Introduction to supervised learning
editIntroduction to supervised learning
editThis functionality is in beta and is subject to change. The design and code is less mature than official GA features and is being provided as-is with no warranties. Beta features are not subject to the support SLA of official GA features.
Elastic supervised learning enables you to train a machine learning model based on training examples that you provide. You can then use your model to make predictions on new data. This page summarizes the end-to-end workflow for training, evaluating and deploying a model. It gives a high-level overview of the steps required to identify and implement a solution using supervised learning.
The workflow for supervised learning consists of the following stages:
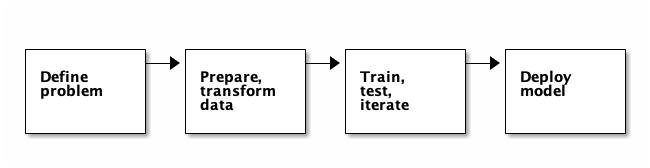
These are iterative stages, meaning that after evaluating each step, you might need to make adjustments before you move further.
Define the problem
editIt’s important to take a moment and think about where machine learning can be most impactful. Consider what type of data you have available and what value it holds. The better you know the data, the quicker you will be able to create machine learning models that generate useful insights. What kinds of patterns do you want to discover in your data? What type of value do you want to predict: a category, or a numerical value? The answers help you choose the type of analysis that fits your use case.
After you identify the problem, consider which of the machine learning features are most likely to help you solve it. Supervised learning requires a data set that contains known values that the model can be trained on. Unsupervised learning – like anomaly detection or outlier detection – does not have this requirement.
Elastic Stack provides the following types of supervised learning:
- regression: predicts continuous, numerical values like the response time of a web request.
- classification: predicts discrete, categorical values like whether a DNS request originates from a malicious or benign domain.
Prepare and transform data
editYou have defined the problem and selected an appropriate type of analysis. The next step is to produce a high-quality data set in Elasticsearch with a clear relationship to your training objectives. If your data is not already in Elasticsearch, this is the stage where you develop your data pipeline. If you want to learn more about how to ingest data into Elasticsearch, refer to the Ingest node documentation.
Regression and classification are supervised machine learning techniques, therefore you must supply a labelled data set for training. This is often called the "ground truth". The training process uses this information to identify relationships among the various characteristics of the data and the predicted value. It also plays a critical role in model evaluation.
An important requirement is a data set that is large enough to train a model. For example, if you would like to train a classification model that decides whether an email is a spam or not, you need a labelled data set that contains enough data points from each possible category to train the model. What counts as "enough" depends on various factors like the complexity of the problem or the machine learning solution you have chosen. There is no exact number that fits every use case; deciding how much data is acceptable is rather a heuristic process that might involve iterative trials.
Before you train the model, consider preprocessing the data. In practice, the type of preprocessing depends on the nature of the data set. Preprocessing can include, but is not limited to, mitigating redundancy, reducing biases, applying standards and/or conventions, data normalization, and so on.
Regression and classification require specifically structured source data: a two dimensional tabular data structure. For this reason, you might need to transform your data to create a data frame which can be used as the source for these types of data frame analytics.
Train, test, iterate
editAfter your data is prepared and transformed into the right format, it is time to train the model. Training is an iterative process — every iteration is followed by an evaluation to see how the model performs.
The first step is defining the features – the relevant fields in the data set – that will be used for training the model. By default, all the fields with supported types are included in regression and classification automatically. However, you can optionally exclude irrelevant fields from the process. Doing so makes a large data set more manageable, reducing the computing resources and time required for training.
Next you must define how to split your data into a training and a test set. The test set won’t be used to train the model; it is used to evaluate how the model performs. There is no optimal percentage that fits all use cases, it depends on the amount of data and the time you have to train. For large data sets, you may want to start with a low training percent to complete an end-to-end iteration in a short time.
During the training process, the training data is fed through the learning algorithm. The model predicts the value and compares it to the ground truth then the model is fine-tuned to make the predictions more accurate.
Once the model is trained, you can evaluate how well it predicts previously unseen data with the model generalization error. There are further evaluation types for both regression and classification analysis which provide metrics about training performance. When you are satisfied with the results, you are ready to deploy the model. Otherwise, you may want to adjust the training configuration or consider alternative ways to preprocess and represent your data.
Deploy model
editYou have trained the model and are satisfied with the performance. The last step is to deploy your trained model and start using it on new data.
The Elastic machine learning feature called inference enables you to make predictions for new data either by using it as a processor in an ingest pipeline, in a continuous transform or as an aggregation at search time. When new data comes into your ingest pipeline or you run a search on your data with an inference aggregation, the model is used to infer against the data and make predictions on it.
Next steps
edit- Read more about how to transform you data into an entity-centric index.
- Consult the documentation to learn more about regression and classification.
- Learn how to evaluate regression and classification models.
- Find out how to deploy your model by using inference.