使用新的冻结层直接搜索 S3
我们非常激动地宣布,在 7.12 版中推出了冻结层的技术预览版,让您能够将计算与存储完全分离,并直接在对象存储(如 AWS S3、Microsoft Azure Storage 和 Google Cloud Storage)中搜索数据。作为我们数据层旅程的下一个重要里程碑,冻结层实现以超低成本长期存储大量数据的同时,还能保持数据处于完全活动和可搜索状态,显著扩展了您的数据覆盖范围。
长期以来,我们一直支持通过多个数据层来进行数据生命周期管理:热层用于提供较高的处理速度,温层则用于降低成本,但性能也较低。两者都利用本地硬件来存储主数据和冗余副本。最近,我们引入了冷层,通过消除在本地存储冗余副本的需要,您可以在相同数量的硬件上最多存储两倍于热层的数据。尽管为了获得最佳性能,主数据仍然存储在本地,但冷层中的索引由存储在对象存储中的可搜索快照提供支持,以实现冗余。

冻结层更进一步,完全不需要在本地存储任何数据。相反,它会使用可搜索快照来直接搜索存储在对象存储中的数据,而无需先将其解冻。本地缓存存储最近查询的数据,以便在进行重复搜索时提供最佳性能。因此,存储成本显著下降:与热层或温层相比,最多可降低 90%;与冷层相比,最多可降低 80%。数据的全自动生命周期现已成为完整体:从热到温到冷,然后再到冻结,同时还可确保以尽可能低的存储成本获得所需的访问和搜索性能。
再也不必因数据增长而放弃有用的数据
无论是用于可观测性、安全还是企业搜索,您的 IT 数据都可能会以指数级的速度不断增长。对组织来说,每天采集和搜索数 TB 的数据是司空见惯的。这些数据不仅关乎日常成功,而且对历史参考也极具价值。不受限制的回顾安全调查、深入研究多年的 APM 数据以识别趋势,或者偶尔发现法规遵从性问题,这些都是长期保留数据且随时可访问的关键用例。然而,如果您没有合适的工具或技术来存储数据,而且还得确保数据易于搜索,那么满足这些用例的需求很快就会变得昂贵无比。
这就是冻结层的作用所在。它为所有这些用例打开了一扇门。现在存储多年的数据可以节省费用,其成本与单单在 S3 或其他对象存储中归档数据相当。关键区别在于,使用冻结层,数据仍然可以在 Elasticsearch 中完全搜索,并且所有从冻结层拉取数据的 Kibana 仪表板都可以正常使用。之前必须手动从存档中查找和拉取数据、恢复数据,然后使其可用于搜索,那样的日子已经一去不复返了。对于必须保留哪些数据和删除哪些数据进行取舍和权衡的日子,也已成为历史。现在有了冻结层,这一切都变得简单而流畅。
运作方式
冻结层利用可搜索快照将计算与存储完全分离。在根据索引生命周期管理 (ILM) 策略将数据从温层或冷层迁移到冻结层时,本地节点上的索引将迁移到 S3 或您选择的对象存储中。冷层将索引迁移到对象存储,但它仍然在本地节点上保留数据的单个完整副本,以确保提供快速而一致的搜索体验。另一方面,冻结层完全消除了本地副本,而是直接搜索对象存储中的数据。它会为最近查询的数据构建本地缓存,以便加快重复搜索的速度,但缓存大小只是存储在冻结层中的完整数据大小的一小部分。
对于典型的 10% 本地缓存大小,这意味着您只需少数几个本地层节点即可处理数百 TB 的冻结层数据。下面简单比较一下:如果 RAM 为 64 GB 的典型温层节点可管理 10 TB,冷层节点将能够处理大约两倍于此的 20 TB,而冻结层节点将跃升至 100 TB。这相当于 1:1500 的 RAM 与存储比率,这还只是一个保守的估计。
价格与性能
如何做出权衡?毫无疑问,性能更重要。这就是我们提供这些不同数据层的原因,这样您就可以灵活地为组织定义适当的 ILM 策略,以准确算出数据应驻留在热层、温层、冷层和冻结层中的时间和数量。存储在冻结层中的数据需要偶尔进行搜索,不需要高于其他层的性能。
此外,我们在优化运行速度较慢的搜索以实现最佳用户体验方面也取得了很大进展。我们在 Elasticsearch 中开发了异步搜索,这让我们可以在 Kibana 中提供自然的体验,让您可以在后台呈现仪表板并稍后检索它们。我们还引入了一系列提高查询效率的方法,以加速运行缓慢的查询,包括跳过与预筛选不匹配的索引、尽可能早地退出搜索、使用 block-max WAND 进行文本搜索等。
由于在 Elasticsearch 中会默认对所有数据编制索引,因此在冻结层中搜索数据特别有效,因为我们可以利用简洁的索引结构在大型数据集中非常快速地返回结果,而无需扫描数据本身。最重要的是,我们在可搜索快照方面做得最好的一件事就是,利用我们在 Lucene 方面深厚的专业知识,只拉取那些真正需要回答查询的索引子集。
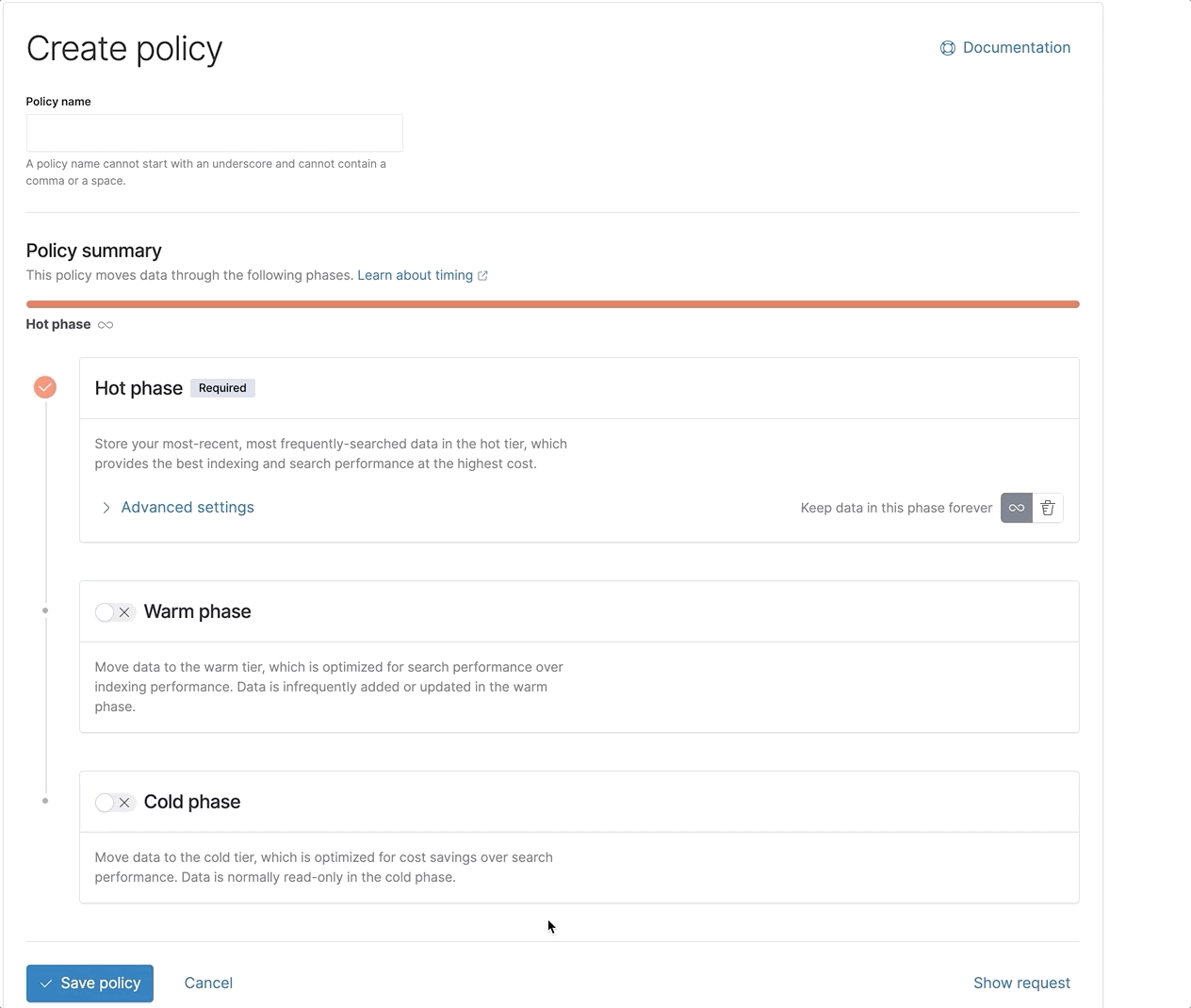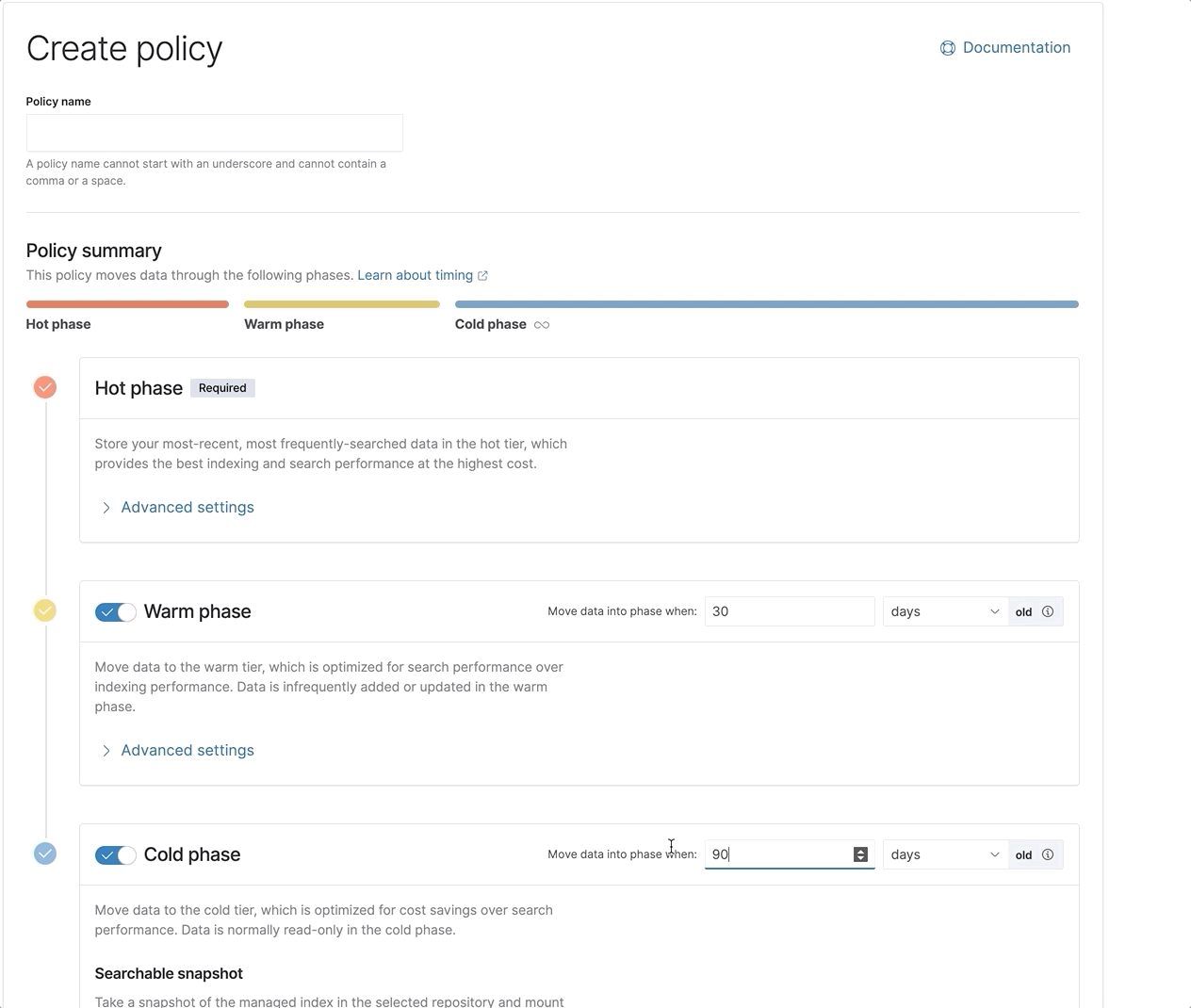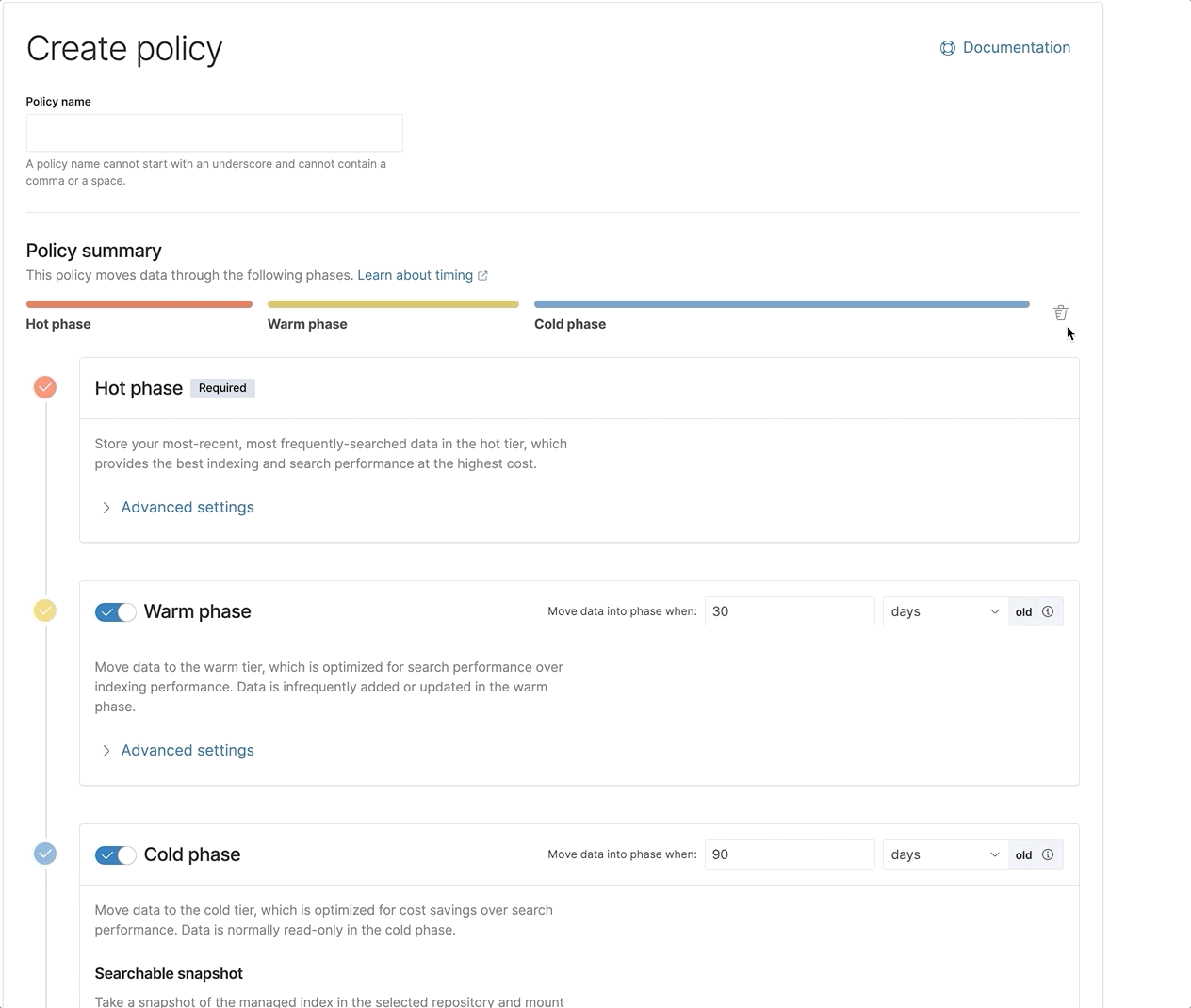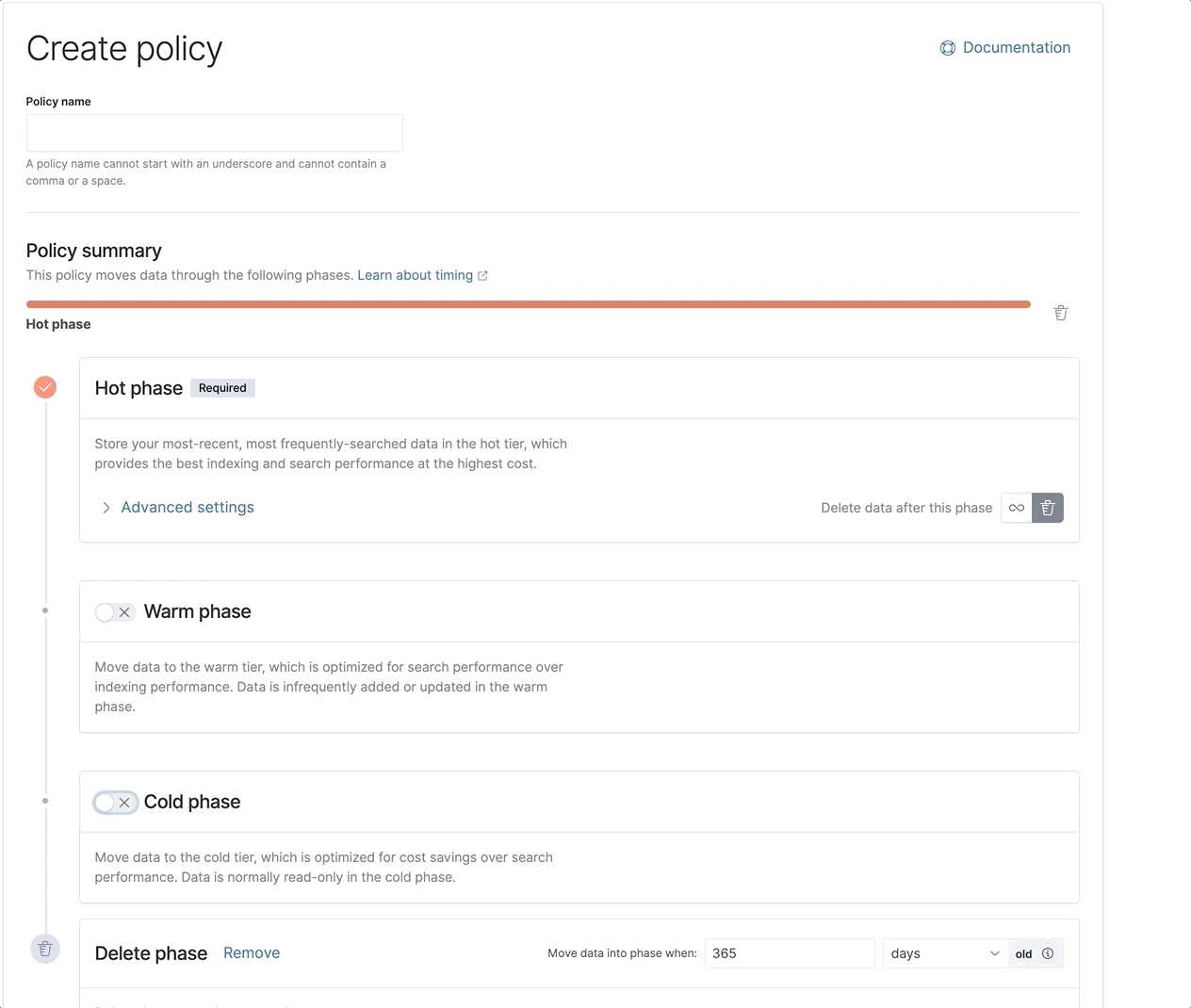
所有这些优化合在一起,可确保在冻结层进行搜索时获得最佳和最快的体验。再加上新近重新设计的 ILM UI,让设置和配置 ILM 策略变得更加容易,现在为您提供了所需的全部工具,可以快速有效地使用 Elastic 的全套数据层。
无论公共还是私有存储,任您选择
在 Elastic,我们的态度一直是为您提供尽可能高的灵活性和最少量的中断。除了我们对 AWS S3、Azure Cloud Storage、Google Cloud Storage 和 MinIO 的官方支持之外,我们现在还发布了一个存储库测试套件,用于测试和验证任何与 S3 兼容的对象存储,以与可搜索快照、冷层和冻结层配合使用。
该测试套件可作为易于使用的 API 提供,允许您针对自己的 S3 兼容对象存储运行一系列快速测试。如果测试成功,您则可以使用它来存储和搜索快照,并将其作为冷层和冻结层的对象存储。因为这是一个验证测试套件,所以请务必注意,这并不意味着我们正式支持任何通过验证的 S3 兼容存储。如果发现任何问题,请在受支持的 S3 设备上重现相关问题,以便我们进行解决。
时间线
Elastic 7.12 版中引入冻结层的技术预览版。热层、温层和冷层均已正式发布,支持冷层和冻结层的底层可搜索快照功能也是如此。从 7.12 版开始,Elastic Cloud 中也会提供冻结层,一个更简单、开箱即用的滑块即将上线。
即刻开始使用
要开始使用冻结层,既可在 Elastic Cloud 上快速部署一个集群,也可安装最新版本的 Elastic Stack。已经在运行 Elasticsearch?只需将集群升级到 7.12 版,即可开始试用。如果您想在 Elastic Cloud 上试用一下,请在 Elastic Cloud 文档中查看详细信息。冻结滑块一旦上线,就不再需要这些步骤了。如果您想了解有关冻结层的更多信息,请阅读可搜索快照博客、可搜索快照产品文档或数据层产品文档。
本文所描述的任何特性或功能的发布及上市时间均由 Elastic 自行决定。当前尚未发布的任何特性或功能可能无法按时提供或根本不会提供。