Configuring Kubernetes metadata enrichment on Elastic Agent
editConfiguring Kubernetes metadata enrichment on Elastic Agent
editKubernetes metadata refer to contextual information extracted from Kubernetes resources. Metadata information enrich metrics and logs collected from a Kubernetes cluster, enabling deeper insights into Kubernetes environments.
When the Elastic Agent’s policy includes the Kubernetes Integration which configures the collection of Kubernetes related metrics and container logs, the mechanisms used for the metadata enrichment are:
- Kubernetes Provider for log collection
- Kubernetes metadata enrichers for metrics
In case the Elastic Agent’s policy does not include the Kubernetes integration, but Elastic Agent runs inside a Kubernetes environment, the Kubernetes metadata are collected by the add_kubernetes_metadata. The processor is configurable when Elastic Agent is managed by Fleet.
Kubernetes Logs
editWhen it comes to container logs collection, the Kubernetes Provider is used. It monitors for pod resources in the cluster and associates each container log file with a corresponding pod’s container object. That way, when a log file is parsed and an event is ready to be published to Elasticsearch, the internal mechanism knows to which actual container this log file belongs. The linkage is established by the container’s ID, which forms an integral part of the filename for the log. The Kubernetes autodiscover provider has already collected all the metadata for that container, leveraging pod, namespace and node watchers. Thus, the events are enriched with the relevant metadata.
In order to configure the metadata collection, the Kubernetes provider needs to be configured. All the available configuration options of the Kubernetes provider can be found in the Kubernetes Provider documentation.
- For Standalone Elastic Agent configuration:
Follow information of add_resource_metadata parameter of Kubernetes Provider
Example of how to configure kubernetes metadata enrichment.
apiVersion: v1
kind: ConfigMap
metadata:
name: agent-node-datastreams
namespace: kube-system
labels:
k8s-app: elastic-agent
data:
agent.yml: |-
kubernetes.provider
add_resource_metadata:
namespace:
#use_regex_include: false
include_labels: ["namespacelabel1"]
#use_regex_exclude: false
#exclude_labels: ["namespacelabel2"]
node:
#use_regex_include: false
include_labels: ["nodelabel2"]
include_annotations: ["nodeannotation1"]
#use_regex_exclude: false
#exclude_labels: ["nodelabel3"]
#deployment: false
#cronjob: false
- Managed Elastic Agent configuration:
The Kubernetes provider can be configured following the steps in Advanced Elastic Agent configuration managed by Fleet.
Kubernetes metrics
editThe Elastic Agent metrics collection implements metadata enrichment based on watchers, a mechanism used to continuously monitor Kubernetes resources for changes and updates. Specifically, the different datasets share a set of resource watchers. Those watchers (pod, node, namespace, deployment, daemonset etc.) are responsible for watching for all different resource events (creation, update and deletion) by subscribing to the Kubernetes watch API. This enables real-time synchronization of application state with the state of the Kubernetes cluster. So, they keep an up-to-date shared cache store of all the resources' information and metadata. Whenever metrics are collected by the different sources (kubelet, kube-state-metrics), before they get published to Elasticsearch as events, they are enriched with needed metadata.
The metadata enrichment can be configured by editing the Kubernetes integration.
Only in metrics collection, metadata enrichment can be disabled by switching off the Add Metadata toggle in every dataset. Extra resource metadata such as
node, namespace labels and annotations, as well as deployment and cronjob information can be configured per dataset.
- Managed Elastic Agent configuration:
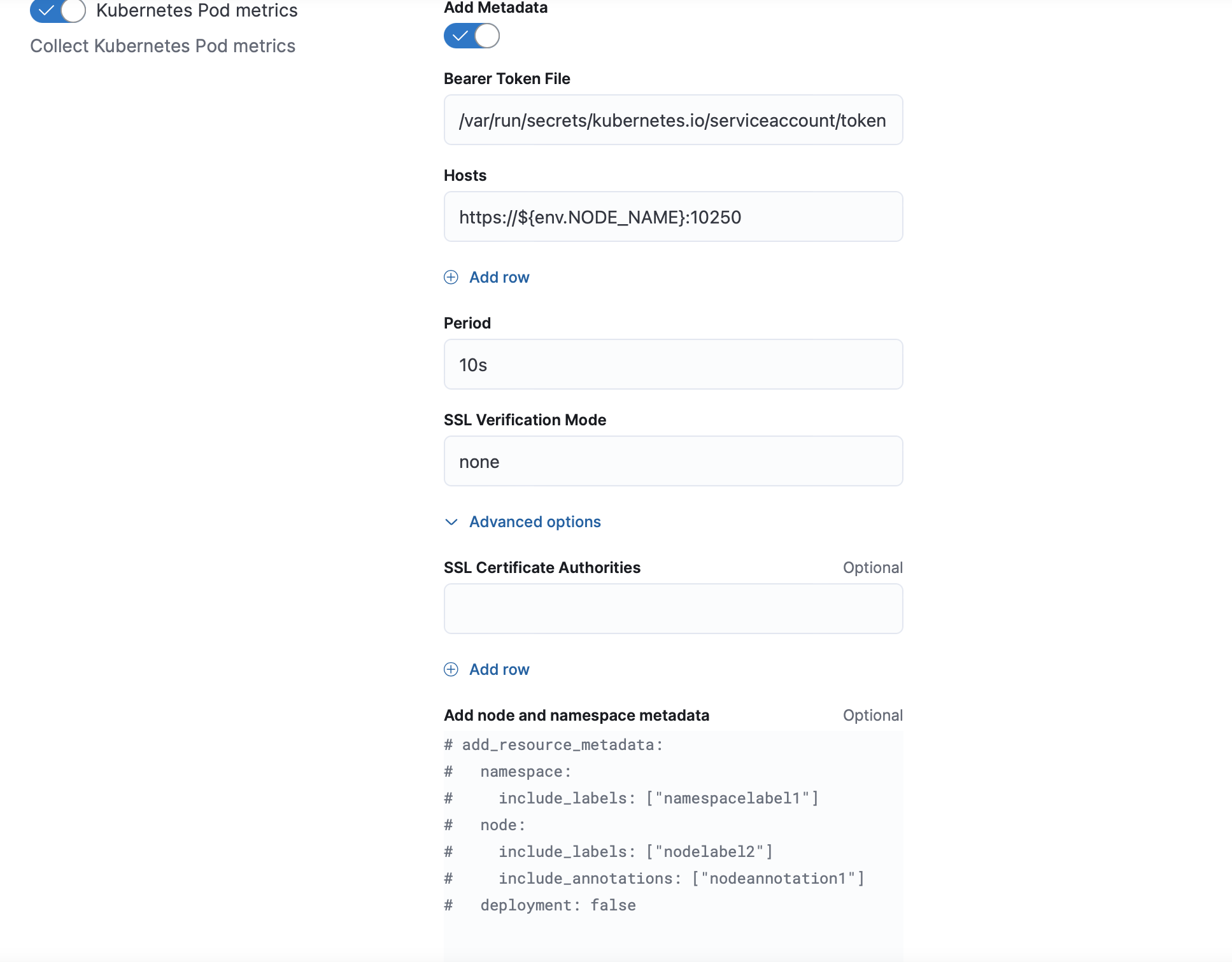
add_resource_metadata block needs to be configured to all datasets that are enabled
- For Standalone Elastic Agent configuration:
Elastic Agent Standalone manifest sample.
[output trunctated ...]
- data_stream:
dataset: kubernetes.state_pod
type: metrics
metricsets:
- state_pod
add_metadata: true
hosts:
- 'kube-state-metrics:8080'
period: 10s
add_resource_metadata:
namespace:
enabled: true
#use_regex_include: false
include_labels: ["namespacelabel1"]
#use_regex_exclude: false
#exclude_labels: ["namespacelabel2"]
node:
enabled: true
#use_regex_include: false
include_labels: ["nodelabel2"]
include_annotations: ["nodeannotation1"]
#use_regex_exclude: false
#exclude_labels: ["nodelabel3"]
#deployment: false
#cronjob: false
The add_resource_metadata block configures the watcher’s enrichment functionality. See Kubernetes Provider for full description of add_resource_metadata. Same configuration parameters apply.
Note
editAlthough the add_kubernetes_metadata processor is by default enabled when using elastic-agent, it is skipped whenever Kubernetes integration is detected.