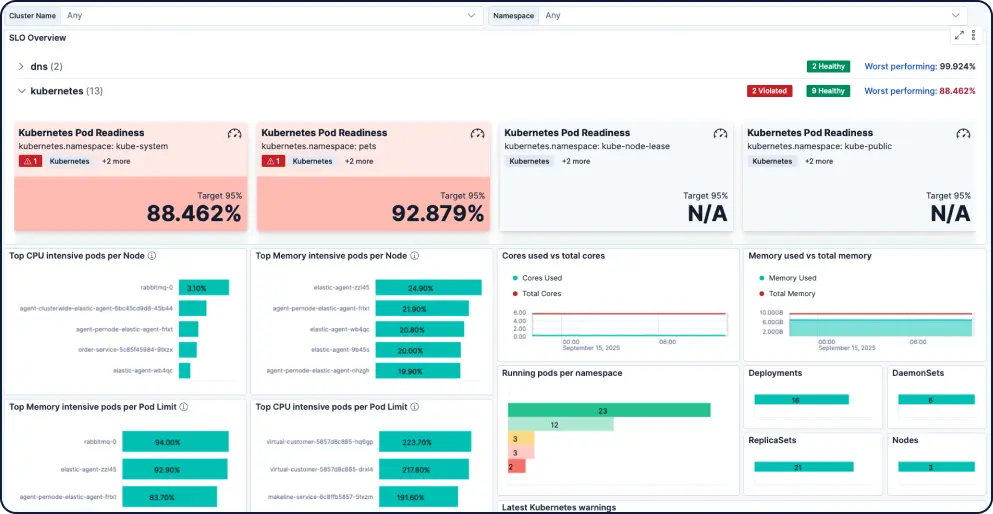
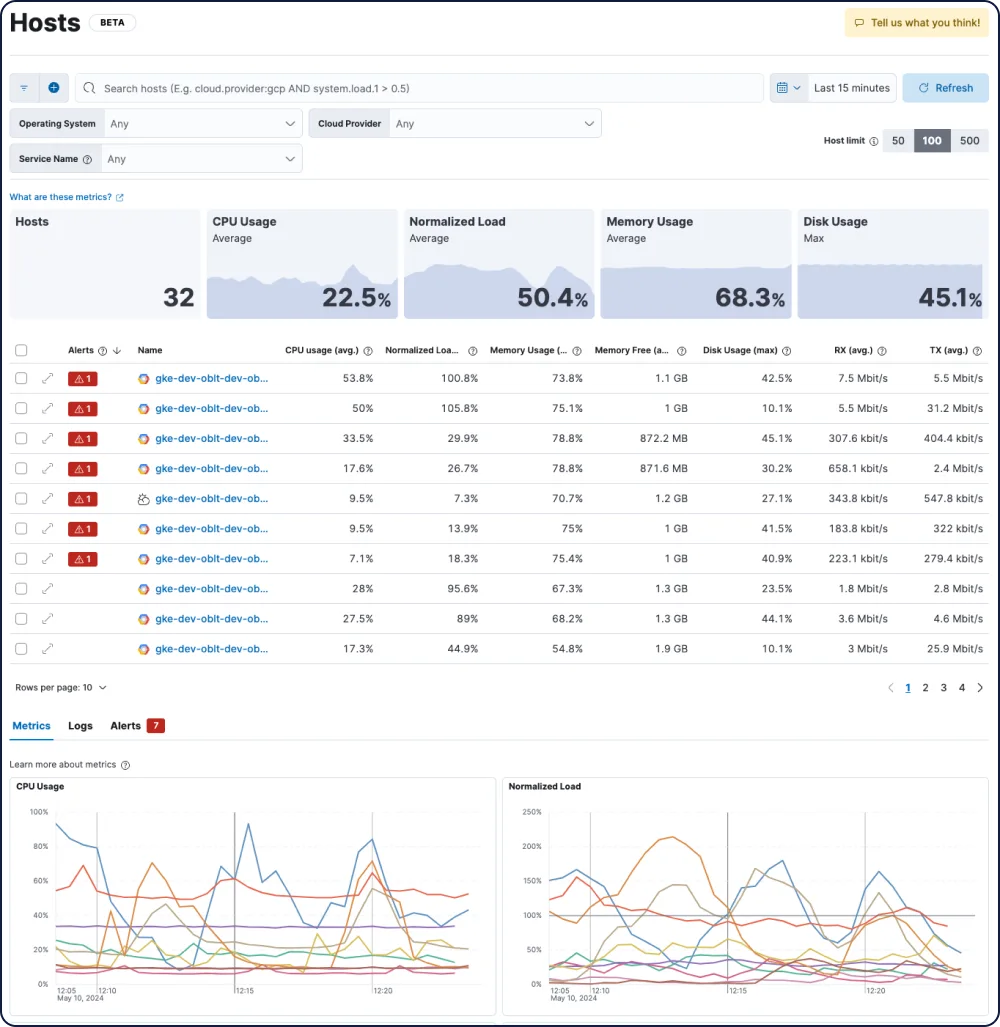
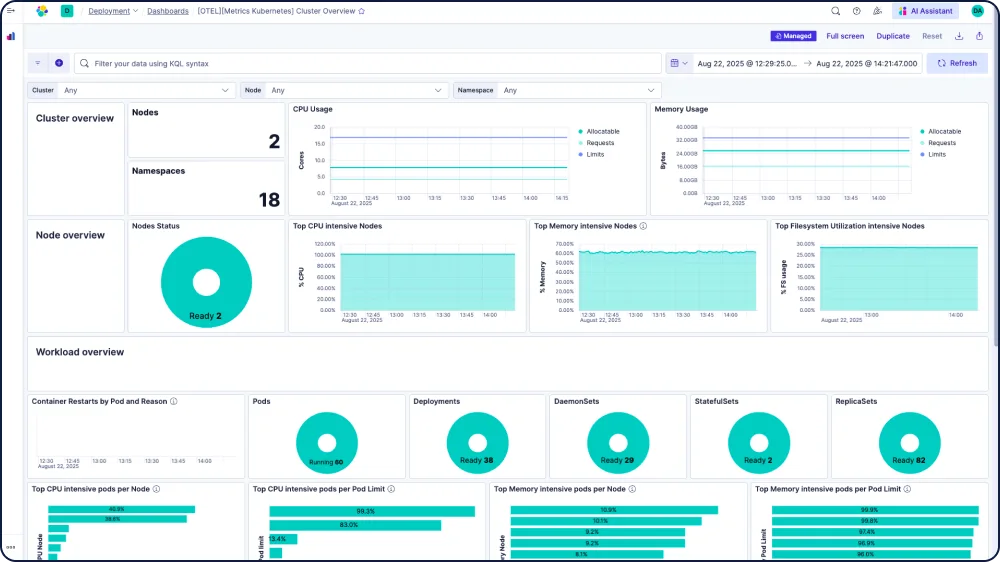
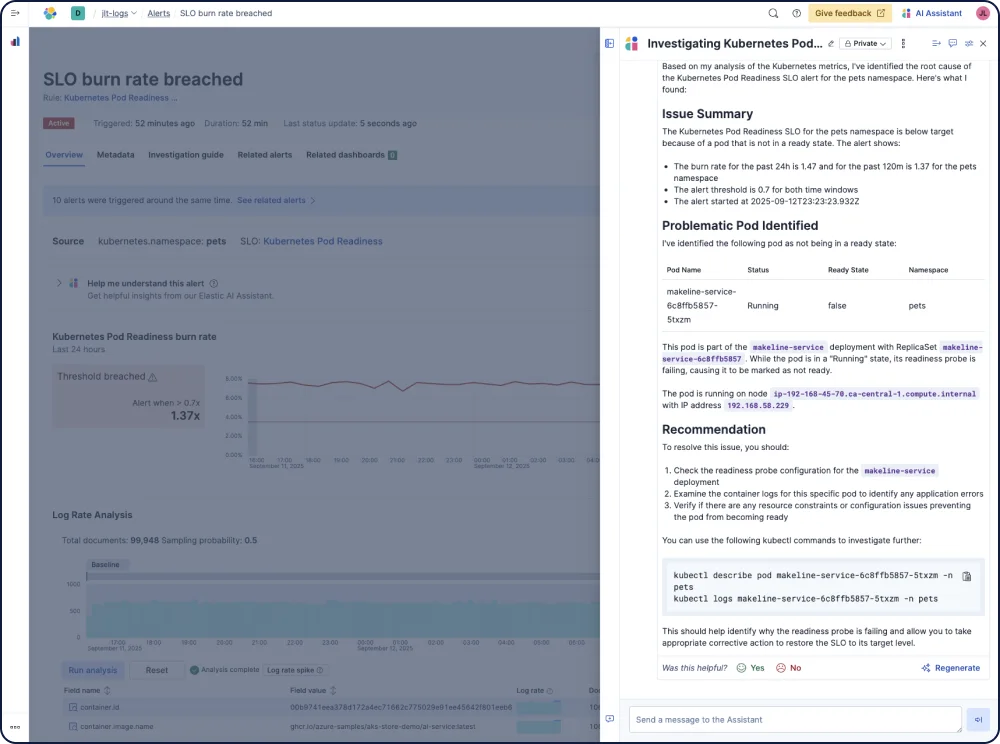
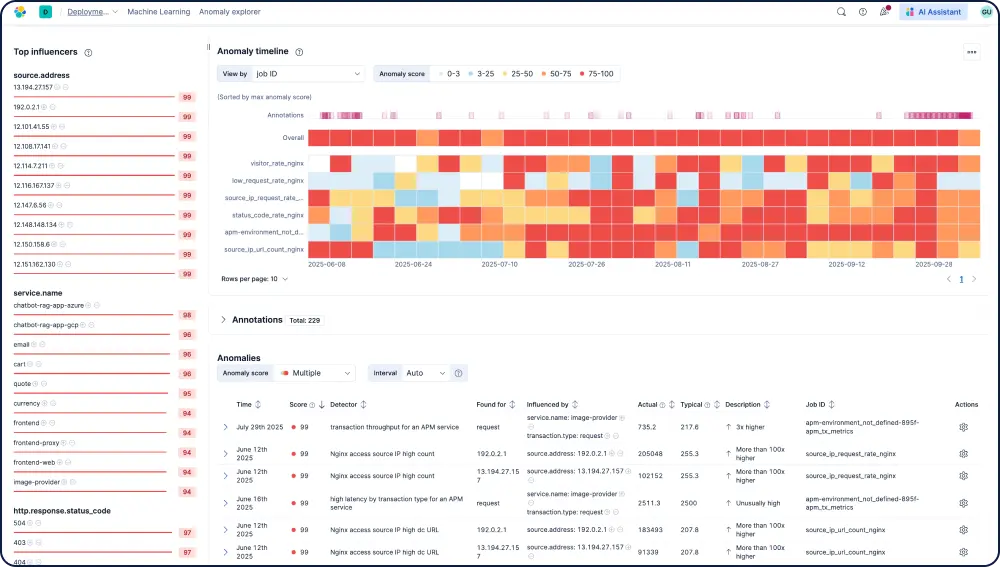
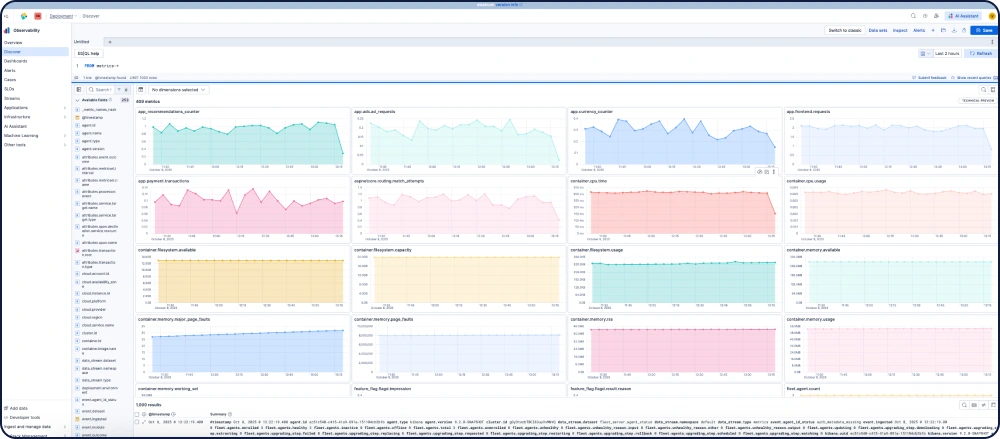


几分钟内构建自定义数据集成
您还可以借助 AI 驱动的自动导入功能,使用示例日志轻松为定制化用例构建自定义集成。Agentic 工作流可处理规范化、管道、映射和模板,您可以根据需要进行检查和调整。结果可完全复用。云遥测变得轻而易举
从关键云提供商服务中轻松流式传输遥测数据,包括直接从云控制台进行安全的无代理收集。


了解像您这样的公司为何选择 Elastic Observability
借助可扩展的日志分析能力,将杂乱数据转化为可操作的洞察。
客户聚焦

Comcast 每天通过 Elastic 摄取 400 TB 的数据,以监测服务并加速根本原因分析,确保一流的客户体验。
客户聚焦

通过使用 Elastic 实施集中式日志记录平台,Discover 将存储成本降低了 50%,并缩短了数据检索时间。
客户聚焦

Informatica 将其整个日志工作负载迁移到 Elastic,涵盖 100 多个应用程序和 300 多个 Kubernetes 集群,从而降低了成本并减少了 MTTR。