Common Issues
editCommon Issues
editThis page describes how to resolve common problems you might encounter with Alerting.
Rules with small check intervals run late
editProblem
Rules with a small check interval, such as every two seconds, run later than scheduled.
Solution
Rules run as background tasks at a cadence defined by their check interval.
When a Rule check interval is smaller than the Task Manager poll_interval, the rule will run late.
Either tweak the Kibana Task Manager settings or increase the check interval of the rules in question.
For more details, see Tasks with small schedule intervals run late.
Rules with the inconsistent cadence
editProblem
Scheduled rules run at an inconsistent cadence, often running late.
Actions run long after the status of a rule changes, sending a notification of the change too late.
Solution
Rules and actions run as background tasks by each Kibana instance at a default rate of ten tasks every three seconds.
When diagnosing issues related to alerting, focus on the tasks that begin with alerting: and actions:.
Alerting tasks always begin with alerting:. For example, the alerting:.index-threshold tasks back the index threshold stack rule.
Action tasks always begin with actions:. For example, the actions:.index tasks back the index action.
For more details on monitoring and diagnosing tasks in Task Manager, refer to Health monitoring.
Connectors have TLS errors when running actions
editProblem
A connector gets a TLS socket error when connecting to the server to run an action.
Solution
Configuration options are available to specialize connections to TLS servers, including ignoring server certificate validation and providing certificate authority data to verify servers using custom certificates. For more details, see Action settings.
Rules take a long time to run
editProblem
Rules are taking a long time to run and are impacting the overall health of your deployment.
By default, only users with a superuser role can query the
[preview]
This functionality is in technical preview and may be changed or removed in a future release. Elastic will work to fix any issues, but features in technical preview are not subject to the support SLA of official GA features.
Kibana event log because it is a system index. To enable additional users to run this query, assign read privileges to the .kibana-event-log* index.
Solution
By default, rules have a 5m timeout. Rules that run longer than this timeout are automatically canceled to prevent them from consuming too much of Kibana’s resources. Alerts and actions that may have been scheduled before the rule timed out are discarded. When a rule times out, you will see this error in the Kibana logs:
[2022-03-28T13:14:04.062-04:00][WARN ][plugins.taskManager] Cancelling task alerting:.index-threshold "a6ea0070-aec0-11ec-9985-dd576a3fe205" as it expired at 2022-03-28T17:14:03.980Z after running for 05m 10s (with timeout set at 5m).
and in the details page:
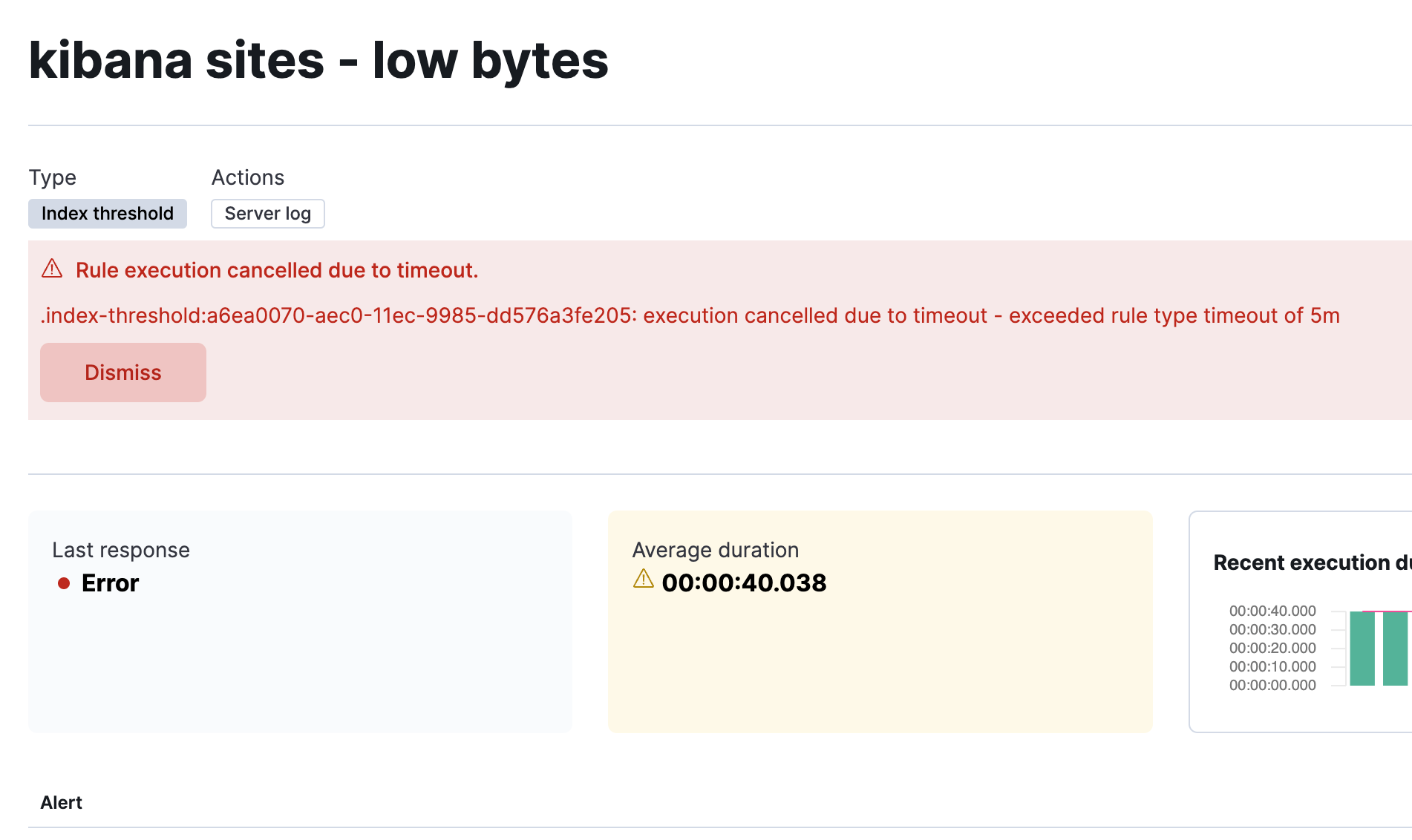
If you want your rules to run longer, update the xpack.alerting.rules.run.timeout configuration in your Alerting settings. You can also target a specific rule type by using xpack.alerting.rules.run.ruleTypeOverrides.
Rules that consistently run longer than their check interval may produce unexpected results. If the average run duration, visible on the details page, is greater than the check interval, consider increasing the check interval.
To get all long-running rules, you can query for a list of rule ids, bucketed by their run times:
GET /.kibana-event-log*/_search
{
"size": 0,
"query": {
"bool": {
"filter": [
{
"range": {
"@timestamp": {
"gte": "now-1d",
"lte": "now"
}
}
},
{
"term": {
"event.action": {
"value": "execute"
}
}
},
{
"term": {
"event.provider": {
"value": "alerting"
}
}
}
]
}
},
"runtime_mappings": {
"event.duration_in_seconds": {
"type": "double",
"script": {
"source": "emit(doc['event.duration'].value / 1E9)"
}
}
},
"aggs": {
"ruleIdsByExecutionDuration": {
"histogram": {
"field": "event.duration_in_seconds",
"min_doc_count": 1,
"interval": 1
},
"aggs": {
"ruleId": {
"nested": {
"path": "kibana.saved_objects"
},
"aggs": {
"ruleId": {
"terms": {
"field": "kibana.saved_objects.id",
"size": 10
}
}
}
}
}
}
}
}
|
This queries for rules run in the last day. Update the values of |
|
|
Use |
|
|
Run durations are stored as nanoseconds. This adds a runtime field to convert that duration into seconds. |
|
|
This interval buckets the |
|
|
This retrieves the top 10 rule ids for this duration interval. Update this value to retrieve more rule ids. |
This query returns the following:
{
"took" : 322,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 326,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"ruleIdsByExecutionDuration" : {
"buckets" : [
{
"key" : 0.0,
"doc_count" : 320,
"ruleId" : {
"doc_count" : 320,
"ruleId" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "1923ada0-a8f3-11eb-a04b-13d723cdfdc5",
"doc_count" : 140
},
{
"key" : "15415ecf-cdb0-4fef-950a-f824bd277fe4",
"doc_count" : 130
},
{
"key" : "dceeb5d0-6b41-11eb-802b-85b0c1bc8ba2",
"doc_count" : 50
}
]
}
}
},
{
"key" : 30.0,
"doc_count" : 6,
"ruleId" : {
"doc_count" : 6,
"ruleId" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "41893910-6bca-11eb-9e0d-85d233e3ee35",
"doc_count" : 6
}
]
}
}
}
]
}
}
}
|
Most run durations fall within the first bucket (0 - 1 seconds). |
|
|
A single rule with id |
Use the get rule API to retrieve additional information about rules that take a long time to run.
Rule cannot decrypt API key
editProblem:
The rule fails to run and has an Unable to decrypt attribute "apiKey" error.
Solution:
This error happens when the xpack.encryptedSavedObjects.encryptionKey value used to create the rule does not match the value used when the rule runs. Depending on the scenario, there are different ways to solve this problem:
If the value in |
Ensure any previous encryption key is included in the keys used for decryption only. |
If another Kibana instance with a different encryption key connects to the cluster. |
The other Kibana instance might be trying to run the rule using a different encryption key than what the rule was created with. Ensure the encryption keys among all the Kibana instances are the same, and setting decryption only keys for previously used encryption keys. |
If other scenarios don’t apply. |
Generate a new API key for the rule by disabling then enabling the rule. |
Rules stop running after upgrade
editProblem:
Alerting rules that were created or edited in 8.2 stop running after you upgrade to 8.3.0 or 8.3.1. The following error occurs:
<rule-type>:<UUID>: execution failed - security_exception: [security_exception] Reason: missing authentication credentials for REST request [/_security/user/_has_privileges], caused by: ""
Solution:
Upgrade to 8.3.2 or later releases to avoid the problem. To fix failing rules, go to Stack Management > Rules and Connectors and generate new API keys by selecting Update API key from the actions menu. For more details about API key authorization, refer to Authorization.