It is time to say goodbye: This version of Elastic Cloud Enterprise has reached end-of-life (EOL) and is no longer supported.
The documentation for this version is no longer being maintained. If you are running this version, we strongly advise you to upgrade. For the latest information, see the current release documentation.
Disable a data tier
editDisable a data tier
editElastic Cloud Enterprise tries to move all data from the nodes that are removed during plan changes. To disable a data tier, make sure that all data on that tier can be re-allocated by reconfiguring the relevant shard allocation filters. You’ll also need to temporarily stop your index lifecycle management (ILM) policies to prevent new indices from being moved to the data tier you want to disable.
To learn more about ILM for Elastic Cloud Enterprise, or shard allocation filtering, check the following documentation:
To make sure that all data can be migrated from the data tier you want to disable, follow these steps:
-
Determine which nodes will be removed from the cluster.
- Log into the Cloud UI.
-
From the Deployments page, select your deployment.
Narrow the list by name, ID, or choose from several other filters. To further define the list, use a combination of filters.
-
Filter the list of instances by the Data tier you want to disable.
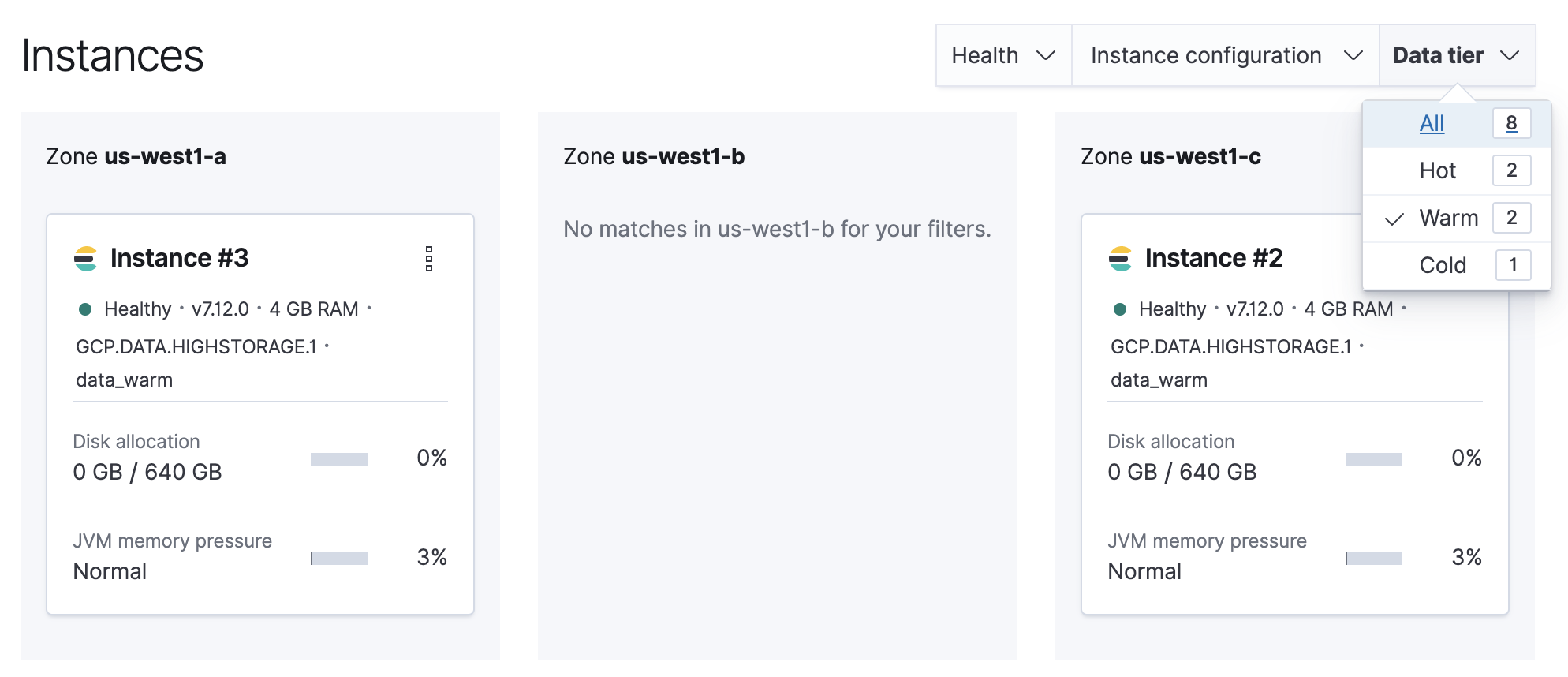
Note the listed instance IDs. In this example, it would be Instance 2 and Instance 3.
-
Stop ILM.
POST /_ilm/stop
-
Determine which shards need to be moved.
GET /_cat/shards
Parse the output, looking for shards allocated to the nodes to be removed from the cluster. Note that
Instance #2is shown asinstance-0000000002in the output.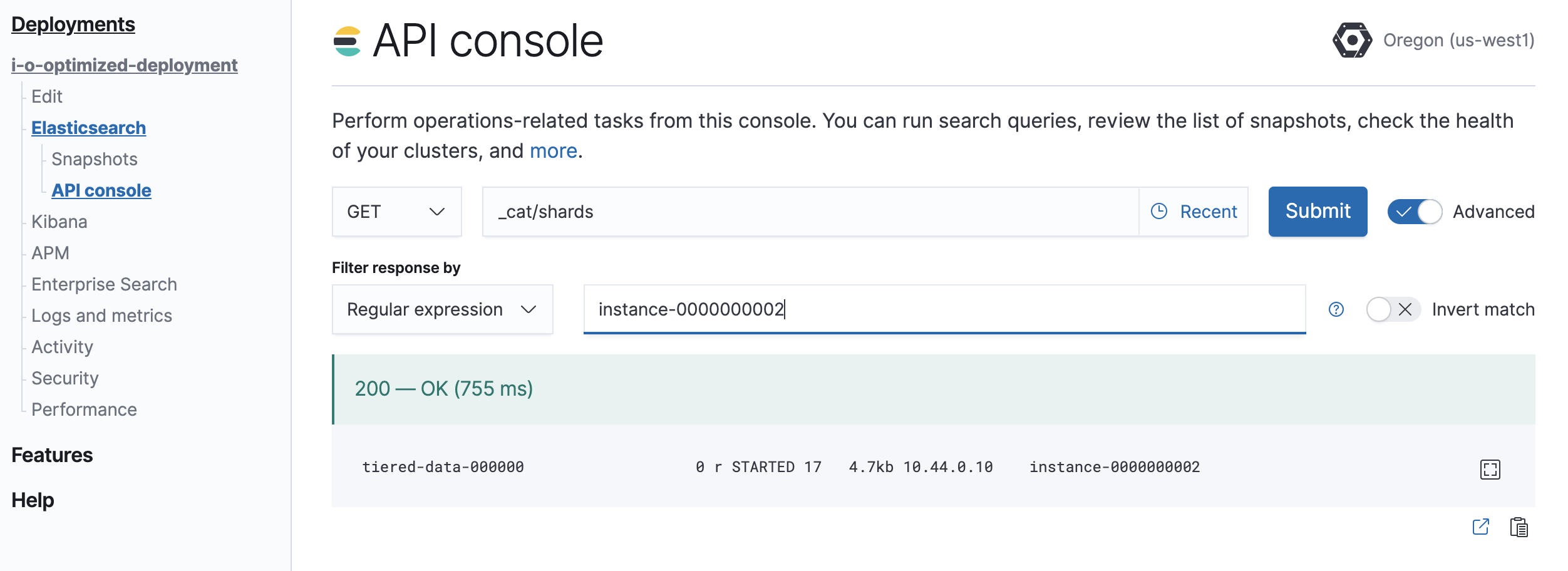
-
Move shards off the nodes to be removed from the cluster.
You must remove any index-level shard allocation filters from the indices on the nodes to be removed. ILM uses different rules depending on the policy and version of Elasticsearch. Check the index settings to determine which rule to use:
GET /my-index/_settings
-
Updating data tier based allocation inclusion rules.
Data tier based ILM policies uses
index.routing.allocation.includeto allocate shards to the appropriate tier. The indices that use this method have index routing settings similar to the following example:{ ... "routing": { "allocation": { "include": { "_tier_preference": "data_warm,data_hot" } } } ... }You must remove the relevant tier from the inclusion rules. For example, to disable the warm tier, the
data_warmtier preference should be removed:PUT /my-index/_settings { "routing": { "allocation": { "include": { "_tier_preference": "data_hot" } } } }Updating allocation inclusion rules will trigger a shard re-allocation, moving the shards from the nodes to be removed.
-
Updating node attribute allocation requirement rules.
Node attribute based ILM policies uses
index.routing.allocation.requireto allocate shards to the appropriate nodes. The indices that use this method have index routing settings that are similar to the following example:{ ... "routing": { "allocation": { "require": { "data": "warm" } } } ... }You must either remove or redefine the routing requirements. To remove the attribute requirements, use the following code:
PUT /my-index/_settings { "routing": { "allocation": { "require": { "data": null } } } }Removing required attributes does not trigger a shard reallocation. These shards are moved when applying the plan to disable the data tier. Alternatively, you can use the cluster re-route API to manually re-allocate the shards before removing the nodes, or explicitly re-allocate shards to hot nodes by using the following code:
PUT /my-index/_settings { "routing": { "allocation": { "require": { "data": "hot" } } } } -
Removing custom allocation rules.
If indices on nodes to be removed have shard allocation rules of other forms, they must be removed as shown in the following example:
PUT /my-index/_settings { "routing": { "allocation": { "require": null, "include": null, "exclude": null } } }
-
-
Edit the deployment, disabling the data tier.
If autoscaling is enabled, set the maximum size to 0 for the data tier to ensure autoscaling does not re-enable the data tier.
Any remaining shards on the tier being disabled are re-allocated across the remaining cluster nodes while applying the plan to disable the data tier. Monitor shard allocation during the data migration phase to ensure all allocation rules have been correctly updated. If the plan fails to migrate data away from the data tier, then re-examine the allocation rules for the indices remaining on that data tier.