Implementieren einer Heiß-Warm-Kalt-Architektur mit Index-Lifecycle-Management
HINWEIS: Die in diesem Dokument beschriebene Implementierung von Heiß-Warm-Kalt-Architekturen mit Knotenattributen (wie -Enode.attr.data=hot) wird nicht mehr empfohlen. Dieses Konzept ist durch Daten-#Tiers und die Nutzung von node.roles (wie node.roles: ["data_hot", "data_content"]) formalisiert worden. Aktuelle Informationen dazu finden Sie unter https://www.elastic.co/de/blog/elasticsearch-data-lifecycle-management-with-data-tiers.
Wenn Sie bereits eine Heiß-Warm-Kalt-Architektur mit Knotenattributen implementiert haben, wird empfohlen, die node.roles-Einstellungen für Daten-Tiers zu übernehmen und dann die Migrate-to-Data-Tiers-API zu nutzen oder die Konfiguration (wie ILM-Richtlinien, Indexeinstellungen, Indexvorlagen) manuell umzuwandeln, um die Verwendung der Daten-Tier-Voreinstellungen sicherzustellen.
Außerdem enthält dieses Dokument Verweise auf Legacy-Indexvorlagen (wie PUT _template) und weist darauf hin, dass es notwendig ist, den Index zu bootstrappen. Mittlerweile sind an die Stelle der Legacy-Indexvorlagen kombinierbare Indexvorlagen (wie PUT /_index_template) getreten, und bei Verwendung von Datenstreams entfällt die Notwendigkeit des Index-Bootstrappings.
Das Index-Lifecycle-Management (ILM) ist ein Feature, das zuerst in Elasticsearch 6.6 als Beta eingeführt und in 6.7 allgemein verfügbar gemacht wurde. ILM ist ein Teil von Elasticsearch und wurde entwickelt, um Sie bei der Verwaltung Ihrer Indizes zu unterstützen.
In diesem Blogeintrag zeigen wir Ihnen, wie Sie eine Heiß-Warm-Kalt-Architektur mit ILM implementieren können. Heiß-Warm-Kalt-Architekturen sind üblich für Zeitreihendaten wie etwa Logging- oder Metrikdaten. Nehmen Sie beispielsweise an, Elasticsearch wird verwendet, um Log-Dateien aus verschiedenen Systemen zu aggregieren. Die heutigen Logs werden aktiv indexiert, und die Logs der aktuellen Woche werden am ausführlichsten durchsucht (heiß). Die Logs der vergangenen Woche werden zwar durchsucht, aber nicht so oft wie die Logs der aktuellen Woche (warm). Die Logs des vergangenen Monats werden zwar vermutlich nicht oft durchsucht, können aber in Einzelfällen sehr hilfreich sein (kalt).
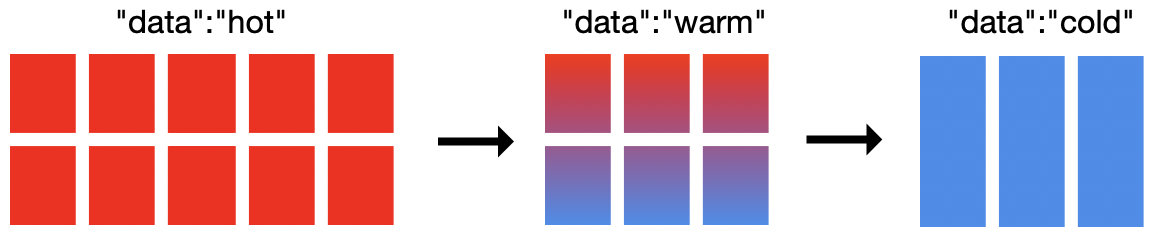
Der Cluster in der obigen Abbildung enthält 19 Knoten: 10 heiße Knoten, 6 warme Knoten und 3 kalte Knoten. Sie brauchen nicht unbedingt 19 Knoten, um Heiß-Warm-Kalt mit ILM zu implementieren, sondern mindestens 2 Knoten. Die Überlegungen zum Größenbedarf Ihres Clusters hängen von Ihren Anforderungen ab. Die kalten Knoten sind optional und bieten lediglich eine weitere Ebene im Modell, in der Sie Ihre Daten ablegen können. Mit Elasticsearch können Sie definieren, welche Knoten heiß, warm oder kalt sind. Mit ILM können Sie definieren, wann der Phasenübergang erfolgt und was mit einem Index geschieht, der eine bestimmte Phase erreicht.
Für Heiß-Warm-Kalt-Architekturen gibt es kein vorgefertigtes Schema. Normalerweise sollten Sie jedoch darauf achten, dass Ihre heißen Knoten mehr CPU-Ressourcen und schnelleres E/A bekommen. Warme und kalte Knoten benötigen oft mehr Festplattenspeicher pro Knoten, kommen dafür jedoch mit weniger CPU und E/A aus.
Ok, lassen Sie uns anfangen ...
Allocation Awareness für Shards konfigurieren
Heiß-Warm-Kalt basiert auf der Ahard Allocation Awarness. Daher markieren wir zunächst unsere heißen, warmen und (optional) unsere kalten Knoten. Dazu bearbeiten wir entweder unsere Startparameter oder die Konfigurationsdatei elasticsearch.yml. Zum Beispiel:
bin/elasticsearch -Enode.attr.data=hot
bin/elasticsearch -Enode.attr.data=warm
bin/elasticsearch -Enode.attr.data=cold
(Wenn Sie den Elasticsearch Service in der Elastic Cloud verwenden, müssen Sie für Elasticsearch 6.7+ die heiß-/warm-Vorlage auswählen)
ILM-Richtlinie konfigurieren
Als nächstes konfigurieren wir eine ILM-Richtlinie. ILM-Richtlinien können in beliebig vielen Indizes wiederverwendet werden. ILM-Richtlinien werden in vier Phasen unterteilt: heiß, warm, kalt und löschen. Sie müssen nicht jede Phase in jeder Richtlinie definieren, und ILM führt die Phasen immer in dieser Reihenfolge aus, wobei nicht definierte Phasen übersprungen werden. Für jede Phase müssen Sie festlegen, wann die Phase beginnt und welche Aktionen für Ihre Indizes ausgeführt werden sollen. Für Heiß-Warm-Kalt-Architekturen können Sie die Aktion Allocate konfigurieren, um Ihre Daten von heißen zu warmen und von warmen zu kalten Knoten zu verschieben.
Neben dem Verschieben von Daten zwischen heißen, warmen und kalten Knoten können Sie noch viele weitere Aktionen konfigurieren. Die Rollover-Aktion wird verwendet, um die Größe oder das Alter der einzelnen Indizes zu verwalten. Mit der Aktion Force Merge können Sie Ihre Indizes optimieren. Mit der Freeze-Aktion können Sie die Speicherauslastung im Cluster reduzieren. Weitere Informationen zu den vielen verfügbaren Aktionen für Ihre Elasticsearch-Version finden Sie in der Dokumentation.
Einfache ILM-Richtlinie
Dies ist eine sehr einfache ILM-Richtlinie:
PUT /_ilm/policy/my_policy
{
"policy":{
"phases":{
"hot":{
"actions":{
"rollover":{
"max_size":"50gb",
"max_age":"30d"
}
}
}
}
}
}
Diese Richtlinie legt fest, dass nach 30 Tagen oder wenn der Index eine Größe von 50 GB erreicht hat (auf Basis der primären Shards), ein Rollover ausgeführt und die Daten anschließend in einen neuen Index geschrieben werden.
ILM und Indexvorlagen
Anschließend müssen wir die ILM-Richtlinie zu einer Indexvorlage zuordnen:
PUT _template/my_template
{
"index_patterns": ["test-*"],
"settings": {
"index.lifecycle.name": "my_policy",
"index.lifecycle.rollover_alias": "test-alias"
}
}
Anmerkung: Beim Angeben der Rollover-Aktion müssen Sie die ILM-Richtlinie in einer Indexvorlage angeben (anstatt direkt im Index).
Wenn eine Richtlinie die Rollover-Aktion enthält, müssen Sie den Index außerdem mit einem Schreib-Alias bootstrappen, nachdem Sie die Indexvorlage erstellt haben.
PUT test-000001
{
"aliases": {
"test-alias":{
"is_write_index": true
}
}
}
Wenn alle Voraussetzungen für einen Rollover erfüllt sind, wird für alle neuen Indizes, die mit test-* beginnen, automatisch nach 30 Tagen oder 50 GB ein Rollover ausgeführt. Wenn Sie Rollover für Ihre Indizes nach max_size konfigurieren, können Sie die Anzahl der Shards (und damit den Mehraufwand) für Ihre Indizes deutlich reduzieren.
ILM-Richtlinie für Ingestion konfigurieren
Beats und Logstash unterstützen ILM und richten eine Standardrichtlinie ein, die dem oben gezeigten Beispiel ähnelt. Beats und Logstash verarbeiten außerdem sämtliche Voraussetzungen für die Rollover-Aktion . Wenn ILM für Beats und Logstash aktiviert ist und Sie keine extrem großen täglichen Indizes haben (> 50 GB / Tag), dann ist die Größe vermutlich der wichtigste Faktor für die Erstellung neuer Indizes. Dies ist ein gutes Zeichen! ILM mit Rollover wird ab 7.0.0 für Beats und Logstash als Standard verwendet.
Da es für Heiß-Warm-Kalt-Architekturen jedoch keine Standardlösung gibt, werden Beats und Logstash nicht mit Heiß-Warm-Kalt-Richtlinien ausgeliefert. Wir können eine neue Richtlinie erstellen, die Heiß-Warm-Kalt unterstützt, und nebenbei einige Optimierungen vornehmen.
Wir könnten die Standardrichtlinie für Beats oder Logstash anpassen. Damit verwischen wir jedoch die Trennlinie zwischen vorkonfiguriertem und benutzerdefiniertem Verhalten. Wenn wir die Standardrichtlinie ändern, riskieren wir außerdem, dass in zukünftigen Versionen nicht die richtige Richtlinie angewendet wird (die Beats-Standardvorlagen ändern sich mit 7.0+). Wir könnten die Beats- und Logstash-Konfigurationen verwenden, um eigene Richtlinien über die jeweilige Konfiguration zu definieren. Dieser Ansatz funktioniert, aber möglicherweise möchten Sie nicht die Konfiguration für Hunderte (oder Tausende) von Beats ändern, um die ILM-Richtlinie anzupassen. Der dritte Ansatz verwendet den mehrfachen Vorlagenabgleich, um Elasticsearch vollständige Kontrolle über die ILM-Richtlinie zu geben.
ILM-Richtlinie für Heiß-Warm-Kalt optimieren
Wir werden zunächst eine ILM-Richtlinie erstellen, die für eine Heiß-Warm-Kalt-Architektur optimiert ist. Auch hier gibt es keine Standardlösung, und Sie haben vermutlich andere Anforderungen.
PUT _ilm/policy/hot-warm-cold-delete-60days
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size":"50gb",
"max_age":"30d"
},
"set_priority": {
"priority": 50
}
}
},
"warm": {
"min_age": "7d",
"actions": {
"forcemerge": {
"max_num_segments": 1
},
"shrink": {
"number_of_shards": 1
},
"allocate": {
"require": {
"data": "warm"
}
},
"set_priority": {
"priority": 25
}
}
},
"cold": {
"min_age": "30d",
"actions": {
"set_priority": {
"priority": 0
},
"freeze": {},
"allocate": {
"require": {
"data": "cold"
}
}
}
},
"delete": {
"min_age": "60d",
"actions": {
"delete": {}
}
}
}
}
}
Heiß
Diese ILM-Richtlinie legt zunächst die Indexpriorität auf einen hohen Wert fest, damit heiße Indizes vor anderen Indizes wiederhergestellt werden. Nach 30 Tagen oder 50 GB (je nachdem, was zuerst eintrifft) wird ein Rollover für den Index ausgeführt, und ein neuer Index wird erstellt. Mit dem neuen Index beginnt die Richtlinie erneut, und der aktuelle Index (für den soeben ein Rollover ausgeführt wurde) wartet bis zu sieben Tage, nachdem der Rollover in die warme Phase ausgeführt wurde.
Warm
Wenn sich der Index in der warmen Phase befindet, schrumpft ILM den Index auf eine Shard, führt ein Force Merge des Index auf ein Segment durch, setzt die Indexpriorität auf einen niedrigeren Wert als heiß (aber höher als warm) und verwendet die Aktion Allocation, um den Index auf die warmen Knoten zu verschieben. Dort wartet der Index 30 Tage (ab dem Rollover), bis er in die kalte Phase eintritt.
Kalt
Sobald der Index in die kalte Phase eintritt, reduziert ILM die Indexpriorität erneut, um sicherzustellen, dass heiße und warme Indizes zuerst wiederhergestellt werden. Anschließend wird der Index eingefroren und auf den oder die kalten Knoten verschoben. Dort wartet der Index 60 Tage (ab dem Rollover), bis er in die Löschphase eintritt.
Löschen
Wir haben uns noch nicht mit der Löschphase befasst. Kurz gesagt ... In der Löschphase wird die Löschaktion ausgeführt, die den Index löscht. Sie sollten immer ein min_age für die Löschphase festlegen, damit Ihr Index für den gewünschten Zeitraum in der heißen, warmen oder kalten Phase bleiben kann.
ILM-Richtlinie in Kibana erstellen
Sie haben keine Lust, JSON-Code zu schreiben? (Ich auch nicht.) Lassen Sie uns die Richtlinie in der Kibana-Benutzeroberfläche erstellen:
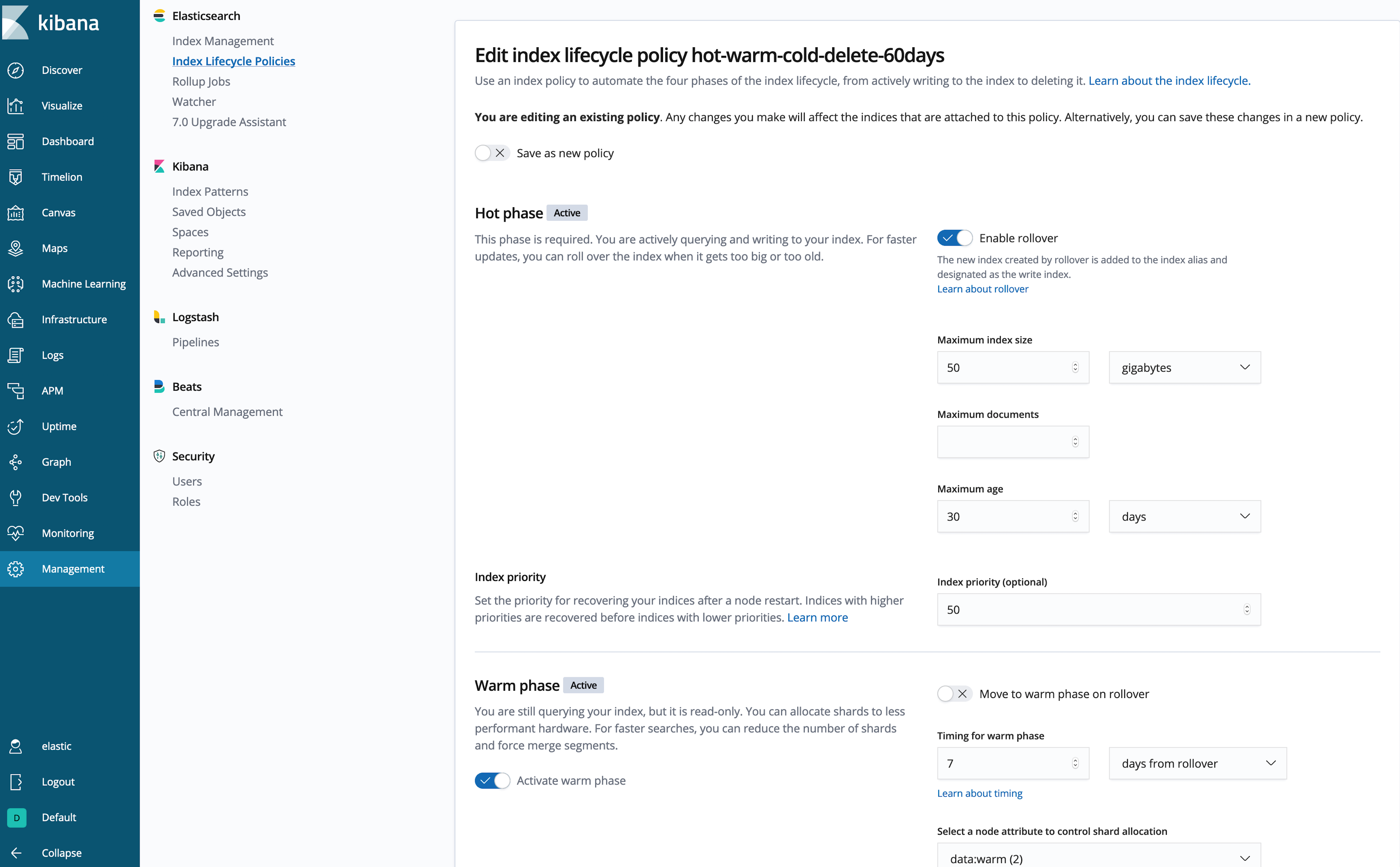 Schon viel besser!
Schon viel besser!
Anschließend müssen wir die Richtlinie hot-warm-cold-delete-60days zu den Beats- und Logstash-Indizes zuweisen und sicherstellen, dass diese in die heißen Datenknoten schreiben. Da Beats und Logstash (standardmäßig) jeweils ihre eigenen Vorlagen verwalten, werden wir den mehrfachen Vorlagenabgleich verwenden, um die Richtlinie und die Zuweisungsregeln hinzuzufügen, die Sie auf die ILM-Richtlinie anwenden möchten. Da diese Vorlage mit den Beats- und Logstash-Indexmustern übereinstimmt, müssen Sie wissen, für welche Indexmuster Sie eine Übereinstimmung möchten. In diesem Beispiel verwenden wir „logstash-“, „metricbeat-“ und „filebeat-*“. Sie können jedoch beliebig viele Muster hinzufügen, sofern die ILM-Unterstützung in der jeweiligen Konfiguration von Beats bzw. Logstash aktiviert ist. Wenn Sie hier Indexmuster für Datenproduzenten hinzufügen, die kein ILM unterstützen, müssen Sie die Voraussetzungen für den Rollover in dieser Richtlinie manuell erfüllen.
PUT _template/hot-warm-cold-delete-60days-template
{
"order": 10,
"index_patterns": ["logstash-*", "metricbeat-*", "filebeat-*"],
"settings": {
"index.routing.allocation.require.data": "hot",
"index.lifecycle.name": "hot-warm-cold-delete-60days"
}
}
ILM in Beats und/oder Logstash aktivieren
Lassen Sie uns zuletzt noch ILM für Beats und Logstash aktivieren.
Für Beats 6.7:
output.elasticsearch:
ilm.enabled: true
Für Logstash 6.7:
output {
elasticsearch {
ilm_enabled => true
}
}
Die Aktivierung in Beats und Logstash kann sich in neueren Versionen ändern. Beachten Sie daher die Dokumentation für Ihre jeweilige Version.
Ab sofort wird jeder Index, der mit dem Indexmuster übereinstimmt, neue Indizes auf den heißen Knoten erstellen, und ILM wird die Richtlinie hot-warm-cold-delete-60days anwenden.
ILM-Richtlinie aktualisieren
Sie können die ILM-Richtlinie jederzeit aktualisieren … Änderungen an der Richtlinie werden jedoch nur bei Phasenübergängen berücksichtigt. Angenommen, Ihr Index ist momentan in der heißen Phase und wartet auf die warme Phase. Änderungen an der heißen Phase werden für diesen Index nicht mehr übernommen, aber alle Änderungen an der warmen Phase werden übernommen, sobald der Index in diese Phase eintritt. Auf diese Weise müssen die Aktionen für eine bestimmte Phase nicht wiederholt werden. Sie können den ILM-Status für den Index mit der Explain API abrufen.
Viele der älteren Informationen für Heiß-Warm-Architekturen ohne ILM gelten weiterhin, da ILM auf denselben Techniken beruht. Mit ILM ist jedoch kein Curator mehr erforderlich, um dieses Muster zu erreichen.
Blick nach vorne
Ab Version 7.0 verwenden Beats und Logstash standardmäßig das Index-Lifecycle-Management, wenn sie sich mit einem Cluster verbinden, der das Lifecycle-Management unterstützt. Außerdem wurde ein Großteil der ILM-Einstellungen in Beats vom Namespace output.elasticsearch.ilm nach setup.ilm verschoben. Beachten Sie beispielsweise die Dokumentation für Filebeat 7.0. Ab Version 7.0 können außerdem Systemindizes wie .watcher-history-* mit ILM verwaltet werden.
Mit ILM können Sie mühelos eine kostensparende Architektur wie etwa Heiß-Warm-Kalt für Ihre Zeitreihenindizes implementieren. Probieren Sie die Lösung noch heute aus uns schreiben Sie uns Ihre Meinung in unseren Diskussionsforen. Viel Spaß!