¿Qué es el machine learning supervisado?
Definición de machine learning supervisado
El machine learning supervisado, o aprendizaje supervisado, es un tipo de machine learning (ML) que se utiliza en aplicaciones de inteligencia artificial (IA) para entrenar algoritmos con sets de datos etiquetados. Al alimentar con grandes sets de datos etiquetados a un algoritmo, el machine learning supervisado le “enseña” el algoritmo a predecir los resultados con precisión. Es el tipo de machine learning que más se usa.
El machine learning supervisado, como todo machine learning, funciona a través del reconocimiento de patrones. Mediante el análisis de un conjunto específico de datos etiquetados, un algoritmo puede detectar patrones y generar predicciones basadas en esos patrones derivados cuando se le consulta. Para llegar a una etapa de predicción precisa, el proceso del machine learning supervisado requiere la recopilación de datos y, a continuación, el etiquetado. Luego, el algoritmo se entrena en estos datos etiquetados para clasificar datos o predecir resultados con precisión. La calidad de los resultados está directamente relacionada con la calidad de los datos: los buenos datos se traducen en buenas predicciones.
Los ejemplos de machine learning supervisado van desde el reconocimiento de imágenes y objetos hasta el análisis del sentimiento del cliente, la detección de spam y el análisis predictivo. Como resultado, el machine learning supervisado se utiliza en varias industrias como la salud, las finanzas y el comercio electrónico para ayudar a optimizar la toma de decisiones e impulsar la innovación.
¿Cómo funciona el machine learning supervisado?
El machine learning supervisado funciona al recopilar y etiquetar datos, luego al entrenar modelos e iterar el proceso con nuevos sets de datos. Es un proceso de dos pasos: definir el problema que el modelo pretende resolver, seguido de la recopilación de datos.
- Paso 1: Definir el problema que el modelo pretende resolver. ¿El modelo se usa para hacer predicciones relacionadas con el negocio, automatizar la detección de spam, analizar el sentimiento del cliente o identificar imágenes? Esto determina qué datos serán necesarios, lo que lleva al siguiente paso en el flujo de trabajo.
- Paso 2: Recopilar los datos. Una vez que se etiquetan los datos, se introducen en el algoritmo en entrenamiento. A continuación, el modelo se prueba, se refina y se despliega para realizar tareas de clasificación o regresión.
Recopilación de datos y etiquetado
La recopilación de datos es el primer paso en el machine learning supervisado. Los datos pueden provenir de varias fuentes, como bases de datos, sensores o interacciones de usuarios. Se procesa previamente para garantizar la consistencia y la relevancia. Una vez recopilado, a este gran set de datos se le asignan etiquetas. Cada elemento de los datos de entrada recibe una etiqueta correspondiente. Si bien la clasificación de datos puede llevar mucho tiempo y ser costosa, es necesario enseñar los patrones del modelo para que pueda hacer predicciones. La calidad y la precisión de estas etiquetas influyen directamente en la capacidad del modelo para aprender y hacer predicciones relevantes. Tus resultados serán tan buenos como los datos que ingreses.
Entrenamiento de modelos
Durante el entrenamiento, el algoritmo analiza los datos de entrada y aprende a mapearlos a las etiquetas de salida correctas. Este proceso implica ajustar los parámetros del modelo para minimizar la diferencia entre los resultados previstos y las etiquetas reales. El modelo mejora su precisión al aprender de los errores que comete durante el entrenamiento. Una vez que se entrena el modelo, se somete a evaluación. Se utilizan datos de validación para determinar la precisión de un modelo. Dependiendo de los resultados, se ajusta según sea necesario.
En teoría, cuantos más datos absorbe un modelo, más patrones aprende y más precisas se vuelven sus predicciones. El aprendizaje continuo es fundamental en el machine learning: el rendimiento de los modelos mejora a medida que siguen aprendiendo de sets de datos etiquetados.
Una vez que se despliega, el machine learning supervisado puede realizar dos tipos de tareas: clasificación y regresión.
La clasificación se basa en un algoritmo para asignar una clase a un punto o conjunto de datos discreto determinado. En otras palabras, distingue las categorías de datos. En los problemas de clasificación, el límite de decisión establece las clases.
La regresión se basa en un algoritmo para comprender la relación entre las variables de datos continuas dependientes e independientes. En los problemas de regresión, el límite de decisión establece la línea de mejor ajuste o cercanía probabilística.
Algoritmos de machine learning supervisados
En el machine learning supervisado se usan diferentes algoritmos y técnicas para tareas de clasificación y regresión, que van desde la clasificación de texto hasta las predicciones estadísticas.
Árbol de decisiones
Un algoritmo de árbol de decisiones es un algoritmo de aprendizaje supervisado no paramétrico, compuesto por un nodo raíz, ramas, nodos internos y nodos hoja. La entrada viaja desde el nodo raíz, a través de las ramas, hasta los nodos internos, donde el algoritmo procesa la entrada y toma una decisión, lo que da como resultado los nodos hoja. Los árboles de decisión se pueden usar tanto para tareas de clasificación como de regresión. Son herramientas útiles de minería de datos y descubrimiento de conocimientos: permiten al usuario realizar un seguimiento de por qué se produjo un resultado o por qué se tomó una decisión. Sin embargo, los árboles de decisión son propensos al sobreajuste; tienen dificultades para manejar una mayor complejidad. Por esta razón, los árboles de decisión más pequeños son más efectivos.
Regresión lineal
Los algoritmos de regresión lineal predicen el valor de una variable (la variable dependiente) en función del valor de otra (la variable independiente). Las predicciones se basan en el principio de una relación lineal entre variables, o que existe una conexión “en línea recta” entre variables continuas como el salario, el precio o la edad. Los modelos de regresión lineal se usan para realizar predicciones en los campos de la biología, las ciencias sociales, ambientales y del comportamiento, y los negocios.
Redes neuronales
Las redes neuronales usan nodos formados por entradas, pesos, umbrales (a veces denominados sesgos) y resultados. Estos nodos se superponen en una estructura de capas de entrada, ocultas y de salida que se asemejan al cerebro humano, de ahí lo de neuronal. Las redes neuronales, consideradas algoritmos de aprendizaje profundo, crean una base de conocimientos a partir de datos de entrenamiento etiquetados. Por lo tanto, pueden identificar patrones y relaciones complejas en los datos. Son un sistema adaptativo y son capaces de “aprender” de sus errores para la mejora continua. Las redes neuronales se pueden usar en aplicaciones de reconocimiento de imágenes y procesamiento del lenguaje.
Bosque aleatorio
Los algoritmos de bosque aleatorio son una colección (o bosque) de algoritmos de árbol de decisiones no correlacionados programados para producir un único resultado a partir de varios resultados. Los parámetros del algoritmo de bosque aleatorio incluyen el tamaño del nodo, el número de árboles y el número de características. Estos hiperparámetros se establecen antes del entrenamiento. Su dependencia de los métodos de bagging y aleatoriedad de características garantiza la variabilidad de los datos en el proceso de decisión y, en última instancia, produce predicciones más precisas. Esta es la diferencia clave entre los árboles de decisión y los bosques aleatorios. Como resultado, los algoritmos de bosques aleatorios permiten una mayor flexibilidad: el bagging de características ayuda a estimar los valores faltantes, lo que garantiza la precisión cuando faltan ciertos puntos de datos.
Máquina de vectores de soporte (SVM)
Las máquinas de vectores de soporte (SVM) se usan principalmente para la clasificación de datos y, a veces, para la regresión de datos. Para las aplicaciones de clasificación, una SVM crea un límite de decisión que te ayuda a distinguir o clasificar puntos de datos, como frutas frente a verduras, o mamíferos frente a reptiles. La SVM se puede usar para el reconocimiento de imágenes o la clasificación de textos.
Naïve Bayes
Naïve Bayes es un algoritmo probabilístico de clasificación basado en el teorema de Bayes. Supone que las características de un set de datos son independientes y que cada característica, o predictor, tiene un peso uniforme en el resultado. Esta suposición se denomina “ingenua” porque a menudo puede refutarse en un escenario del mundo real. Por ejemplo, la siguiente palabra de una frase depende de la que la precede. A pesar de ello, la probabilidad única de cada variable hace que los algoritmos Naive Bayes sean computacionalmente eficientes, en especial para tareas de clasificación de textos y filtrado de spam.
K-nearest neighbors
K-nearest neighbor, también conocido como KNN, es un algoritmo de aprendizaje supervisado que utiliza la proximidad de las variables para predecir resultados. En otras palabras, funciona partiendo de la suposición de que existen puntos de datos similares cerca uno del otro. Una vez entrenado con datos etiquetados, el algoritmo calcula la distancia entre una consulta y los datos que ha memorizado (su base de conocimientos) y formula una predicción. KNN puede usar varios métodos de cálculo de distancia (Manhattan, Euclidean, Minkowski, Hamming) para establecer el límite de decisión en el que se basa la predicción. KNN se usa para tareas de clasificación y regresión, incluida la clasificación de relevancia, la búsqueda de similitud, el reconocimiento de patrones y los motores de recomendación de productos.
Desafíos y limitaciones del machine learning supervisado
Aunque el machine learning supervisado permite un alto nivel de precisión en las predicciones, es una técnica de machine learning que consume muchos recursos. Depende de costosos procesos de etiquetado de datos, requiere grandes sets de datos y, como resultado, es vulnerable al sobreajuste.
- El costo de etiquetar los datos: uno de los principales desafíos del aprendizaje supervisado es la necesidad de sets de datos grandes y etiquetados con precisión. La precisión de estas etiquetas es directamente proporcional a la precisión de un modelo, por lo que la calidad es primordial. Se trata de un esfuerzo que requiere mucho tiempo, que a veces requiere conocimientos especializados (según los datos y el uso previsto del modelo), lo que, a su vez, puede resultar muy caro. En campos como la atención médica o las finanzas, donde los datos son sensibles y complejos, obtener sets de datos etiquetados de alta calidad puede ser especialmente difícil.
- Necesidad de grandes sets de datos: la dependencia de un modelo de aprendizaje supervisado de grandes sets de datos puede ser un desafío importante por dos razones: recopilar y etiquetar grandes cantidades de datos de calidad requiere muchos recursos, y encontrar el equilibrio adecuado entre demasiados datos y suficientes datos buenos es complicado. Los sets de datos grandes son necesarios para un entrenamiento eficaz, pero los sets de datos demasiado amplios conducen a un sobreajuste.
- Sobreajuste: el sobreajuste es una preocupación común en el aprendizaje supervisado. Se produce cuando un modelo está expuesto a demasiados datos de entrenamiento y captura información o detalles irrelevantes: existe el exceso de datos. Esto afecta la calidad de sus predicciones y lleva a un rendimiento deficiente en datos nuevos e invisibles. Para contrarrestar o evitar el sobreajuste, los ingenieros utilizan técnicas como la validación cruzada, la regularización y la poda.
El procesamiento de datos previo es el núcleo de estos desafíos. Puede llevar mucho tiempo y ser costoso, pero con las herramientas adecuadas, puede mitigar los desafíos de costo, calidad y sobreajuste.
Machine learning supervisado frente a no supervisado
El machine learning puede ser supervisado, no supervisado y semisupervisado. Cada método de entrenamiento de datos logra resultados diferentes y se usa en contextos diferentes. El machine learning supervisado requiere sets de datos etiquetados para entrenar datos, pero mejora su precisión gracias a sets de datos grandes y de alta calidad.
Por el contrario, el machine learning no supervisado usa sets de datos sin etiquetar para entrenar un modelo para las predicciones. El modelo identifica patrones entre puntos de datos sin etiquetar por sí solo, lo que a veces genera menos precisión. El aprendizaje no supervisado se emplea a menudo para tareas de agrupación, asociación o reducción de dimensionalidad.
Machine learning semisupervisado
El machine learning semisupervisado es una combinación de técnicas de aprendizaje supervisado y no supervisado. Los algoritmos de aprendizaje semisupervisado se entrenan con pequeñas cantidades de datos etiquetados y grandes cantidades de datos sin etiquetar. Esto logra mejores resultados que los modelos de aprendizaje no supervisado con menos ejemplos etiquetados. El aprendizaje semisupervisado es un método híbrido que puede ser especialmente útil en los casos en que etiquetar grandes sets de datos es poco práctico o costoso.
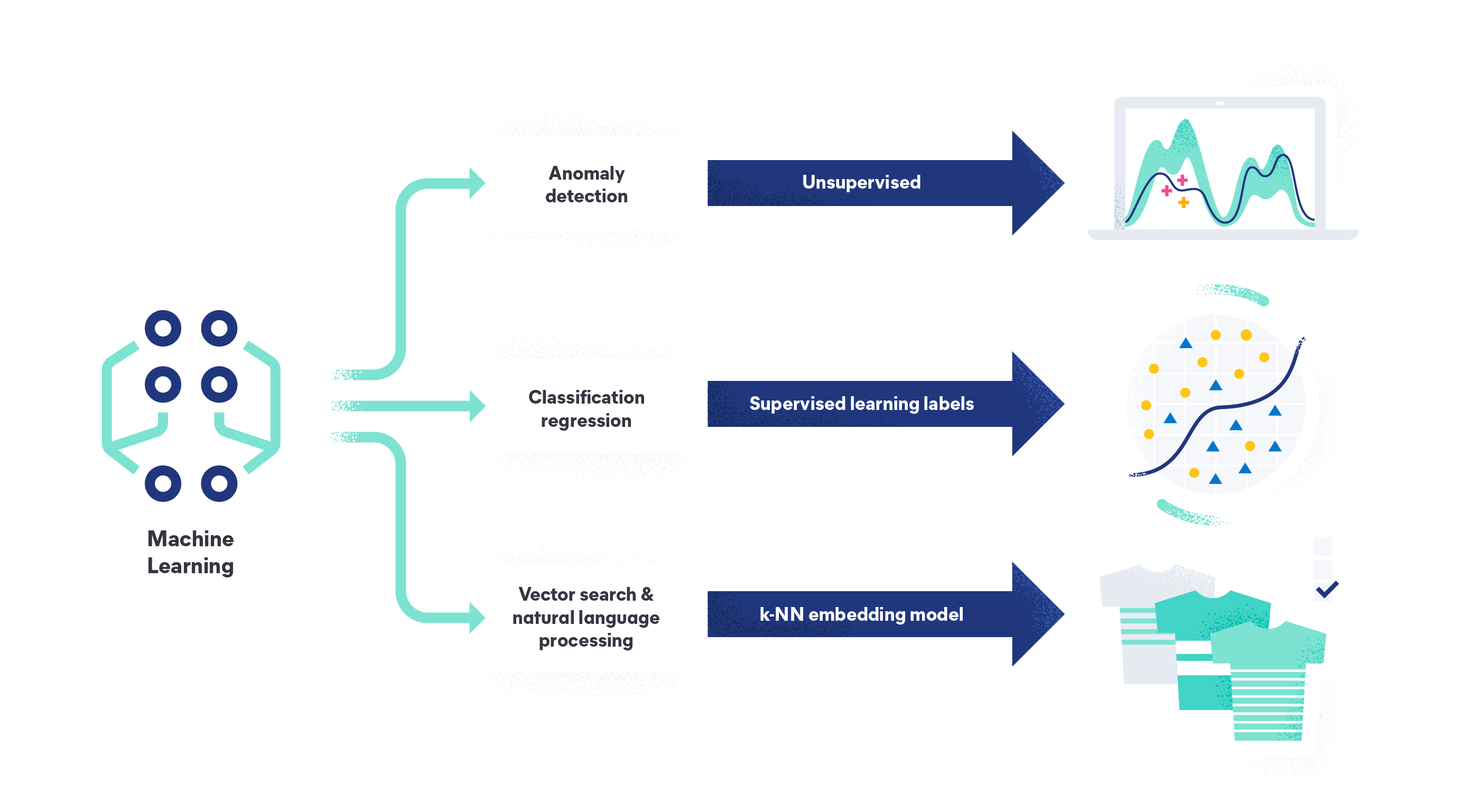
Comprender la diferencia entre estos métodos de machine learning es crucial para elegir la solución adecuada para la tarea en cuestión.
Machine learning simplificado con Elastic
El machine learning comienza con los datos, ahí es donde entra Elastic.
Con el machine learning de Elastic, puedes analizar tus datos para encontrar anomalías, realizar análisis de marcos de datos y analizar datos de lenguaje natural. El machine learning de Elastic elimina la necesidad de un equipo de ciencia de datos, el diseño de una arquitectura de sistema desde cero o el traslado de datos a un entorno de terceros para el entrenamiento de modelos. Como plataforma de IA de búsqueda, nuestras capacidades te permiten ingestar, comprender y crear modelos con tus datos, o confiar en nuestro modelo no supervisado listo para usar para la detección de anomalías y valores atípicos.
Obtén más información sobre cómo Elastic puede ayudarte a enfrentar tus desafíos de datos con machine learning.