Announcing Search AI Lake and Elastic Cloud Serverless to scale low latency search


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
In this blog
Introduces Search AI Lake, a cloud-native architecture for real-time applications, and Elastic Cloud Serverless, an offering built on this architecture
- Search AI Lake is a new architecture that combines the storage capacity of a data lake with the low-latency querying and AI relevance capabilities of Elasticsearch. It decouples compute and storage, scales indexing and querying independently, is optimized for generative AI, and includes powerful query and analytics features, native machine learning, and cross-region capabilities.
- Elastic Cloud Serverless is a fully managed service built on Search AI Lake that simplifies operations by removing the need for cluster management, scaling, and other operational overhead. It offers instant configuration, project-based workflows, guided onboarding, and automatic scaling.
- Product experiences and pricing: Serverless offerings are available for Search, Observability, and Security, with simplified pricing models based on compute resources used for ingest, search, machine learning, data retention, and data egress.
Today we are pleased to announce Search AI Lake and Elastic Cloud Serverless. Search AI Lake is a pioneering cloud native architecture optimized for real-time applications that combines expansive storage capacity with low latency querying and Elasticsearch’s powerful search and AI relevance capabilities. This architecture powers a new Elastic Cloud Serverless offering that removes all operational overhead so you can get started lightning-fast and seamlessly scale your workloads.
The next era of search
For over a decade, Elasticsearch has delivered fast, scalable solutions for even the most complex data. Elastic customers succeed because search is designed to deliver real-time insights from data without a well-defined schema or definable query patterns. While No-SQL databases or other solutions require more well-structured data, schemas, or querying, Elastic makes all your data rapidly searchable by default. The speed of search drives critical outcomes from rapid threat detection, to operational efficiency, and higher user engagement. This makes search the best solution where data is messy and constantly changing, and where users don’t know the exact attributes they want to query but still need to quickly search anything in the data in real time.
It is the reason Elasticsearch is so widely used for real-time analysis on both structured and unstructured data, whether for log analytics, SIEM, or a broad range of Search AI powered applications. It's also why search has been widely adopted for generative AI experiences. Search is critical for efficient encoding, retrieval, and synthesis of vast amounts of data to generate accurate, contextually appropriate responses with large language and other models. We recognize that as AI and real-time workloads scale in production, there’s a need for an architecture that delivers low latency query performance across all data without sacrificing scalability, relevance, or affordability.
We've seen the emergence and evolution of data lakes as an attempt to solve this rapidly growing scale of data by separating compute and storage. But, by design, these architectures are optimized for storage over performance. For example, object storage inherently prioritizes scalability over speed causing unacceptable latency for interactive querying. This makes data lakes practically unusable for real-time applications that need both low latency querying and access to all the data, irrespective of its size and complexity.
The low latency AI driven future needs a new lake architecture.
No compromise: Search AI Lake, a new architecture for real-time, low latency applications
Today we are thrilled to introduce a first of its kind Search AI Lake. It’s a cloud native architecture optimized for real-time, low latency applications including Search, retrieval augmented generation (RAG), Observability, and Security. It brings together the expansive storage capacity of a data lake and the low latency querying, powerful search and AI relevance capabilities of Elasticsearch. This capability is currently available in tech preview.
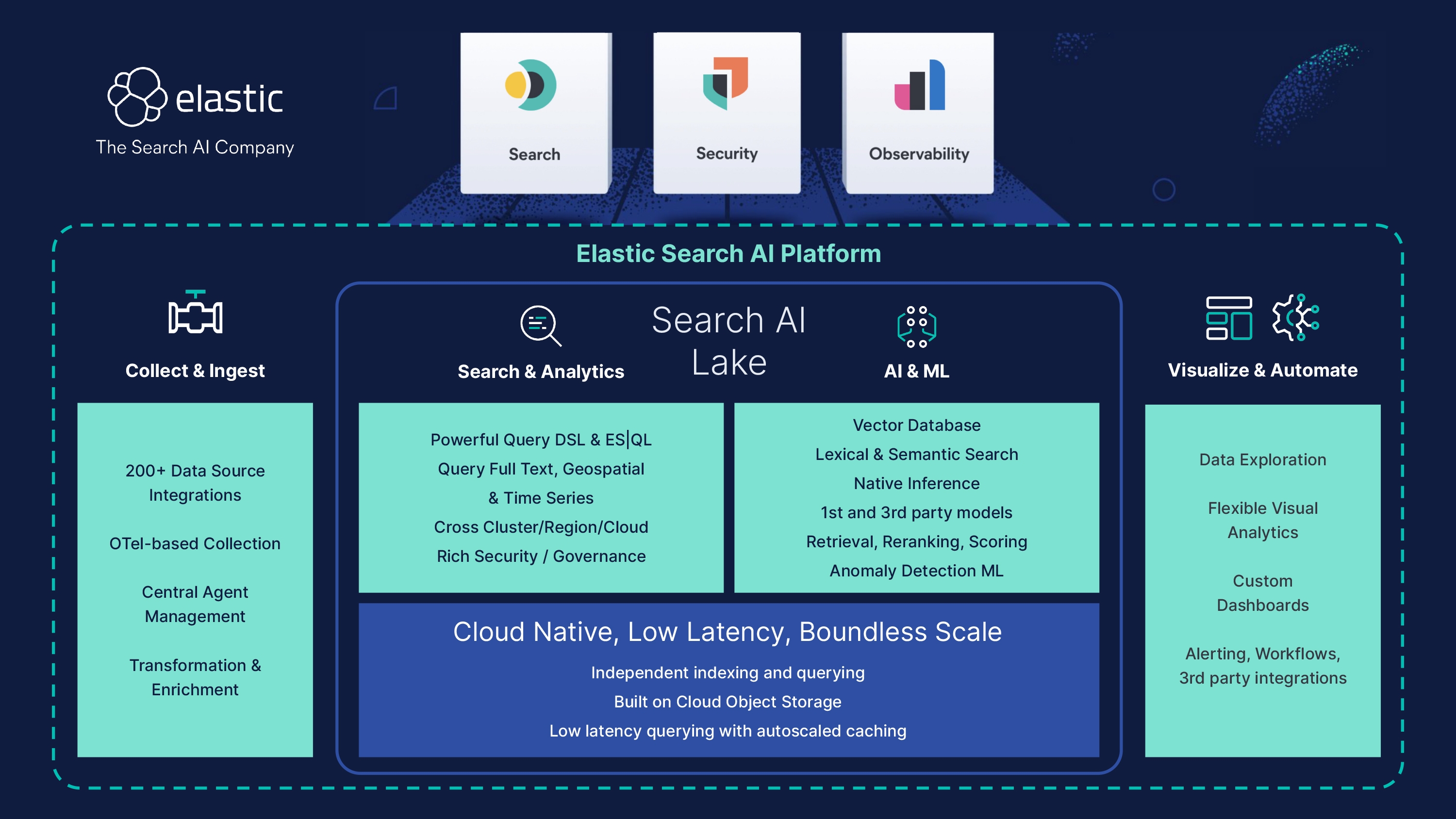
Search AI Lake creates new opportunities to interactively search a practically unlimited amount of data on demand at speed with highly efficient storage costs. For search applications, this makes it seamless to harness large data sets cost-effectively for RAG. For security it means better threat protection by making high volumes of security data readily accessible for investigations and threat hunting. Security teams can enhance anomaly detection with immediate and limitless access to previously siloed data to significantly elevate security posture. SREs get increased insight for resolution — search year-over-year data on application performance without needing to rehydrate, and access high resolution data sets for predictive analysis, trending, and proactive detection. Search AI Lake delivers a host of unique benefits:
Boundless scale, decoupled compute and storage: Fully decoupling storage and compute enables effortless scalability and reliability using native cloud storage, while our dynamic caching supports high throughput, frequent updates, and interactive querying of large data volumes. Utilization of cloud native object storage provides high data durability, while balancing storage costs for any scale. This eliminates the need for replicating indexing operations across multiple servers, cutting indexing costs and reducing data duplication.
- Real time, low latency: Multiple enhancements maintain excellent query performance even when the data is safely persisted on object stores. This includes the introduction of segment-level query parallelization to reduce latency by enabling faster data retrieval and allowing more requests to be processed quicker. Plus better reuse with more efficient caching and optimizing the use of Lucene index formats.
- Independently scale indexing and querying: By separating indexing and search at a low level, the platform can independently and automatically scale to meet the needs of a wide range of workloads.
- GAI optimized: Native inference and vector search: Tailor generative AI experiences to your business using RAG with proprietary data. Leverage a native suite of powerful AI relevance, retrieval, and reranking capabilities, including a native vector database fully integrated into Lucene, open inference APIs, semantic search, and first- and third-party transformer models which work seamlessly with the array of search functionalities.
- Powerful query and analytics: Built in is Elasticsearch’s powerful query language ES|QL to transform, enrich, and simplify investigations with fast concurrent processing irrespective of data source and structure. Full support for precise and efficient full text search and time series analytics to identify patterns in geospatial analysis are also included. Data indexing leverages both “Schema on Write,” for scale and speed and “Schema on Read,” which offers flexibility and faster time to value.
- Native machine learning: Build, deploy, and optimize machine learning directly on all data for superior predictions. For security analysts, this means prebuilt threat detection rules can easily run across historical information even years back. Similarly, run unsupervised models to perform near-real-time anomaly detections retrospectively on data spanning much longer time periods than other SIEM platforms.
- Truly distributed: Cross region, cloud, or hybrid: Query data in the region or data center where it was generated, from one interface. Cross cluster search (CCS) avoids the requirement to centralize or synchronize. It means within seconds of being ingested, any data format is normalized, indexed, and optimized to allow for extremely fast querying and analytics. All while reducing data transfer and storage costs. Full CCS will be available on Search AI Lake in the near future.
Introducing Elastic Cloud Serverless — Launch and scale in no time
Built on the Search AI Lake, Elastic Cloud Serverless delivers hassle-free administration, rapid onboarding, and optimized product experiences all tailored to harness the impressive speed and scale of Search AI Lake. Available in tech preview, serverless projects are completely simplified to remove operational overhead and automatically handle both scaling and management. All operations are managed by Elastic, from monitoring and backup to configuration and sizing. You don't need to think about the underlying cluster, nodes, versions, or scaling — just bring your own data and get started with any of Elastic’s solutions.
Serverless complements existing cloud deployments, offering the choice between greater simplicity with serverless or greater control with the existing Elastic Cloud Hosted. Currently, serverless projects default to AWS (us-east-1) with support for more cloud providers and regions available in the near future. Serverless projects are currently available in tech preview.
Serverless projects feature a new solution-specific pricing model. Simplified pricing makes it easy to understand and forecast spend for Search, Observability, or Security. Credits are unified across deployment options, making it flexible to pay and use Elastic Cloud Hosted or Elastic Cloud Serverless options.
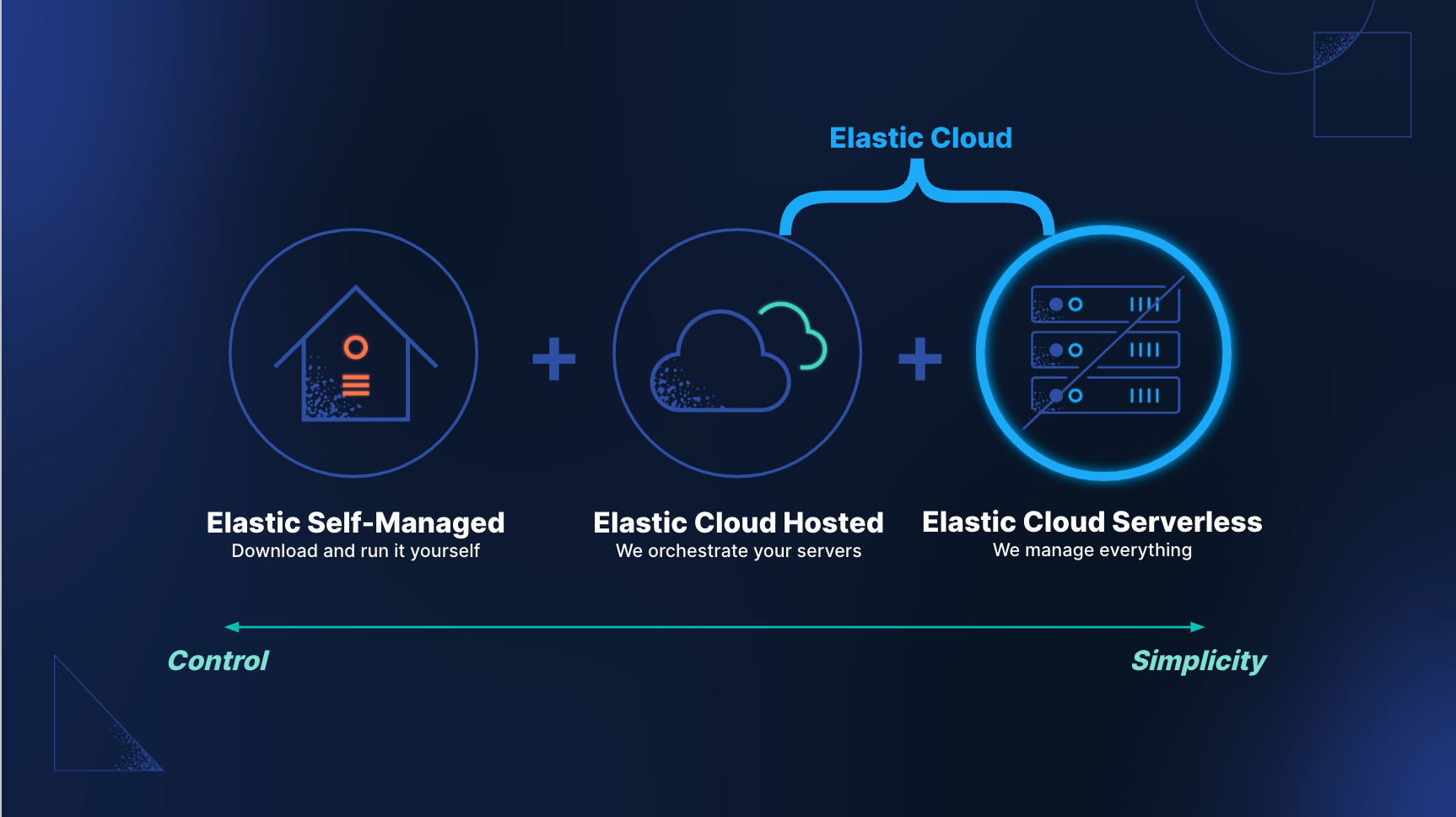
Along with a new product experience and underlying Search AI Lake architecture, serverless projects make getting started even easier.
Instant configuration: Start a new fully configured serverless project in a snap.
Project-based: Use a new workflow to easily create projects optimized to the unique needs of each of your use cases, from vector search and APM to endpoint security and more.
Guided onboarding: Skip the learning curve with dedicated steps that guide you with in-product resources and tools to get results faster.
Hassle-free operations: Free your team from operational responsibility — no need to manage backend infrastructure, do capacity planning, upgrade, or scale data.
- Boundless scale: Serverless allows your workloads to seamlessly scale by automatically responding and adapting to changes in demand, minimizing latency and ensuring the fastest response times.
Streamlined from the ground up: Simplified product experiences, packages, and pricing
Serverless delivers streamlined product experiences and guided onboarding for Search, Observability, and Security, accelerating time to results and optimizing for each use case. New simplified pricing and packages make it easy to manage spend and fully leverage all of Elastic’s benefits. This includes varied new pricing and packaging for Elasticsearch, Elastic Observability, and Elastic Security.
Elasticsearch Serverless enables developers to quickly deliver impactful AI search experiences without worrying about speed or scale. Start fast with hardware optimized projects for general search or vector search and time series coming soon. Build search applications fast with a streamlined developer experience offering extensive inline documentation and code samples to guide search projects. Manage less and develop more with no configuration or management of clusters, shards, versions, or scaling. Accelerate development of generative AI experiences with access to Elastic’s latest AI capabilities like vector search, Elastic Learned Sparse EncodeR (ELSER), semantic search, machine learning (ML), and AI model integration and management.
Be in control with Search AI Lake to balance search performance and storage cost-efficiently. Separation of compute and storage as well as index and querying make independently scaling any workload quick and reliable without any compromise to performance. Even using heavy index-time features for better relevance has no effect on search performance.
Pricing and packaging: Elasticsearch Serverless introduces a single product tier that provides access to all search features and building blocks to programmatically develop search applications. Pricing is simplified and metered on compute resources used for ingest, search, and machine learning, as well as data retention and data out (data egress). See the Elasticsearch Serverless pricing page for more details.
Elastic Observability Serverless enables a hassle-free experience with all the benefits of full-stack observability without the overhead of managing a stack or scaling dynamic workloads. Streamlined workflows and guided onboarding minimize time to insight and make it easy to pivot between signals without losing crucial context. Plus, with over 350+ integrations, a managed intake service, and an OpenTelemetry-first approach, getting your observability data into Elastic couldn’t be simpler.
Search AI Lake enables faster than ever analytics with blazing fast queries and machine learning jobs that deliver insights in minutes even on petabytes of data. With unprecedented speed and scale, you can now analyze all your data, business and operational, to detect issues proactively, accelerate problem resolution, and deliver on business outcomes.
Pricing and packaging: Elastic Observability Serverless introduces a single product tier that provides access to all Observability features. Pricing is simple: you pay for what you ingest and retain. Additional options include synthetic monitoring browser tests priced per test run and lightweight tests, priced per test per region. See the Elastic Observability Serverless pricing page for more details.
Elastic Security Serverless provides security analysts with a new cloud deployment option for their security analytics and SIEM use cases. This new and fully managed cloud offering delivers a curated security solution that can be put to work quickly. Using this Elastic Security deployment eliminates the overhead of managing cloud and SIEM infrastructure and allows security teams to focus on protecting, investigating, and responding to threats within their organizations.
Security analysts can take advantage of Search AI Lake to seamlessly analyze all security-relevant data, including historical data from months or even years ago to provide insights in minutes. Search AI Lake supports threat hunting, automated detections, and AI-driven security analytics features, including Attack Discovery and AI Assistant.
Pricing and packaging: Elastic Security Serverless is available in two tiers of carefully selected features to enable common security operations.
Security Analytics Essentials includes everything you need to operationalize a traditional SIEM in most organizations.
Security Analytics Complete adds advanced security analytics and AI-driven features that many organizations will require when modernizing or replacing legacy SIEMs.
Optional add-ons: Endpoint and cloud protection are optional. Choose one or both options to provide additional protection capabilities over and above the security analytics/SIEM capabilities included with all Elastic Security Serverless projects.
Serverless pricing for Elastic Security is simple: you pay for the data you ingest and retain. See the Elastic Security Serverless pricing page for more details.
Explore all the power of search and AI
The future of low latency applications is here without compromise on speed, scale, or spend. Elastic invites security analysts, SREs, and developers to experience serverless and Search AI Lake to unlock new opportunities with your data. Learn more about the possibilities with serverless, or start your free trial now in technical preview.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print