Tutorial: Set up cross-cluster replication
editTutorial: Set up cross-cluster replication
editUse this guide to set up cross-cluster replication (CCR) between clusters in two datacenters. Replicating your data across datacenters provides several benefits:
- Brings data closer to your users or application server to reduce latency and response time
- Provides your mission-critical applications with the tolerance to withstand datacenter or region outages
In this guide, you’ll learn how to:
- Configure a remote cluster with a leader index
- Create a follower index on a local cluster
- Create an auto-follow pattern to automatically follow time series indices that are periodically created in a remote cluster
You can manually create follower indices to replicate specific indices on a remote cluster, or configure auto-follow patterns to replicate rolling time series indices.
If you want to replicate data across clusters in the cloud, you can configure remote clusters on Elasticsearch Service. Then, you can search across clusters and set up cross-cluster replication.
Prerequisites
editTo complete this tutorial, you need:
-
The
managecluster privilege on the local cluster. - A license on both clusters that includes cross-cluster replication. Activate a free 30-day trial.
- An index on the remote cluster that contains the data you want to replicate. This tutorial uses the sample eCommerce orders data set. Load sample data.
-
In the local cluster, all nodes with the
masternode role must also have theremote_cluster_clientrole. The local cluster must also have at least one node with both a data role and theremote_cluster_clientrole. Individual tasks for coordinating replication scale based on the number of data nodes with theremote_cluster_clientrole in the local cluster.
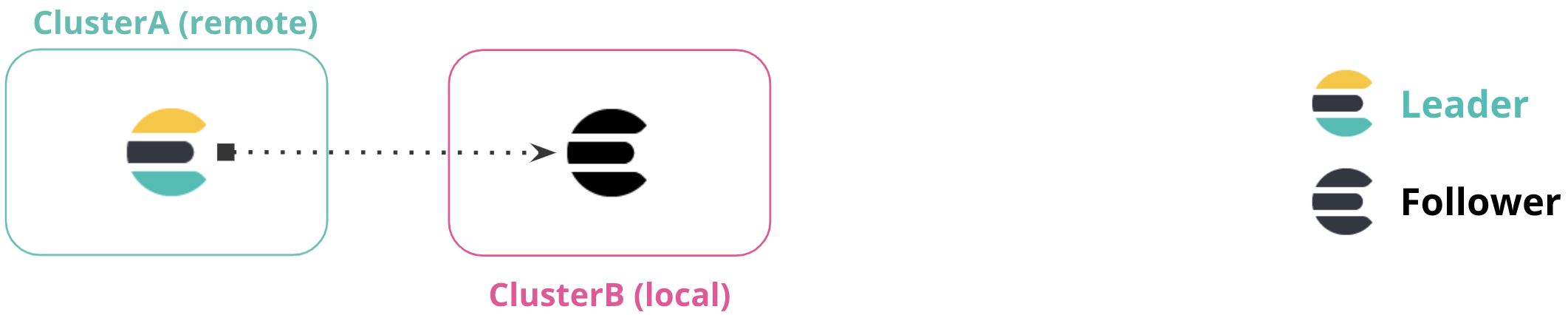
Connect to a remote cluster
editTo replicate an index on a remote cluster (Cluster A) to a local cluster (Cluster B), you configure Cluster A as a remote on Cluster B.
To configure a remote cluster from Stack Management in Kibana:
- Set up a secure connection as needed.
- Select Remote Clusters from the side navigation.
-
Specify the Elasticsearch endpoint URL, or the IP address or host name of the remote
cluster (
ClusterA) followed by the transport port (defaults to9300). For example,cluster.es.eastus2.staging.azure.foundit.no:9400or192.168.1.1:9300.
API example
You can also use the cluster update settings API to add a remote cluster:
resp = client.cluster.put_settings(
persistent={
"cluster": {
"remote": {
"leader": {
"seeds": [
"127.0.0.1:9300"
]
}
}
}
},
)
print(resp)
response = client.cluster.put_settings(
body: {
persistent: {
cluster: {
remote: {
leader: {
seeds: [
'127.0.0.1:9300'
]
}
}
}
}
}
)
puts response
const response = await client.cluster.putSettings({
persistent: {
cluster: {
remote: {
leader: {
seeds: ["127.0.0.1:9300"],
},
},
},
},
});
console.log(response);
PUT /_cluster/settings
{
"persistent" : {
"cluster" : {
"remote" : {
"leader" : {
"seeds" : [
"127.0.0.1:9300"
]
}
}
}
}
}
You can verify that the local cluster is successfully connected to the remote cluster.
resp = client.cluster.remote_info() print(resp)
response = client.cluster.remote_info puts response
const response = await client.cluster.remoteInfo(); console.log(response);
GET /_remote/info
The API response indicates that the local cluster is connected to the remote
cluster with cluster alias leader.
Configure privileges for cross-cluster replication
editThe cross-cluster replication user requires different cluster and index privileges on the remote cluster and local cluster. Use the following requests to create separate roles on the local and remote clusters, and then create a user with the required roles.
Remote cluster
editOn the remote cluster that contains the leader index, the cross-cluster replication role requires
the read_ccr cluster privilege, and monitor and read privileges on the
leader index.
If requests are authenticated with an API key, the API key requires the above privileges on the local cluster, instead of the remote.
If requests are issued on behalf of other users,
then the authenticating user must have the run_as privilege on the remote
cluster.
The following request creates a remote-replication role on the remote cluster:
resp = client.security.put_role(
name="remote-replication",
cluster=[
"read_ccr"
],
indices=[
{
"names": [
"leader-index-name"
],
"privileges": [
"monitor",
"read"
]
}
],
)
print(resp)
const response = await client.security.putRole({
name: "remote-replication",
cluster: ["read_ccr"],
indices: [
{
names: ["leader-index-name"],
privileges: ["monitor", "read"],
},
],
});
console.log(response);
POST /_security/role/remote-replication
{
"cluster": [
"read_ccr"
],
"indices": [
{
"names": [
"leader-index-name"
],
"privileges": [
"monitor",
"read"
]
}
]
}
Local cluster
editOn the local cluster that contains the follower index, the remote-replication
role requires the manage_ccr cluster privilege, and monitor, read, write,
and manage_follow_index privileges on the follower index.
The following request creates a remote-replication role on the local cluster:
resp = client.security.put_role(
name="remote-replication",
cluster=[
"manage_ccr"
],
indices=[
{
"names": [
"follower-index-name"
],
"privileges": [
"monitor",
"read",
"write",
"manage_follow_index"
]
}
],
)
print(resp)
const response = await client.security.putRole({
name: "remote-replication",
cluster: ["manage_ccr"],
indices: [
{
names: ["follower-index-name"],
privileges: ["monitor", "read", "write", "manage_follow_index"],
},
],
});
console.log(response);
POST /_security/role/remote-replication
{
"cluster": [
"manage_ccr"
],
"indices": [
{
"names": [
"follower-index-name"
],
"privileges": [
"monitor",
"read",
"write",
"manage_follow_index"
]
}
]
}
After creating the remote-replication role on each cluster, use the
create or update users API to create a user on
the local cluster cluster and assign the remote-replication role. For
example, the following request assigns the remote-replication role to a user
named cross-cluster-user:
resp = client.security.put_user(
username="cross-cluster-user",
password="l0ng-r4nd0m-p@ssw0rd",
roles=[
"remote-replication"
],
)
print(resp)
const response = await client.security.putUser({
username: "cross-cluster-user",
password: "l0ng-r4nd0m-p@ssw0rd",
roles: ["remote-replication"],
});
console.log(response);
POST /_security/user/cross-cluster-user
{
"password" : "l0ng-r4nd0m-p@ssw0rd",
"roles" : [ "remote-replication" ]
}
You only need to create this user on the local cluster.
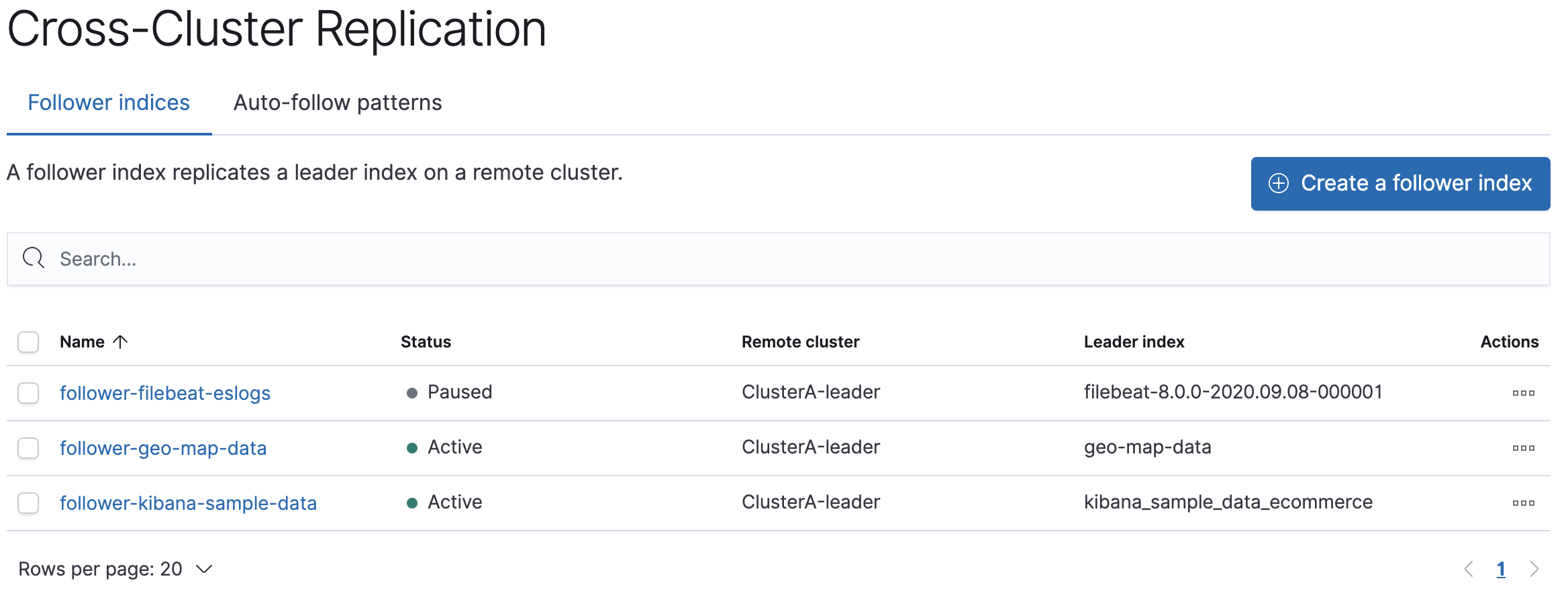
Create a follower index to replicate a specific index
editWhen you create a follower index, you reference the remote cluster and the leader index in your remote cluster.
To create a follower index from Stack Management in Kibana:
- Select Cross-Cluster Replication in the side navigation and choose the Follower Indices tab.
- Choose the cluster (ClusterA) containing the leader index you want to replicate.
-
Enter the name of the leader index, which is
kibana_sample_data_ecommerceif you are following the tutorial. -
Enter a name for your follower index, such as
follower-kibana-sample-data.
Elasticsearch initializes the follower using the remote recovery process, which transfers the existing Lucene segment files from the leader index to the follower index. The index status changes to Paused. When the remote recovery process is complete, the index following begins and the status changes to Active.
When you index documents into your leader index, Elasticsearch replicates the documents in the follower index.
API example
You can also use the create follower API to create follower indices. When you create a follower index, you must reference the remote cluster and the leader index that you created in the remote cluster.
When initiating the follower request, the response returns before the
remote recovery process completes. To wait for the process
to complete, add the wait_for_active_shards parameter to your request.
resp = client.ccr.follow(
index="server-metrics-follower",
wait_for_active_shards="1",
remote_cluster="leader",
leader_index="server-metrics",
)
print(resp)
const response = await client.ccr.follow({
index: "server-metrics-follower",
wait_for_active_shards: 1,
remote_cluster: "leader",
leader_index: "server-metrics",
});
console.log(response);
PUT /server-metrics-follower/_ccr/follow?wait_for_active_shards=1
{
"remote_cluster" : "leader",
"leader_index" : "server-metrics"
}
Use the get follower stats API to inspect the status of replication.
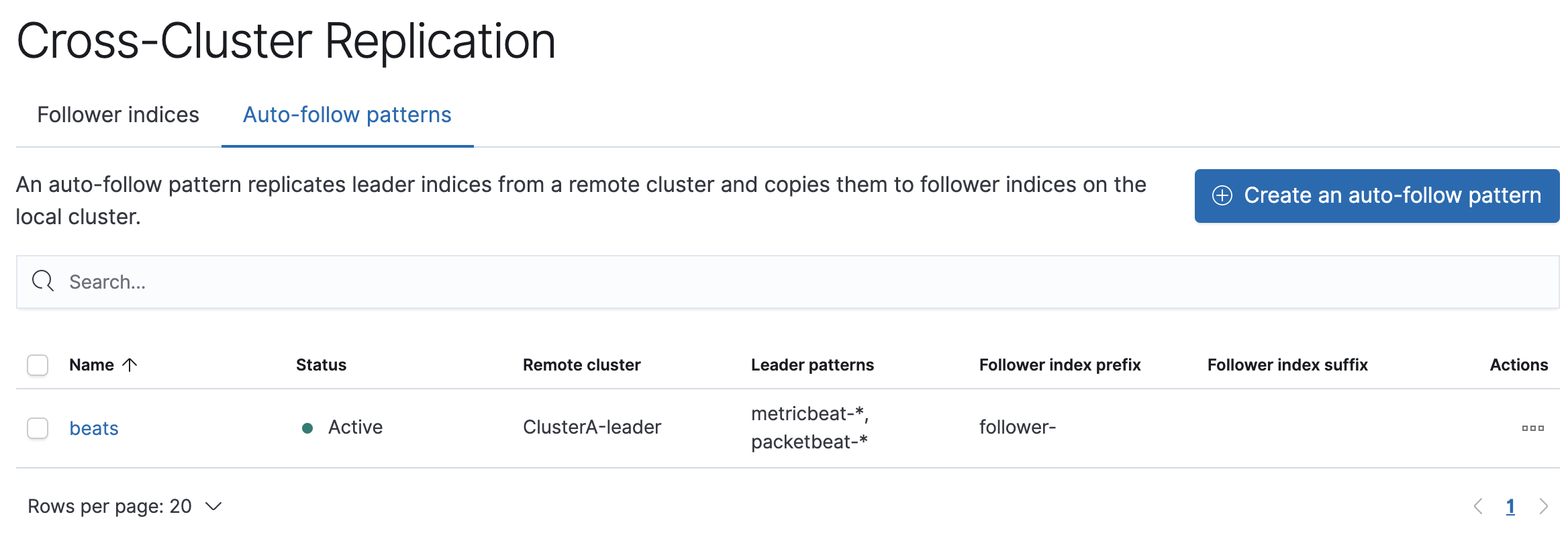
Create an auto-follow pattern to replicate time series indices
editYou use auto-follow patterns to automatically create new followers for rolling time series indices. Whenever the name of a new index on the remote cluster matches the auto-follow pattern, a corresponding follower index is added to the local cluster. Note that only indices created on the remote cluster after the auto-follow pattern is created will be auto-followed: existing indices on the remote cluster are ignored even if they match the pattern.
An auto-follow pattern specifies the remote cluster you want to replicate from, and one or more index patterns that specify the rolling time series indices you want to replicate.
To create an auto-follow pattern from Stack Management in Kibana:
- Select Cross Cluster Replication in the side navigation and choose the Auto-follow patterns tab.
-
Enter a name for the auto-follow pattern, such as
beats. - Choose the remote cluster that contains the index you want to replicate, which in the example scenario is Cluster A.
-
Enter one or more index patterns that identify the indices you want to
replicate from the remote cluster. For example, enter
metricbeat-* packetbeat-*to automatically create followers for Metricbeat and Packetbeat indices. - Enter follower- as the prefix to apply to the names of the follower indices so you can more easily identify replicated indices.
As new indices matching these patterns are created on the remote, Elasticsearch automatically replicates them to local follower indices.
API example
Use the create auto-follow pattern API to configure auto-follow patterns.
resp = client.ccr.put_auto_follow_pattern(
name="beats",
remote_cluster="leader",
leader_index_patterns=[
"metricbeat-*",
"packetbeat-*"
],
follow_index_pattern="{{leader_index}}-copy",
)
print(resp)
const response = await client.ccr.putAutoFollowPattern({
name: "beats",
remote_cluster: "leader",
leader_index_patterns: ["metricbeat-*", "packetbeat-*"],
follow_index_pattern: "{{leader_index}}-copy",
});
console.log(response);