrics only collect data from instance store volumes.
CloudWatch EC2 namespace does offer a set of Amazon EBS disk I/O metrics, but these are only available for instances built on the Nitro System. For all other instance types, disk I/O for EBS volumes must be monitored via the Elastic Amazon EBS integration.
Here are the key disk I/O metrics you should monitor and what to look for:
-
aws.ec2.metrics.DiskReadBytes.sum&aws.ec2.metrics.DiskWriteBytes.sum -
aws.ec2.metrics.DiskReadBytes.rate&aws.ec2.metrics.DiskWriteBytes.rate -
Disk read and disk write bytes measure the number of bytes read from and written to the instance store volumes attached to the EC2 instance. Monitoring these metrics can help you understand application-level issues. Too much consistent reading of data from disk may indicate that your application could benefit from a caching layer. Lots of disk write for a long term could mean request queuing and potential application slowdowns if the disk speed is not fast enough to match the use case.
Disk read bytes per second and disk write bytes per second provide the average read/write data size for the specified period of time.
-
aws.ec2.metrics.DiskReadOps.sum&aws.ec2.metrics.DiskWriteOps.sum -
aws.ec2.metrics.DiskReadOps.rate&aws.ec2.metrics.DiskWriteOps.rate -
Disk read/write operations count gives you insight into the average number of read/write operations, which can help you determine if degraded performance is the result of consistently high I/O operations per second (IOPS) causing bottlenecks as disk requests become queued. If your instance volumes are HDD, you can consider a move to faster SSD disks.
Disk read/write operations count per second provides the average read/write IOPS for the specified period of time.
Network
editNetwork bandwidth is a key resource in cloud services. The available network bandwidth of an EC2 instance depends on the number of vCPUs that the instance has. It also depends upon the destination of the traffic, wherein full network bandwidth is available to the instance within the region but only 50% to other regions, based on use cases. The bandwidth can range from 5 to 25 Gbps. There is also a limit on maximum transmission unit (MTU), or the largest amount of data that can be sent in a single packet can range from 1,300 to 1,500 bytes. The current generation instance types however do support jumbo frames with up to 9001 MTU thus increasing the payload size per packet and potentially reducing overhead for applications that transmit large amounts of data.
AWS provides various configuration options like placement groups and enhanced networking to optimize network performance.
Here are the key network metrics you should monitor and what to look for:
-
aws.ec2.metrics.NetworkIn.sum&aws.ec2.metrics.NetworkOut.sum -
aws.ec2.metrics.NetworkIn.rate&aws.ec2.metrics.NetworkOut.rate -
These metrics report network throughput, in bytes, of your EC2 instance. Any network drops or fluctuations can potentially be correlated to the application metrics to find the root cause of possible issues. Any throughput limit may indicate that the instance type may be mismatched with the application needs, especially for data intensive applications.
When looking at a set of EC2 instance data, if you see a considerable difference in network traffic load, you may require a load balancer to distribute the load more evenly across the related instances and be able to achieve better performance.
Status check
editHere are the key status check metrics you should monitor and what to look for:
-
aws.ec2.metrics.StatusCheckFailed.avg -
This check reports whether the instance has passed both the instance status check and the system status check. This check returns 0 (passed) if an instance passes the system status check or 1 (failed) if it fails.
The Elastic Amazon EC2 integration also collects important cloud metadata like instance name (
cloud.instance.name=elastic-package-test-33138), instance id (cloud.instance.id=i-0de58890d94dda2e3), account name (cloud.account.name=elastic-beats), account id (cloud.account.id=428152502467), provider (cloud.provider=aws), region (cloud.region=us-east-1), availability zone (cloud.availability_zone=us-east-1c), and instance type (cloud.machine.type=t1.micro). This metadata helps in grouping and filtering collected data and helps drive various usage and performance trends across a set of related EC2 instances.The Elastic EC2 integration comes with a default dashboard that shows key metrics like status check, CPU utilization, Disk I/O, and network throughput. It also provides filtering for region, availability zone, and machine type.
-
aws.ec2.metrics.StatusCheckFailed_Instance.avg -
This check monitors the software and network configuration of the instance. Problems that can cause instance status checks to fail may include: incorrect networking or startup configuration, exhausted memory, corrupted file system, incompatible kernel, and so on. When an instance status check fails, you typically must address the problem yourself. You may need to reboot the instance or make instance configuration changes. To troubleshoot instances with failed status checks, refer to the Amazon EC2 documentation.
This check returns 0 (passed) if an instance passes the system status check or 1 (failed) if it fails.
-
aws.ec2.metrics.StatusCheckFailed_System.avg -
This status check detects underlying problems with your instance that require AWS involvement to repair. Problems that can cause system status checks to fail include: loss of network connectivity, loss of system power, and hardware/software issues on the physical host. For instances backed by Amazon EBS, you can stop and start the instance yourself, which in most cases results in the instance being migrated to a new host. For instances backed by an instance store, you can terminate and replace the instance. Note that instance store volumes are ephemeral, and all data is lost when the instance is stopped.
This check returns 0 (passed) if an instance passes the system status check or 1 (failed) if it fails.