Tutorial: Disaster recovery based on bi-directional cross-cluster replication
editTutorial: Disaster recovery based on bi-directional cross-cluster replication
editLearn how to set up disaster recovery between two clusters based on bi-directional cross-cluster replication. The following tutorial is designed for data streams which support update by query and delete by query. You can only perform these actions on the leader index.
This tutorial works with Logstash as the source of ingestion. It takes advantage of a Logstash feature where the Logstash output to Elasticsearch can be load balanced across an array of hosts specified. Beats and Elastic Agents currently do not support multiple outputs. It should also be possible to set up a proxy (load balancer) to redirect traffic without Logstash in this tutorial.
-
Setting up a remote cluster on
clusterAandclusterB. - Setting up bi-directional cross-cluster replication with exclusion patterns.
- Setting up Logstash with multiple hosts to allow automatic load balancing and switching during disasters.
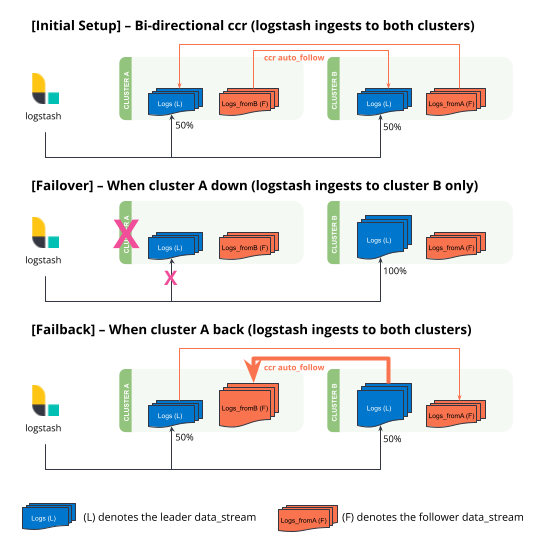
Initial setup
edit-
Set up a remote cluster on both clusters.
response = client.cluster.put_settings( body: { persistent: { cluster: { remote: { "clusterB": { mode: 'proxy', skip_unavailable: true, server_name: 'clusterb.es.region-b.gcp.elastic-cloud.com', proxy_socket_connections: 18, proxy_address: 'clusterb.es.region-b.gcp.elastic-cloud.com:9400' } } } } } ) puts response response = client.cluster.put_settings( body: { persistent: { cluster: { remote: { "clusterA": { mode: 'proxy', skip_unavailable: true, server_name: 'clustera.es.region-a.gcp.elastic-cloud.com', proxy_socket_connections: 18, proxy_address: 'clustera.es.region-a.gcp.elastic-cloud.com:9400' } } } } } ) puts response### On cluster A ### PUT _cluster/settings { "persistent": { "cluster": { "remote": { "clusterB": { "mode": "proxy", "skip_unavailable": true, "server_name": "clusterb.es.region-b.gcp.elastic-cloud.com", "proxy_socket_connections": 18, "proxy_address": "clusterb.es.region-b.gcp.elastic-cloud.com:9400" } } } } } ### On cluster B ### PUT _cluster/settings { "persistent": { "cluster": { "remote": { "clusterA": { "mode": "proxy", "skip_unavailable": true, "server_name": "clustera.es.region-a.gcp.elastic-cloud.com", "proxy_socket_connections": 18, "proxy_address": "clustera.es.region-a.gcp.elastic-cloud.com:9400" } } } } } -
Set up bi-directional cross-cluster replication.
### On cluster A ### PUT /_ccr/auto_follow/logs-generic-default { "remote_cluster": "clusterB", "leader_index_patterns": [ ".ds-logs-generic-default-20*" ], "leader_index_exclusion_patterns":"*-replicated_from_clustera", "follow_index_pattern": "{{leader_index}}-replicated_from_clusterb" } ### On cluster B ### PUT /_ccr/auto_follow/logs-generic-default { "remote_cluster": "clusterA", "leader_index_patterns": [ ".ds-logs-generic-default-20*" ], "leader_index_exclusion_patterns":"*-replicated_from_clusterb", "follow_index_pattern": "{{leader_index}}-replicated_from_clustera" }Existing data on the cluster will not be replicated by
_ccr/auto_followeven though the patterns may match. This function will only replicate newly created backing indices (as part of the data stream).Use
leader_index_exclusion_patternsto avoid recursion.follow_index_patternallows lowercase characters only.This step cannot be executed via the Kibana UI due to the lack of an exclusion pattern in the UI. Use the API in this step.
-
Set up the Logstash configuration file.
This example uses the input generator to demonstrate the document count in the clusters. Reconfigure this section to suit your own use case.
### On Logstash server ### ### This is a logstash config file ### input { generator{ message => 'Hello World' count => 100 } } output { elasticsearch { hosts => ["https://clustera.es.region-a.gcp.elastic-cloud.com:9243","https://clusterb.es.region-b.gcp.elastic-cloud.com:9243"] user => "logstash-user" password => "same_password_for_both_clusters" } }The key point is that when
cluster Ais down, all traffic will be automatically redirected tocluster B. Oncecluster Acomes back, traffic is automatically redirected back tocluster Aagain. This is achieved by the optionhostswhere multiple ES cluster endpoints are specified in the array[clusterA, clusterB].Set up the same password for the same user on both clusters to use this load-balancing feature.
-
Start Logstash with the earlier configuration file.
### On Logstash server ### bin/logstash -f multiple_hosts.conf
-
Observe document counts in data streams.
The setup creates a data stream named
logs-generic-defaulton each of the clusters. Logstash will write 50% of the documents tocluster Aand 50% of the documents tocluster Bwhen both clusters are up.Bi-directional cross-cluster replication will create one more data stream on each of the clusters with the
-replication_from_cluster{a|b}suffix. At the end of this step:-
data streams on cluster A contain:
-
50 documents in
logs-generic-default-replicated_from_clusterb -
50 documents in
logs-generic-default
-
50 documents in
-
data streams on cluster B contain:
-
50 documents in
logs-generic-default-replicated_from_clustera -
50 documents in
logs-generic-default
-
50 documents in
-
-
Queries should be set up to search across both data streams. A query on
logs*, on either of the clusters, returns 100 hits in total.response = client.search( index: 'logs*', size: 0 ) puts response
GET logs*/_search?size=0
Failover when clusterA is down
edit-
You can simulate this by shutting down either of the clusters. Let’s shut down
cluster Ain this tutorial. -
Start Logstash with the same configuration file. (This step is not required in real use cases where Logstash ingests continuously.)
### On Logstash server ### bin/logstash -f multiple_hosts.conf
-
Observe all Logstash traffic will be redirected to
cluster Bautomatically.You should also redirect all search traffic to the
clusterBcluster during this time. -
The two data streams on
cluster Bnow contain a different number of documents.-
data streams on cluster A (down)
-
50 documents in
logs-generic-default-replicated_from_clusterb -
50 documents in
logs-generic-default
-
50 documents in
-
data streams On cluster B (up)
-
50 documents in
logs-generic-default-replicated_from_clustera -
150 documents in
logs-generic-default
-
50 documents in
-
Failback when clusterA comes back
edit-
You can simulate this by turning
cluster Aback on. -
Data ingested to
cluster Bduringcluster A's downtime will be automatically replicated.-
data streams on cluster A
-
150 documents in
logs-generic-default-replicated_from_clusterb -
50 documents in
logs-generic-default
-
150 documents in
-
data streams on cluster B
-
50 documents in
logs-generic-default-replicated_from_clustera -
150 documents in
logs-generic-default
-
50 documents in
-
- If you have Logstash running at this time, you will also observe traffic is sent to both clusters.
Perform update or delete by query
editIt is possible to update or delete the documents but you can only perform these actions on the leader index.
-
First identify which backing index contains the document you want to update.
response = client.search( index: 'logs-generic-default*', filter_path: 'hits.hits._index', body: { query: { match: { "event.sequence": '97' } } } ) puts response### On either of the cluster ### GET logs-generic-default*/_search?filter_path=hits.hits._index { "query": { "match": { "event.sequence": "97" } } }-
If the hits returns
"_index": ".ds-logs-generic-default-replicated_from_clustera-<yyyy.MM.dd>-*", then you need to proceed to the next step oncluster A. -
If the hits returns
"_index": ".ds-logs-generic-default-replicated_from_clusterb-<yyyy.MM.dd>-*", then you need to proceed to the next step oncluster B. -
If the hits returns
"_index": ".ds-logs-generic-default-<yyyy.MM.dd>-*", then you need to proceed to the next step on the same cluster where you performed the search query.
-
If the hits returns
-
Perform the update (or delete) by query:
response = client.update_by_query( index: 'logs-generic-default', body: { query: { match: { "event.sequence": '97' } }, script: { source: 'ctx._source.event.original = params.new_event', lang: 'painless', params: { new_event: 'FOOBAR' } } } ) puts response### On the cluster identified from the previous step ### POST logs-generic-default/_update_by_query { "query": { "match": { "event.sequence": "97" } }, "script": { "source": "ctx._source.event.original = params.new_event", "lang": "painless", "params": { "new_event": "FOOBAR" } } }If a soft delete is merged away before it can be replicated to a follower the following process will fail due to incomplete history on the leader, see index.soft_deletes.retention_lease.period for more details.