Document enrichment with ML
editDocument enrichment with ML
editStarting in 8.5, Enterprise Search creates ingestion pipelines by default to work with indices created for search use cases. The ML inference pipeline uses inference processors to analyze fields and enrich documents with the output. Inference processors use ML trained models, so you need to use a built-in model or deploy a trained model in your cluster to use this feature.
This guide focuses on the ML inference pipeline, its use, and how to manage it.
This feature is not available at all Elastic subscription levels. Refer to the Elastic subscriptions pages for Elastic Cloud and self-managed deployments.
NLP use cases
editNatural Language Processing (NLP) allows developers to create rich search experiences that go beyond the standards of lexical search. A few examples of ways to improve search experiences through the use of NLP models:
ELSER text expansion
editUsing Elastic’s ELSER machine learning model you can easily incorporate text expansion for your queries. This works by using ELSER to provide semantic enrichments to your documents upon ingestion, combined with the power of Elastic Search Application templates to provide automated text expansion at query time.
Named entity recognition (NER)
editMost commonly used to detect entities such as People, Places, and Organization information from text, NER can be used to extract key information from text and group results based on that information. A sports news media site could use NER to automatically extract names of professional athletes, stadiums, and sports teams in their articles and link to season stats or schedules.
Text classification
editText classification is commonly used for sentiment analysis and can be used for similar tasks, such as labeling content as containing hate speech in public forums, or triaging and labeling support tickets so they reach the correct level of escalation automatically.
Text embedding
editAnalyzing a text field using a Text embedding model will generate a dense_vector representation of the text. This array of numeric values encodes the semantic meaning of the text. Using the same model with a user’s search query will produce a vector that can then be used to search, ranking results based on vector similarity - semantic similarity - as opposed to traditional word or text similarity.
A common use case is a user searching FAQs, or a support agent searching a knowledge base, where semantically similar content may be indexed with little similarity in phrasing.
NLP in Enterprise Search
editOverview of ML inference pipeline in Enterprise Search
editThe diagram below shows how documents are processed during ingestion.
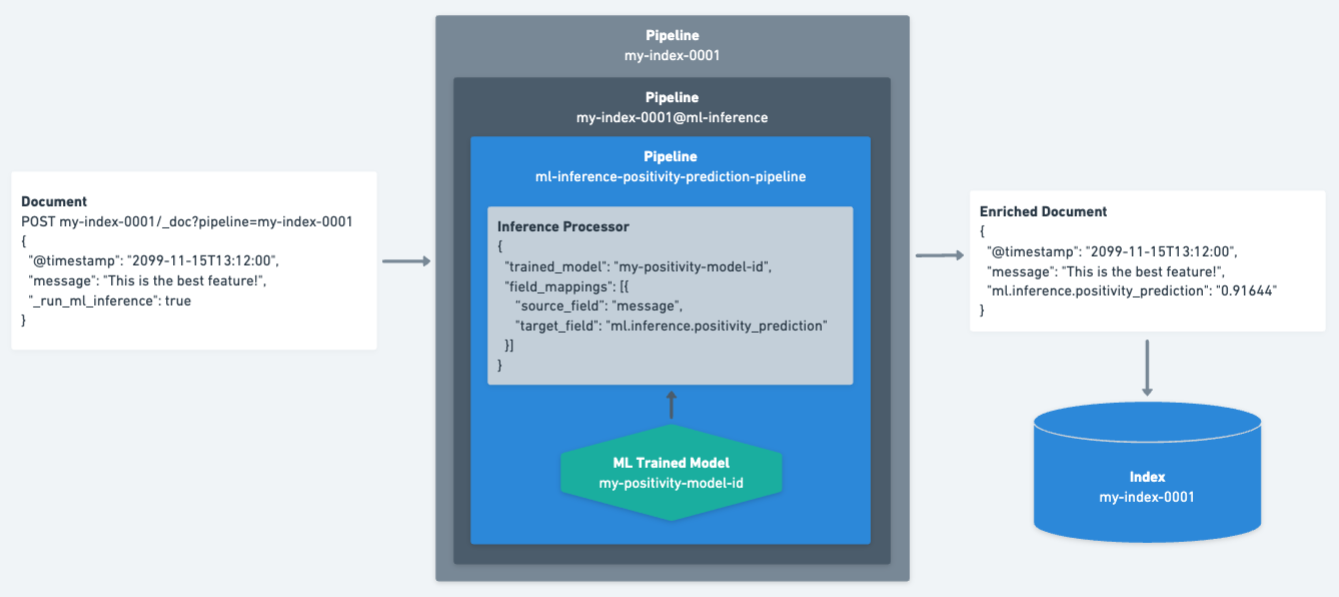
-
Documents are processed by the
my-index-0001pipeline, which happens automatically when indexing through a Search connector or crawler. -
The
_run_ml_inferencefield is set totrueto ensure the ML inference pipeline (my-index-0001@ml-inference) is executed. This field is removed during the ingestion process. -
The inference processor analyzes the
messagefield on the document using themy-positivity-model-idtrained model. The inference output is stored in theml.inference.positivity_predictionfield. -
The resulting enriched document is then indexed into the
my-index-0001index. -
The
ml.inference.positivity_predictionfield can now be used at query time to search for documents above or below a certain threshold.
Find, deploy, and manage trained models
editThis feature is intended to make it easier to use your ML trained models. First, you need to figure out which model works best for your data. Make sure to use a compatible third party NLP model. Since these are publicly available, it is not possible to fine-tune models before deploying them.
Trained models must be available in the current Kibana Space and running in order to use them. By default, models should be available in all Kibana Spaces that have the Analytics > Machine Learning feature enabled. To manage your trained models, use the Kibana UI and navigate to Stack Management → Machine Learning → Trained Models. Spaces can be controlled in the spaces column. To stop or start a model, go to the Machine Learning tab in the Analytics menu of Kibana and click Trained Models in the Model Management section.
The monitor_ml Elasticsearch cluster privilege is required to manage ML models and ML inference pipelines which use those models.
Add inference processors to your ML inference pipeline
editTo create the index-specific ML inference pipeline, go to Enterprise Search → Content → Indices → <your index> → Pipelines in the Kibana UI.
If you only see the ent-search-generic-ingestion pipeline, you will need to click Copy and customize to create index-specific pipelines.
This will create the {index_name}@ml-inference pipeline.
Once your index-specific ML inference pipeline is ready, you can add inference processors that use your ML trained models. To add an inference processor to the ML inference pipeline, click the Add Inference Pipeline button in the Machine Learning Inference Pipelines card.

Here, you’ll be able to:
-
Choose a name for your pipeline.
- This name will need to be unique across the whole deployment. If you want this pipeline to be index-specific, we recommend including the name of your index in the pipeline name.
- Select the ML trained model you want to use.
-
Select one or more source fields as input for the inference processor.
- If there are no source fields available, your index will need a field mapping.
- (Optional) Choose a name for your target field. This is where the output of the inference model will be stored. Changing the default name is only possible if you have a single source field selected.
- Add the source-target field mapping to the configuration by clicking the Add button.
- Repeat steps 3-5 for each field mapping you want to add.
- (Optional) Test the pipeline with a sample document.
- (Optional) Review the pipeline definition before creating it with the Create pipeline button.
Manage and delete inference processors from your ML inference pipeline
editInference processors added to your index-specific ML inference pipelines are normal Elasticsearch pipelines. Once created, each processor will have options to View in Stack Management and Delete Pipeline. Deleting an inference processor from within the Enterprise Search view deletes the pipeline and also removes its reference from your index-specific ML inference pipeline.
These pipelines can also be viewed, edited, and deleted in Kibana via Stack Management → Ingest Pipelines, just like all other Elasticsearch ingest pipelines. You may also use the Ingest pipeline APIs. If you delete any of these pipelines outside of the Enterprise Search product in Kibana, please make sure to edit the ML inference pipelines that reference them.
Update mappings to use ML inference pipelines
editAfter setting up an ML inference pipeline or attaching an existing one, it may be necessary to manually create the field mappings in order to support the referenced trained ML model’s output. This needs to happen before the pipeline is first used to index some documents, otherwise the model output fields could be inferred with the wrong type.
This doesn’t apply when you’re creating a pipeline with the ELSER model, for which the index mappings are automatically updated in the process.
The required field name and type depends on the configuration of the pipeline and the trained model it uses.
For example, if you configure a text_embedding model, select summary as a source field, and ml.inference.summary as the target field, the inference output will be stored in ml.inference.<source field name>.predicted_value as a dense_vector.
In order to support semantic search on this field, it must be added to the mapping:
PUT my-index-0001/_mapping
{
"properties": {
"ml.inference.summary.predicted_value": {
"type": "dense_vector",
"dims": 768,
"index": true,
"similarity": "dot_product"
}
}
}
|
The output of the ML model is stored in the configured target field suffixed with |
|
|
Choose a field type that is compatible with the inference output and supports your search use cases. |
|
|
Set additional properties as necessary. |
You can check the shape of the generated output before indexing any documents while creating the ML inference pipeline under the Test tab.
Simply provide a sample document, click Simulate, and look for the ml.inference object in the results.
Test your ML inference pipeline
editTo ensure the ML inference pipeline will be run when ingesting documents, you must make sure the documents you are ingesting have a field named _run_ml_inference that is set to true and you must set the pipeline to {index_name}.
For connector and crawler indices, this will happen automatically if you’ve configured the settings appropriately for the pipeline name {index_name}.
To manage these settings:
- Go to Enterprise Search → Content → Indices → <your index> → Pipelines.
-
Click on the Settings link in the Ingest Pipelines card for the
{index_name}pipeline. - Ensure ML inference pipelines is selected. If it is not, select it and save the changes.
Learn More:
edit- See Ingest pipelines in Enterprise Search for information on the various pipelines that are created.
- ELSER Text Expansion Model
- NER HuggingFace Models
- Text Classification HuggingFace Models
- Text Embedding HuggingFace Models