Elastic Observability: MTTR komplett eliminieren


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Auf der Veranstaltung ElasticON Global 2021 haben Tanya Bragin, VP Product, Observability und das Elastic Observability-Team gezeigt, wie Sie dank fortlaufender Innovationen auch weiterhin verwertbare Einblicke liefern und Problemursachen schneller erkennen können, um die mittlere Reparaturdauer (Mean Time To Resolution, MTTR) zu reduzieren.
Mit der Einführung von Cloud, Microservices und kurzlebigen Infrastrukturen hat die Komplexität zugenommen, und wir brauchen Observability-Lösungen für End-to-End-Einblicke. Elastic Observability wurde bereits von Gartner, GigaOm und EMA anerkannt und bietet weiterhin eine umfassende Lösung mit Funktionen in den folgenden Bereichen:
- Einheitlicher Agent zum Ingestieren sämtlicher Telemetriedaten mit zentralisierter Verwaltung
- Integration mit cloudnativen Technologien (z. B. Kubernetes)
- Native Integrationen mit wichtigen Cloudanbietern, inklusive Amazon Web Services, Microsoft Azure und Google Cloud Platform
- Automatisierte Ursachenanalysen im Monitoring der Anwendungsleistung (Application Performance Monitoring, APM) mit Machine Learning
- Verbesserte APM-Fehlerbehebungs-Workflows mit Integration von Logs, externen Abhängigkeiten und Backend-Diensten
- Intuitive Service Maps für kontextbezogene Fehlerbehebung
- Unterstützung für OpenTelemetry (OTel)
- Erweiterungen für Synthetics und Real User Monitoring (RUM)
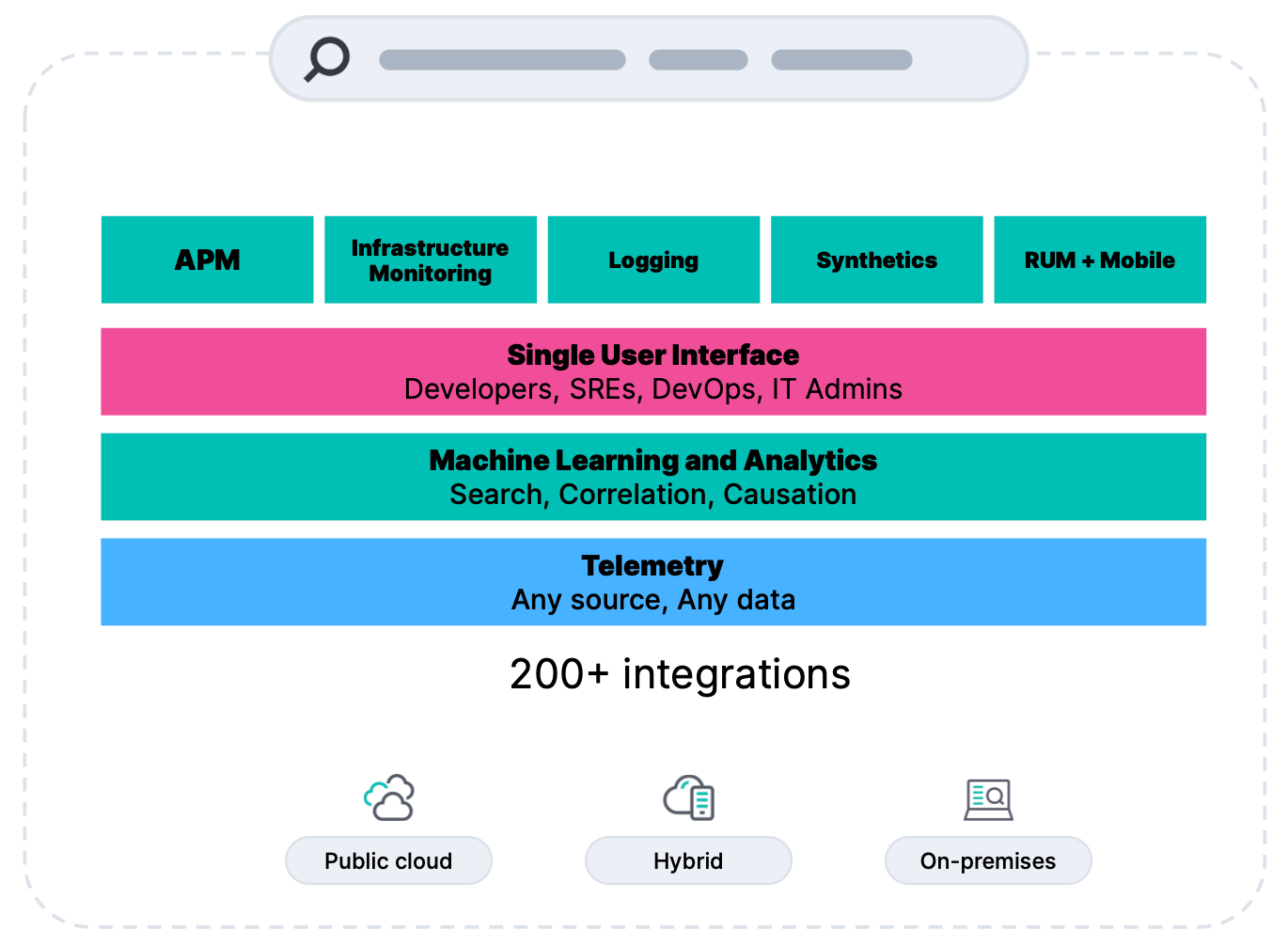
Relevante, kontextbezogene und nutzbare Daten
Operations- und Entwicklungsteams müssen oft mit separaten Tools für Metriken, Logs und Traces arbeiten. Selbst mit einem einheitlichen Tool befinden sich die Daten oft in Silos ohne Kontext oder relevante Metadaten (Dimensionalität), wodurch die mittlere Erkennungsdauer (MTTD) und Behebungsdauer (MTTR) zunehmen. Elastic Observability skaliert nahtlos für große Datenmengen mit hoher Dimensionalität und Kardinalität ohne Leistungseinbußen oder unerwartete Kosten.
Dank dem reibungslosen Onboarding mit dem Elastic Agent und der zentralisierten Verwaltung können Sie sämtliche Telemetriedaten mühelos erfassen, inklusive cloudnativer Technologien wie etwa Kubernetes. Außerdem haben wir Integrationen für Microsoft Azure und Google Cloud Platform hinzugefügt, um Telemetriedaten nativ ingestieren zu können. Weitere Integrationen sind auf dem Weg.
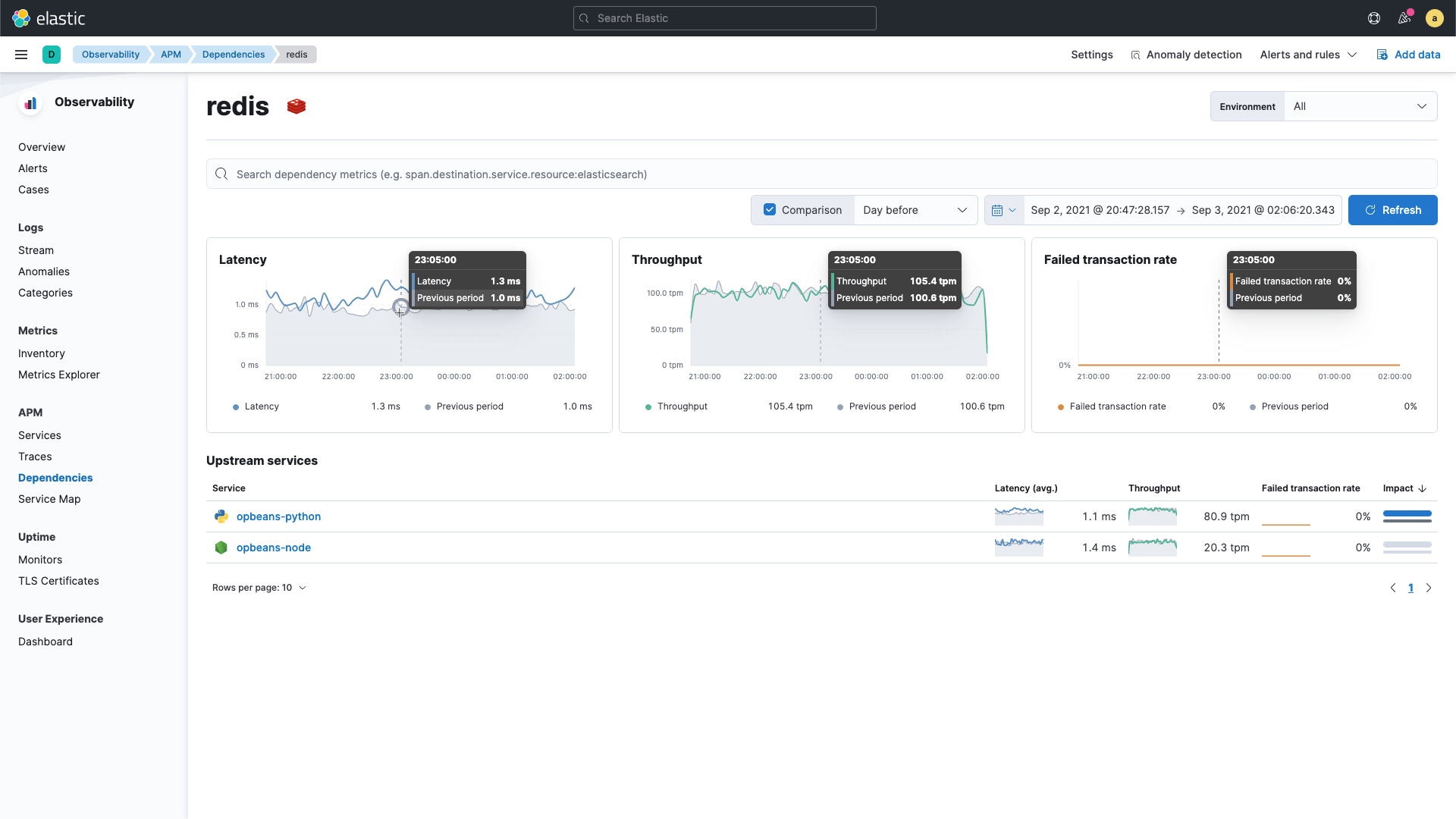
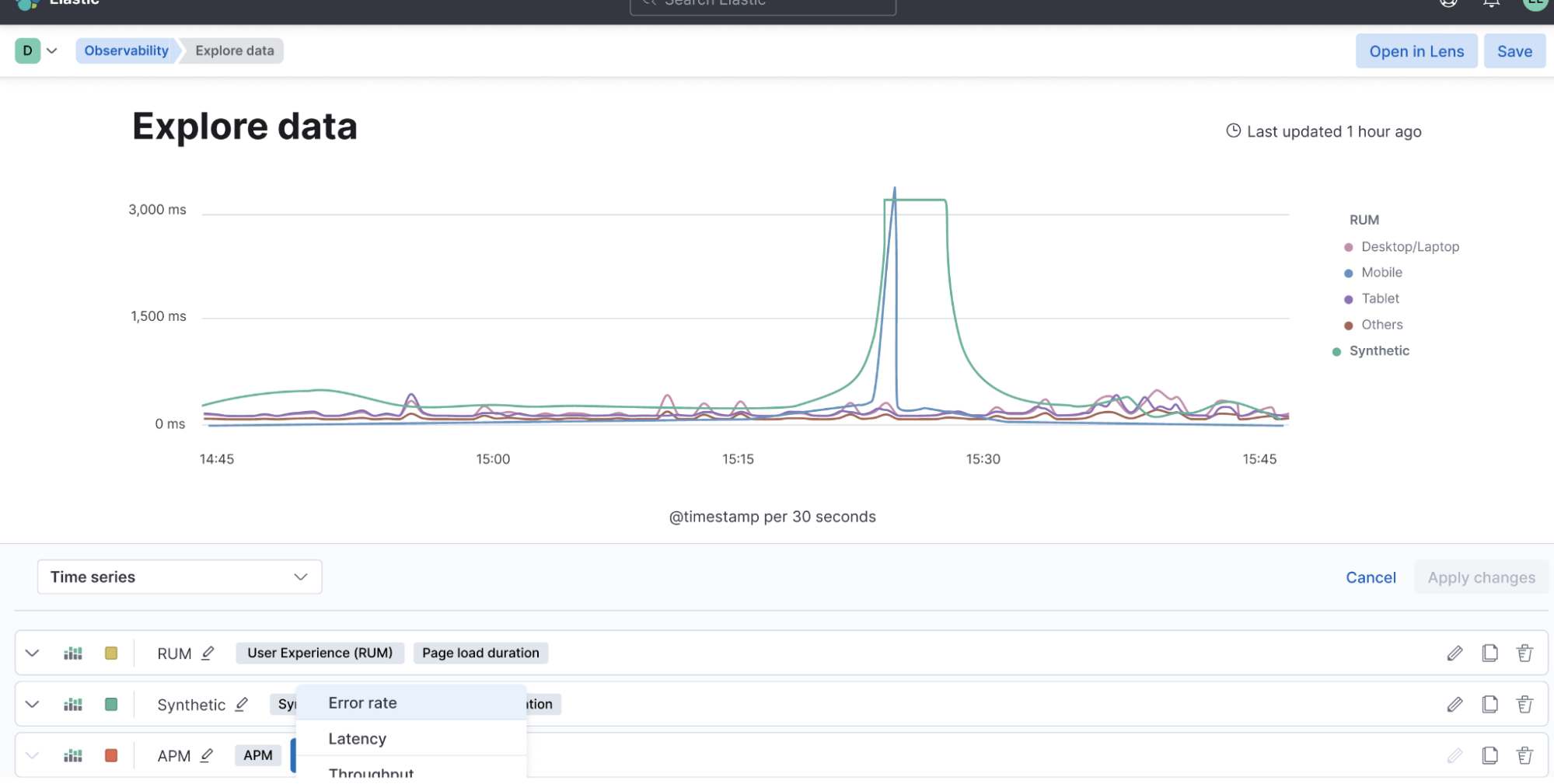
Kontext ist erforderlich, um Incidents schnell und effektiv beheben zu können. Elastic APM Service Maps visualisieren die Anwendungstopologie und beschleunigen die Fehlerbehebung, da Sie jederzeit den Status von Diensten, erkannte Anomalien und Logs im Kontext der jeweiligen Transaktionen griffbereit haben. Außerdem können Sie die Leistung von Diensten mit historischen Baselines vergleichen, um Abweichungen mühelos zu erkennen. Mit unseren neu hinzugefügten Leistungsansichten für externe Dienstabhängigkeiten haben wir blinde Flecken aus Ihrer Umgebung eliminiert. Mit der Unterstützung für mobile iOS Agents (momentan als Technical Preview verfügbar) werden wir unsere APM-Funktionen weiter ausbauen.
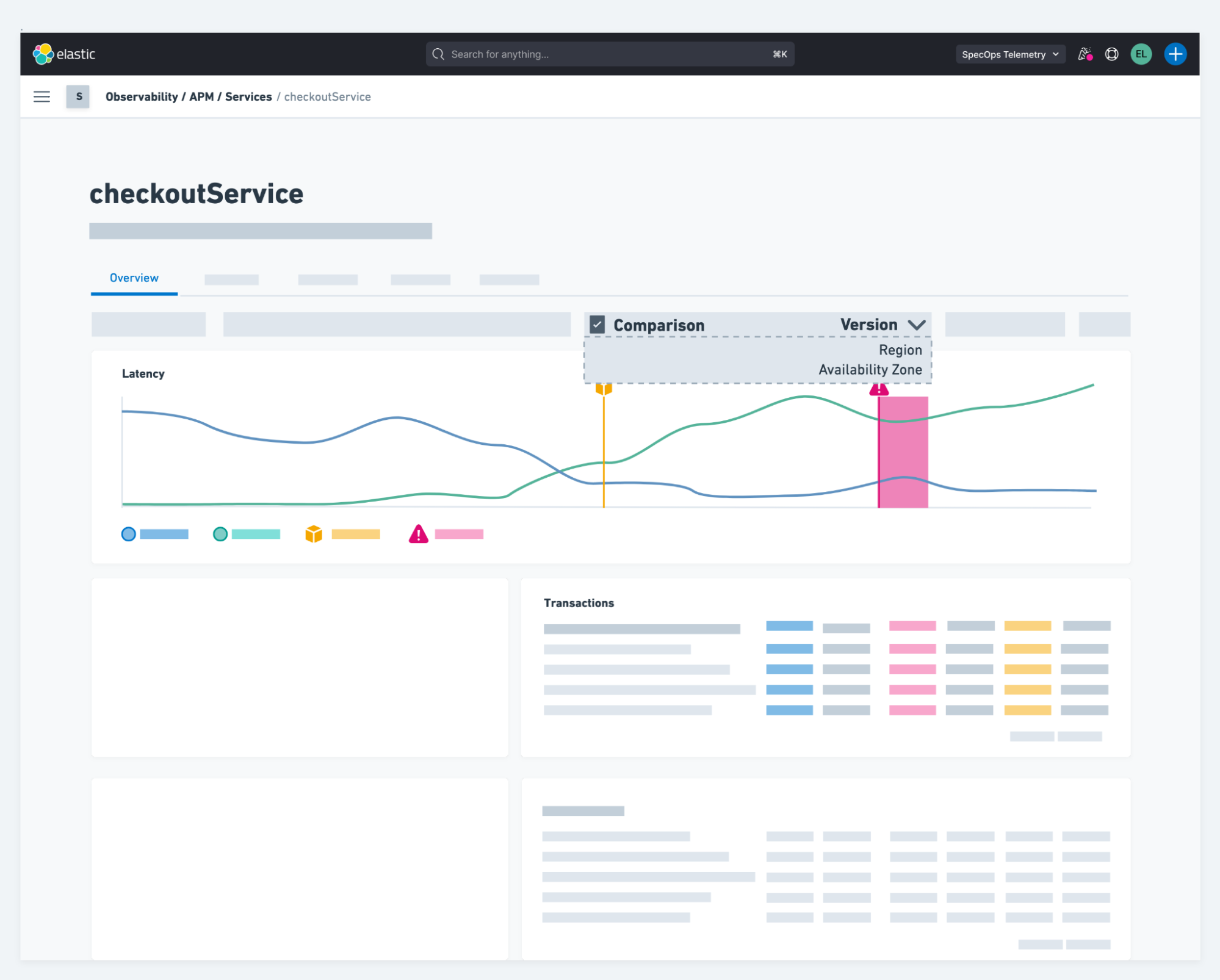
Unser nächster Schritt auf dem Weg zur totalen Transparenz ist die Bereitstellung von Kontext zwischen Ihrer Anwendung und Ihrer Infrastruktur. Die Leistung von Anwendungen wird oft durch Leistungsprobleme in der Infrastruktur beeinträchtigt. Wir werden Ihnen die Möglichkeit bieten, die Infrastrukturleistung im Kontext zur Anwendungsleistung und den relevanten Logs anzuzeigen, um eine einheitliche Observability zu erreichen. Wir wurden außerdem gebeten, Vergleichsmöglichkeiten für die Leistung von Diensten über Versionen, Cloudregionen, Verfügbarkeitszonen und andere Metadaten hinweg anzubieten. Mit dieser Funktion können Sie in Zukunft die Leistung zwischen A/B oder mit Canary-Deployments vergleichen, um Fehler oder Deployment-Probleme schnell zu beheben.
Ad-Hoc-Analytics und Machine Learning
Angesichts moderner, verteilter Anwendungen und Petabyte von täglich generierten Telemetriedaten haben weder Teams noch Einzelpersonen den vollständigen Überblick über sämtliche Abhängigkeiten. Teams benötigen Machine Learning, um komplexe Probleme effektiv zu beheben, indem sie umsetzbare Erkenntnisse gewinnen und in der Lage sind, Fragen an Ihre Daten zu stellen.
Die Elastic-Plattform liefert umfassende vorkonfigurierte Machine Learning-Funktionen sowie die Möglichkeit, eigene benutzerdefinierte Machine Learning-Aufträge zu erstellen. Unsere APM-Korrelationsfunktionen arbeiten hinter den Kulissen mit Machine Learning, um Abweichungen in der Anwendungsleistung zu analysieren und problematische Dienste zu identifizieren. Auf diese Weise müssen Sie weniger Daten durchsuchen und analysieren und können Ihre Ausfallzeiten reduzieren und die Produktivität Ihrer Entwickler steigern.
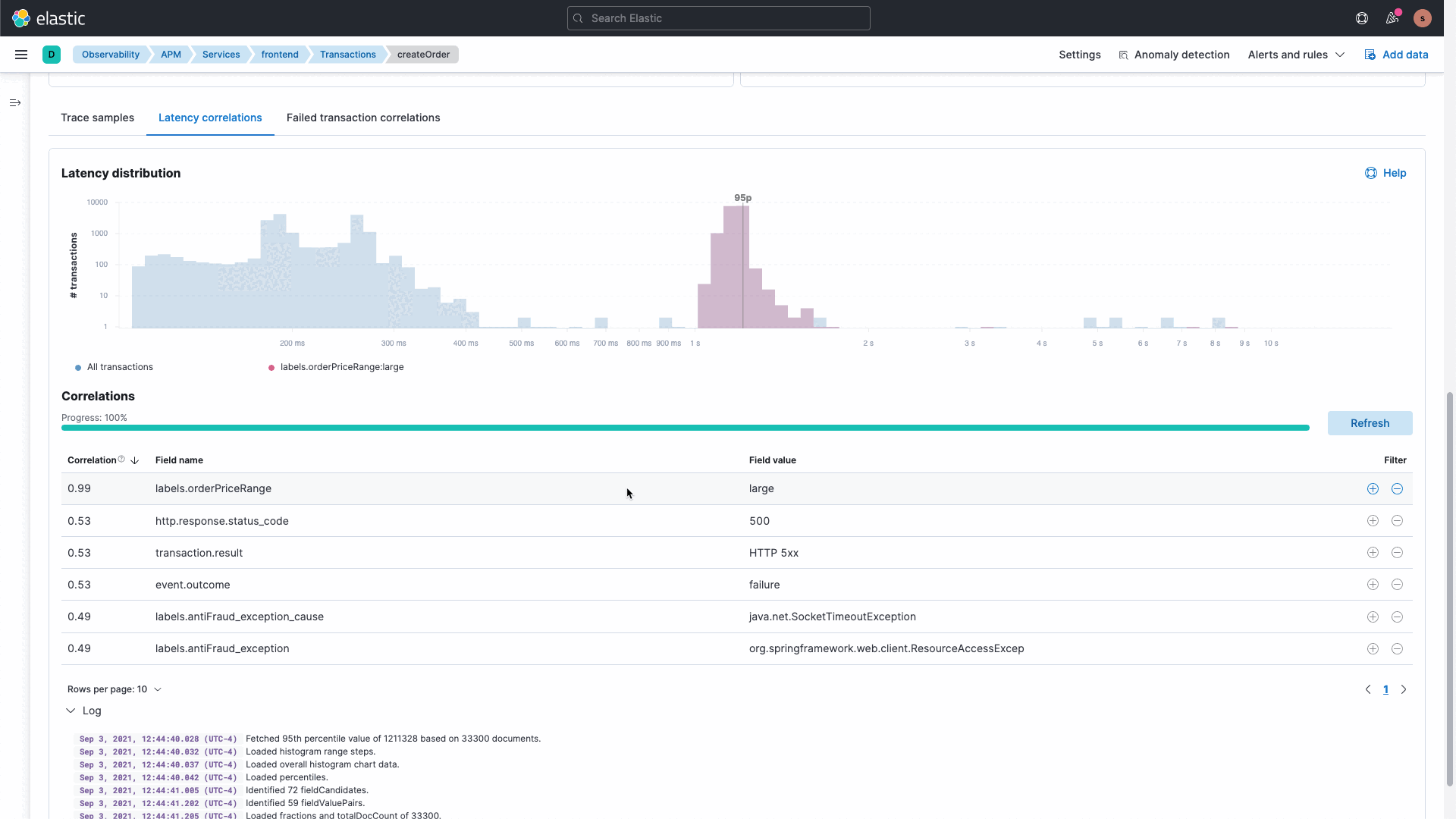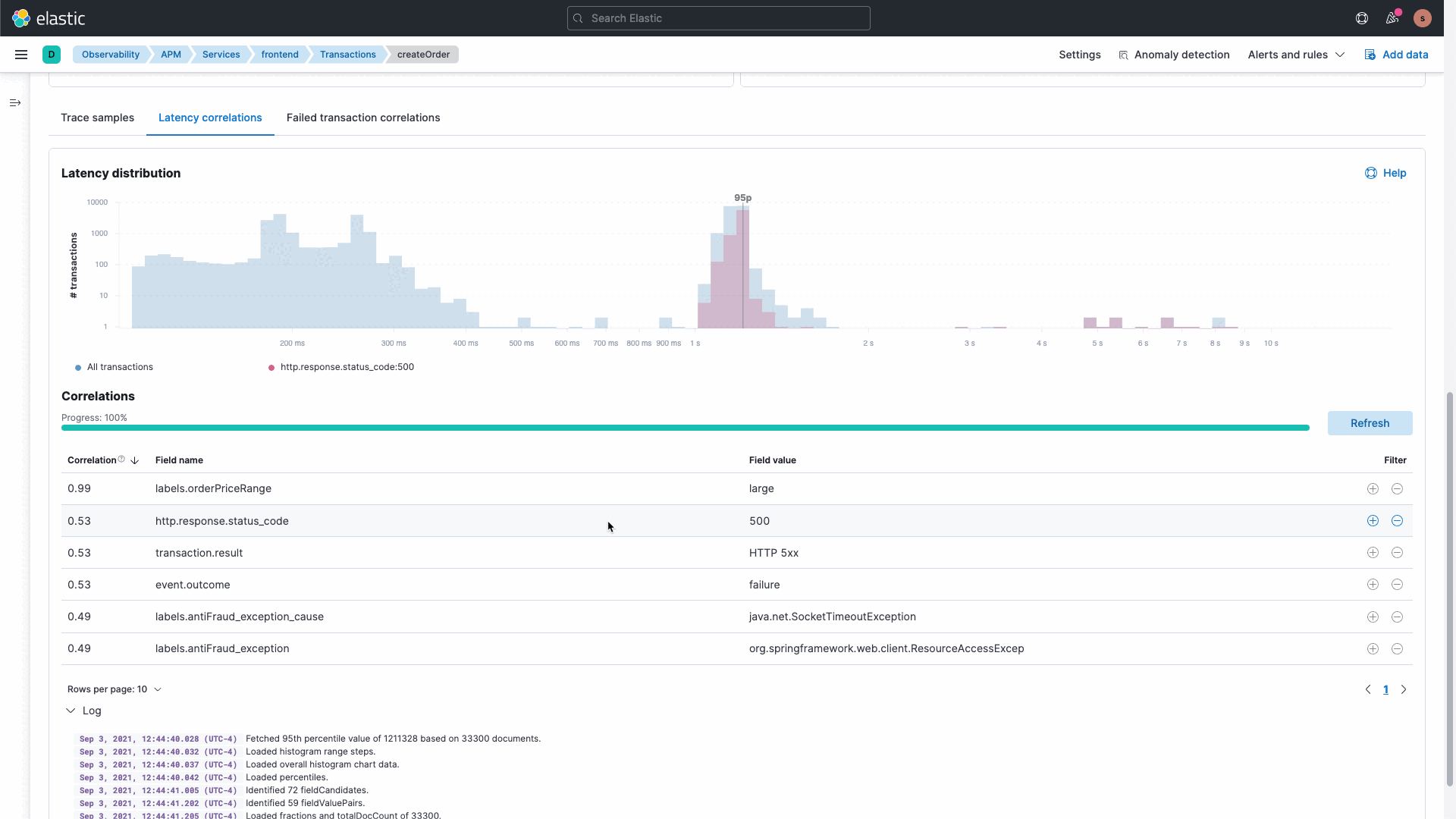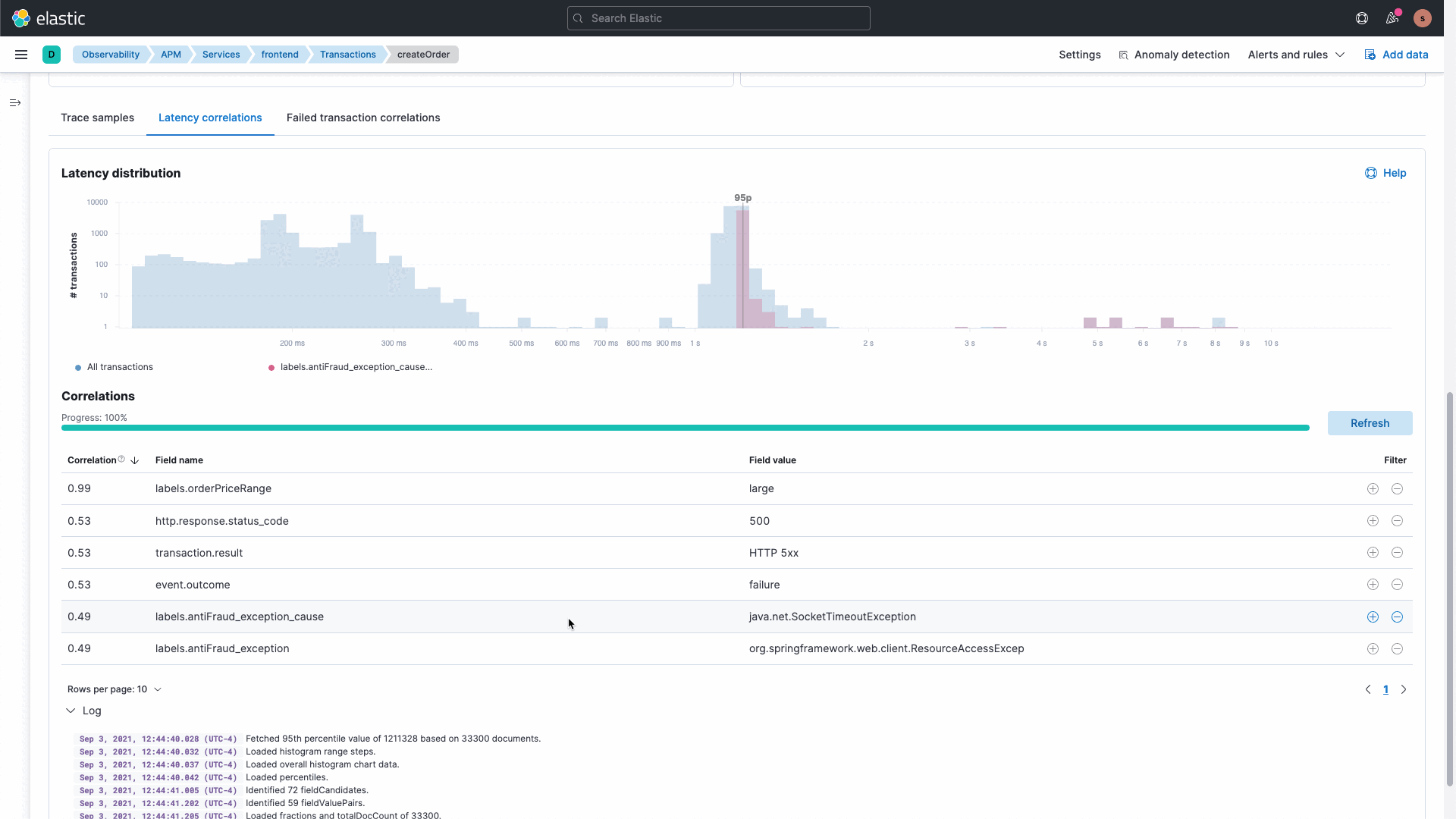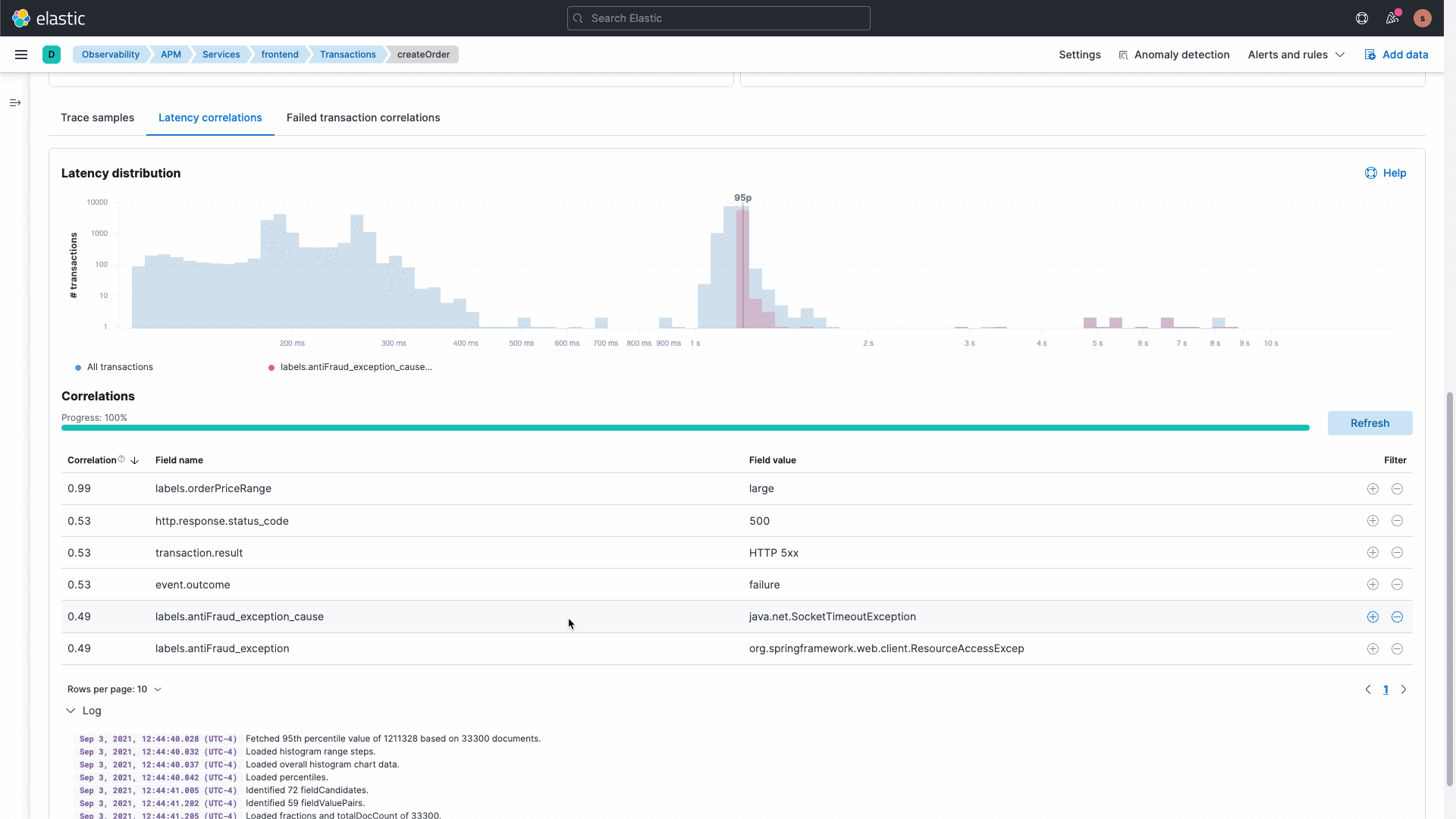
Wir kennen die Komplexität von Systemen und wissen, dass IT Ops-, SRE- und DevOps-Teams Daten analysieren und untersuchen müssen, um Erkenntnisse zu gewinnen. Wir werden demnächst eine neue und intuitive GUI allgemein verfügbar machen, mit der Sie Fragen stellen und die Datenerkundung für unterschiedliche Gruppen kuratieren können. Mit dieser Funktion erhalten Sie Overlay-, Filter- und Erkundungsfunktionen für Daten aus unterschiedlichen Quellen und mit verschiedenen Datentypen. Mit der interaktiven und kuratierten Ad-Hoc-Datenerkundungsansicht können Sie in Ihre Daten eintauchen, neue Erkenntnisse gewinnen und Problemursachen schneller aufdecken.
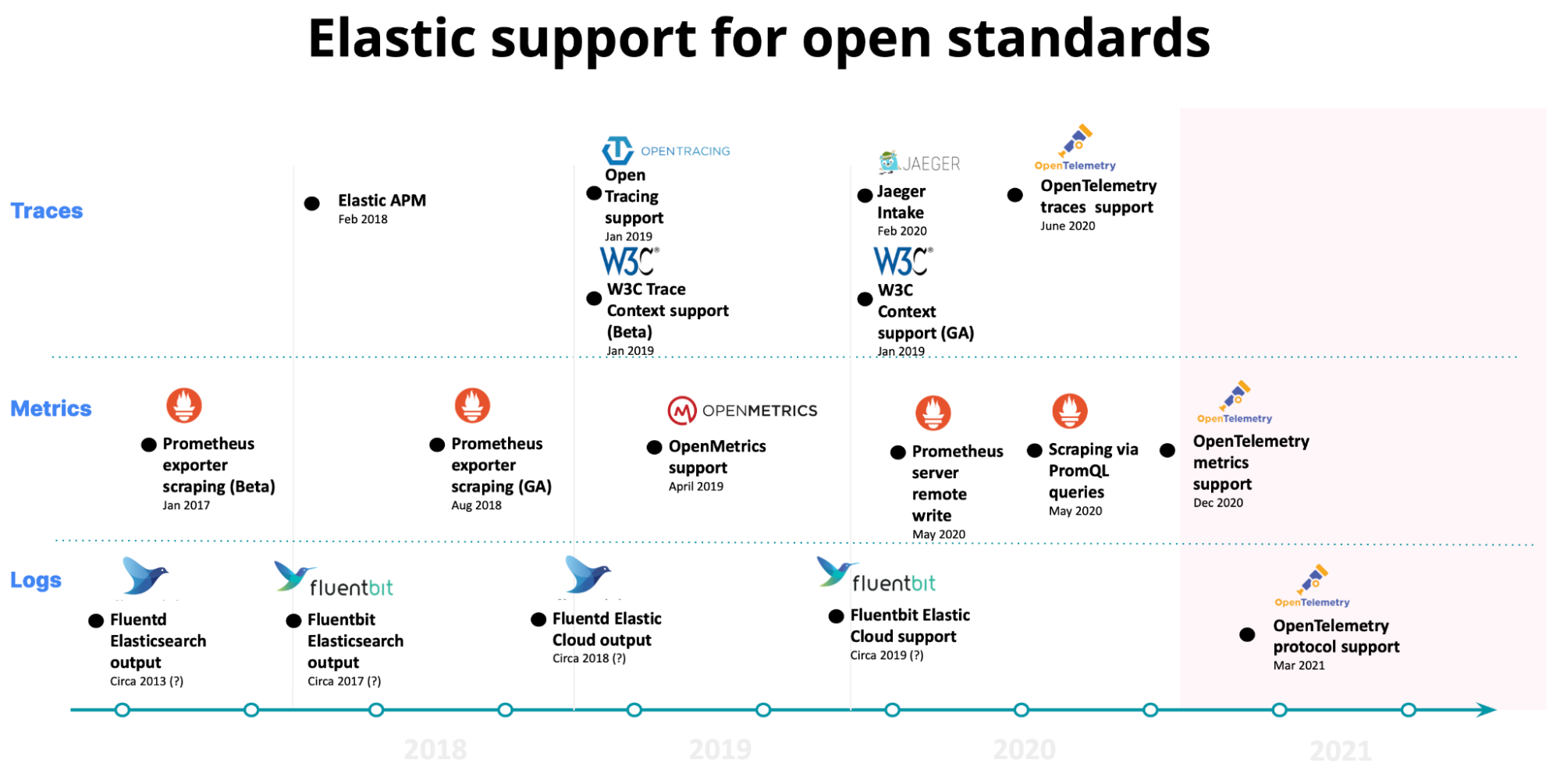
Offenheit liegt in unserer DNA
Elastic Observability basiert auf einem offenen Fundament, und Sie erhalten maximale Kontrolle und Flexibilität für Ihre Leistungsüberwachungsdaten. Unsere andauernde Unterstützung für Open Source-Projekte hat maßgeblich dazu beigetragen, unsere Produkt-Roadmap zu formen und zu definieren. Von OpenTracing und OpenMetrics über Jaeger, Prometheus bis hin zu OpenTelemetry waren wir schon immer Early Adopter von offenen Standards und Protokollen.
Prometheus ist der Branchenstandard für Metriken und bietet einen offenen Standard für die Speicherung von Metriken. Elastic Observability ist mit Prometheus integriert, um Ihnen eine Möglichkeit zum Speichern und Analysieren von Metriken zu bieten. OpenTelemetry (OTel) ist ein CNCF-Projekt, das allgemeine und offene Standards für Metriken, Logs und Traces entwickelt. Elastic unterstützt OpenTelemetry nativ über einen OTel-Protokoll-Endpunkt (OTLP) oder als Streaming über Kafka an die Elastic-Plattform. Elastic Observability wird auch weiterhin in Open Source-Projekte investieren und diese unterstützen, weil wir der Ansicht sind, dass unsere Kunden mehr Auswahl und Kontrolle über ihren Betrieb haben sollten.
Unsere Arbeit geht mit Ihrer Hilfe weiter
Wir hören auch weiterhin genau auf unsere Kunden und bieten eine umfassende und einheitliche Observability-Plattform an. Wir bieten eine extrem robuste Enterprise Search-Plattform und ständige Innovation zur Unterstützung komplexer IT-Umgebungen. Dank der aktiven Teilnahme unserer Community liefert Elastic Observability auch weiterhin Einblicke in Ihre cloudnativen und Hybridumgebungen mit einer offenen und erweiterbaren Plattform.
Um mehr über die Elastic Observability-Vision zu erfahren, sehen Sie sich die Keynote und weitere Observability-Sitzungen von ElasticON Global On-Demand an oder entdecken Sie die Elastic Observability-Seite auf der Elastic-Website.
Die Entscheidung über die Veröffentlichung der in diesem Blogpost beschriebenen Leistungsmerkmale und Features oder deren Zeitpunkt liegt allein bei Elastic. Es ist möglich, dass nicht bereits verfügbare Leistungsmerkmale oder Features nicht rechtzeitig oder überhaupt nicht veröffentlicht werden.
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken