核心能力
观察您的代理 AI 堆栈的每一层
监测性能、控制成本、跟踪防护措施并保持 GenAI 工作负载可靠运行。




从库到模型,我们都能满足您的需求
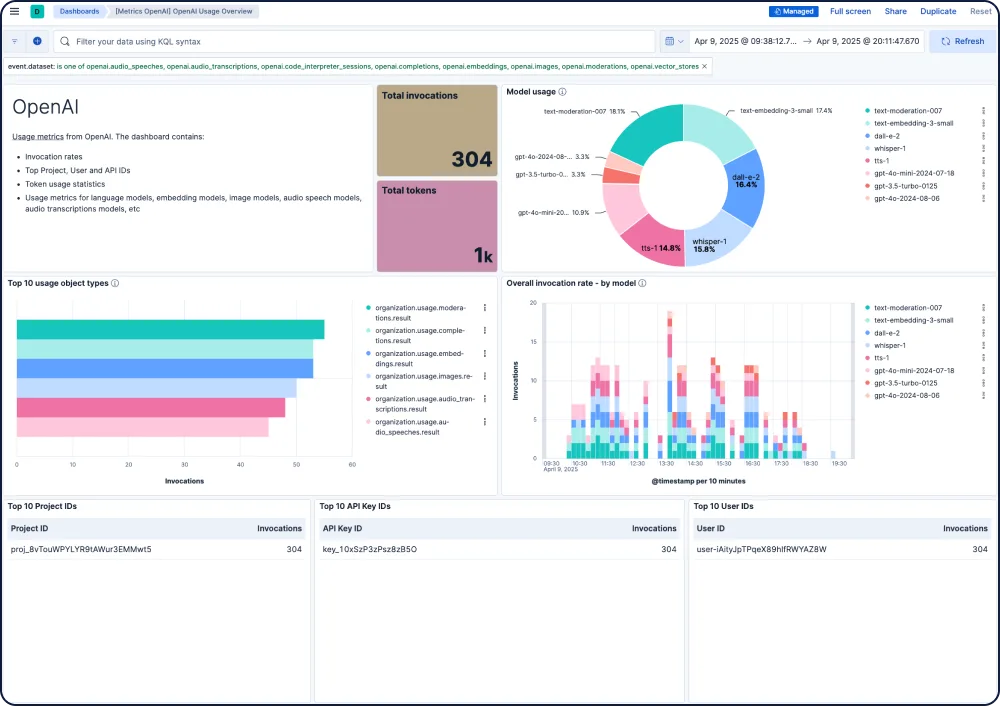
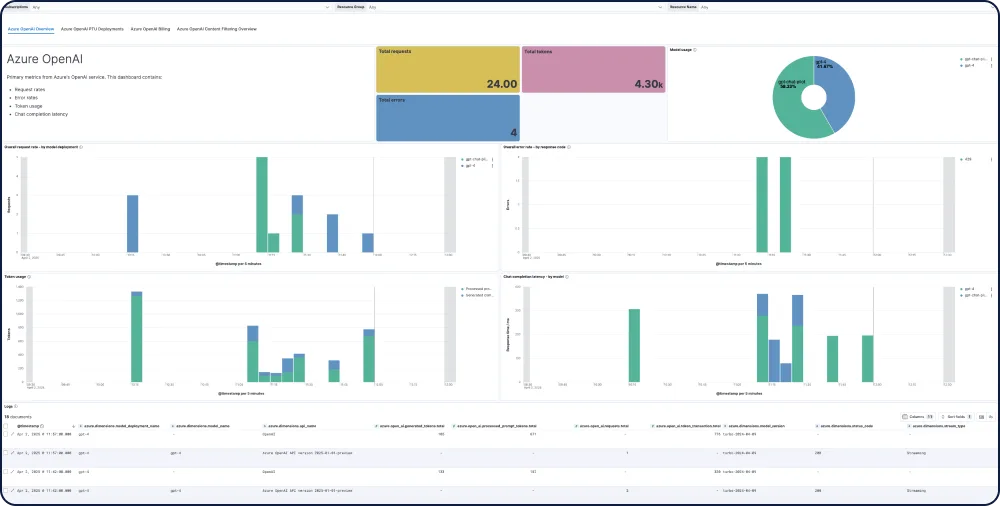
Elastic 可为 AI 应用提供端到端的可见性,与流行的跟踪库集成,并提供对所有主要 LLM 提供商(包括 GPT-4o、Mistral、LLaMA、Anthropic、Cohere 和 DALL·E)模型的开箱即用的见解。









仪表板图库
适用于您的 AI 应用的集成和功能
跟踪每个模型的性能、安全性和支出。
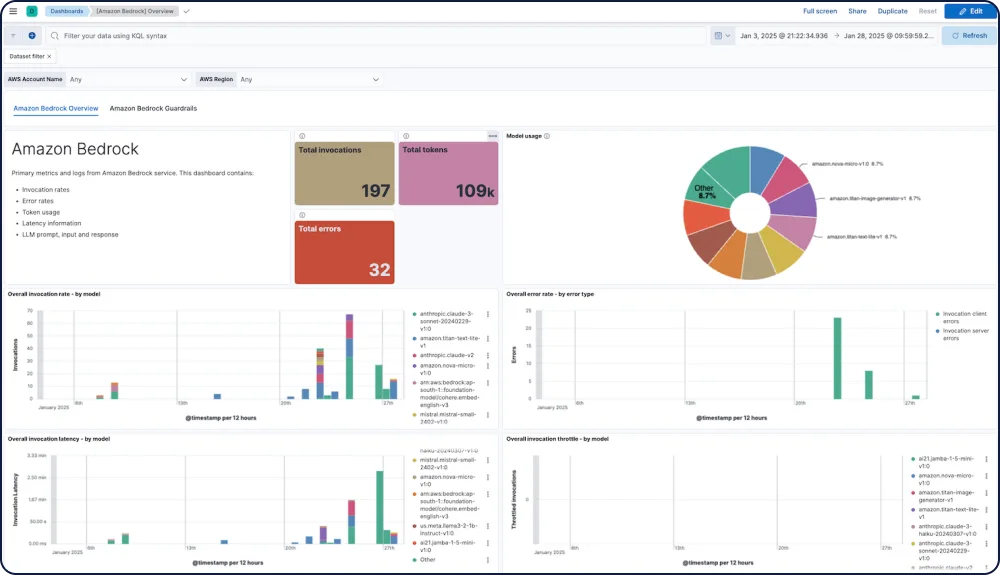
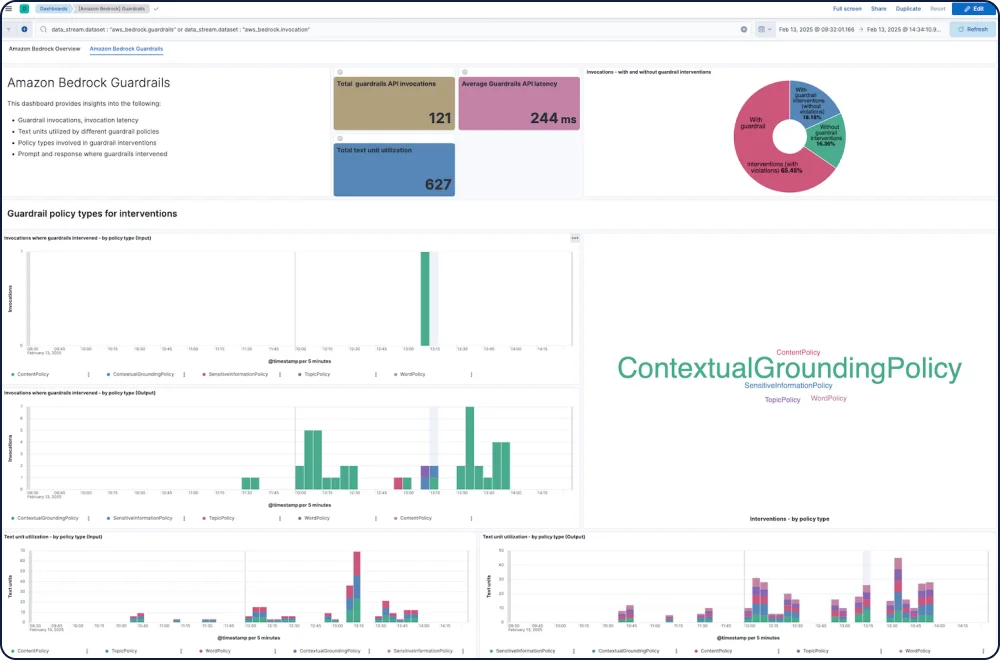
Amazon Bedrock 集成为 Elastic Observability 提供了对 Amazon Bedrock LLM 性能、使用情况和安全性的全面可见性,包括来自 Anthropic、Mistral 和 Cohere 的模型。
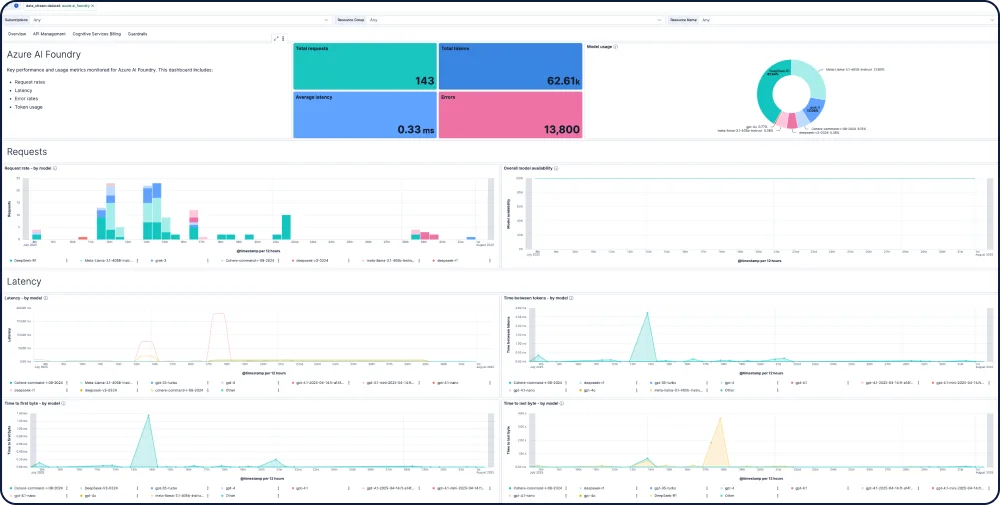
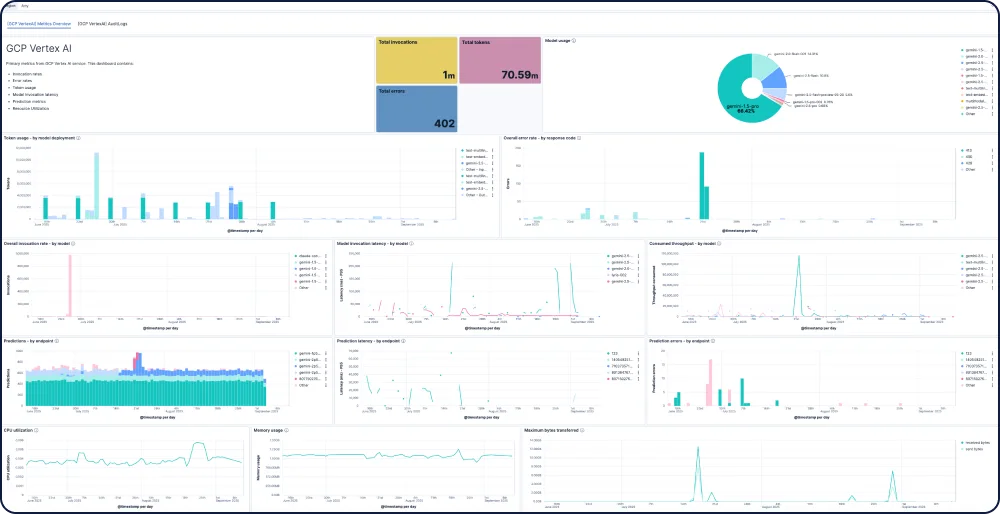
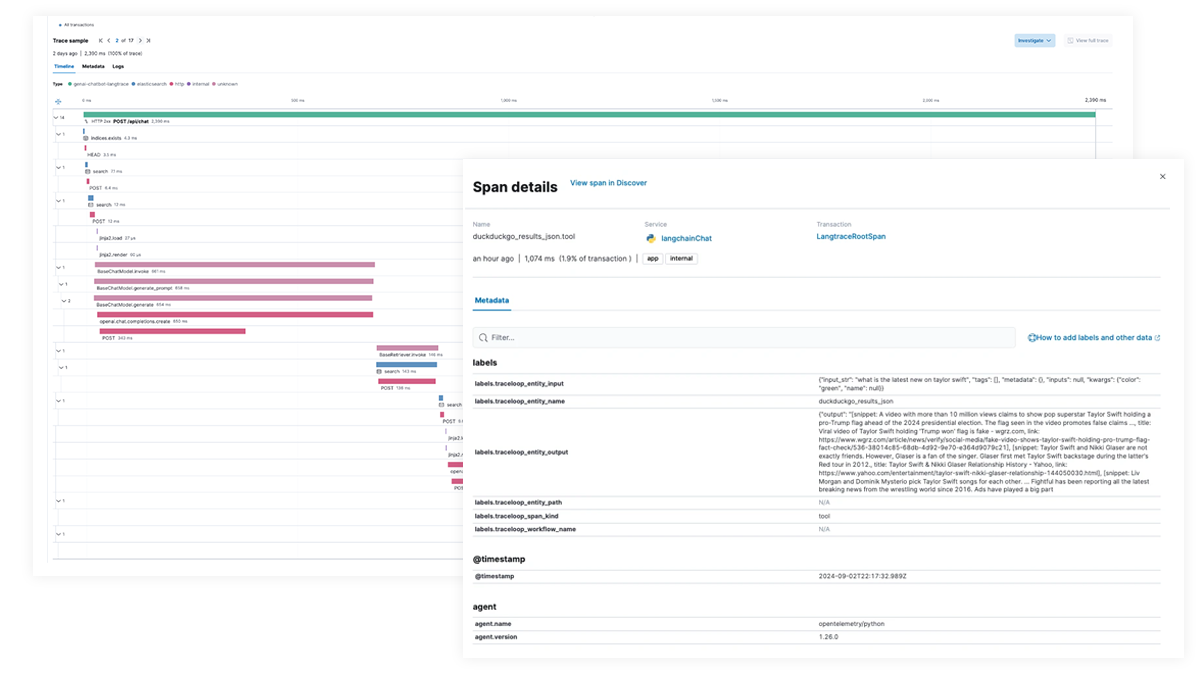
面向 AI 应用和代理工作流的端到端跟踪和调试
使用 Elastic APM 通过 OpenTelemetry 分析和调试 AI 应用,通过面向 Python、Java 和 Node.js 的 Elastic Distributions of OpenTelemetry (EDOT) 以及 LangTrace、OpenLIT 和 OpenLLMetry 等第三方跟踪库对该功能提供支持。